
Qwen Image 2512 LoRA Inferenz: pipeline-ausgerichtete, training-übereinstimmende AI Toolkit-Generationen in ComfyUI#
Dieses produktionsreife RunComfy-Workflow wendet ein AI Toolkit-trainiertes LoRA auf Qwen Image 2512 in ComfyUI an, mit einem Fokus auf training-übereinstimmendes Verhalten. Es dreht sich um RC Qwen Image 2512 (RCQwenImage2512)—einen von RunComfy entwickelten, quelloffenen benutzerdefinierten Knoten (source), der eine Qwen-native Inferenz-Pipeline ausführt (anstatt eines generischen Sampler-Graphs) und Ihren Adapter über lora_path und lora_scale lädt.
Warum Qwen Image 2512 LoRA Inferenz oft anders in ComfyUI aussieht#
AI Toolkit-Vorschauen für Qwen Image 2512 werden durch eine modellspezifische Pipeline erzeugt, einschließlich Qwens "true CFG"-Führungsverhalten und den Standards, die diese Pipeline für Konditionierung und Sampling verwendet. Wenn Sie denselben Job als Standard-ComfyUI-Sampler-Graph neu erstellen, können sich die Führungssemantik und der LoRA-Patchpunkt verschieben - daher kann "gleicher Prompt + gleicher Seed + gleiche Schritte" immer noch zu einem anders aussehenden Ergebnis führen. In der Praxis sind viele Berichte über "mein LoRA stimmt nicht mit dem Training überein" Pipeline-Unstimmigkeiten und nicht ein fehlender Parameter.
RCQwenImage2512 hält die Inferenz ausgerichtet, indem es die Qwen Image 2512 Pipeline innerhalb des Knotens umhüllt und das LoRA in dieser Pipeline über lora_path und lora_scale anwendet. Pipeline-Quelle: `src/pipelines/qwen_image.py`.
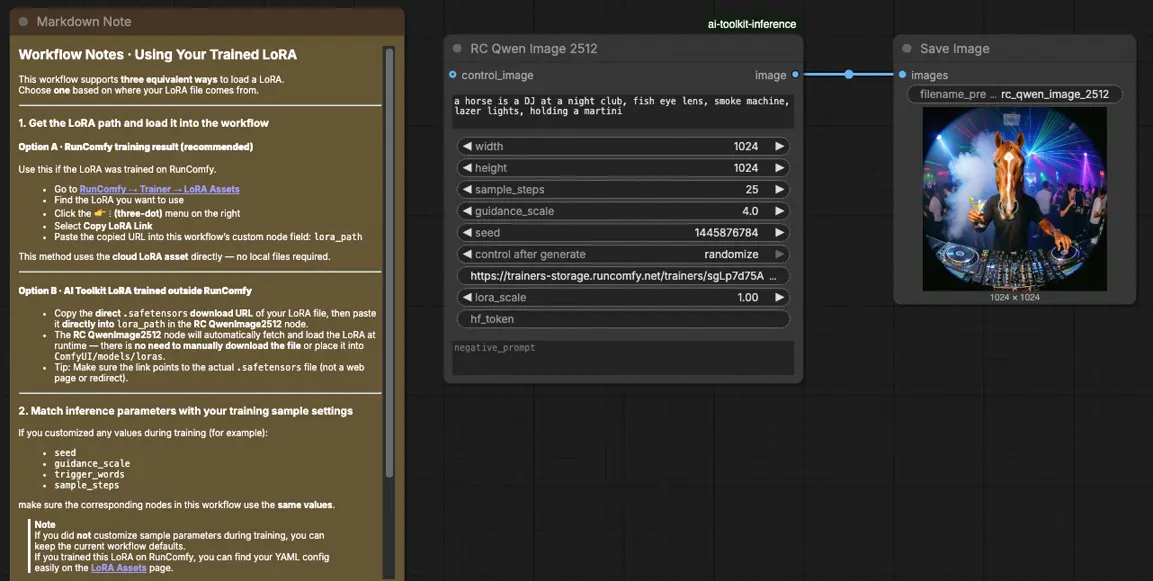
Wie man den Qwen Image 2512 LoRA Inferenz-Workflow verwendet#
Schritt 1: Öffnen Sie den Workflow#
Starten Sie den Cloud-Workflow in ComfyUI.
Schritt 2: Importieren Sie Ihr LoRA (2 Optionen)#
- Option A (RunComfy-Trainingsergebnis): RunComfy → Trainer → LoRA Assets → finden Sie Ihr LoRA → ⋮ → LoRA-Link kopieren

- Option B (AI Toolkit LoRA außerhalb von RunComfy trainiert): Kopieren Sie einen direkten
.safetensors-Download-Link für Ihr LoRA und fügen Sie diese URL inlora_pathein (kein Download inComfyUI/models/loraserforderlich)
Schritt 3: Konfigurieren Sie den RCQwenImage2512 benutzerdefinierten Knoten für Qwen Image 2512 LoRA Inferenz#
Fügen Sie Ihren LoRA-Link in lora_path auf RC Qwen Image 2512 (RCQwenImage2512) ein.

Stellen Sie dann die restlichen Knotenparameter ein (beginnen Sie mit den Werten, die Sie für die Vorschau/Sample-Erzeugung während des Trainings verwendet haben):
prompt: Ihr positiver Prompt (einschließlich aller Trigger-Tokens, die Ihr LoRA erwartet)negative_prompt: optional; lassen Sie es leer, wenn Sie keine Negativen in Ihren Vorschauen verwendet habenwidth/height: Ausgaberesolution (Vielfache von 32 werden für diese Pipeline-Familie empfohlen)sample_steps: Inferenz-Schritte; spiegeln Sie Ihre Vorschau-Schrittzahl wider, bevor Sie abstimmen (25 ist eine häufige Basislinie)guidance_scale: Führungsstärke (Qwen verwendet eine "true CFG"-Skala, also verwenden Sie zuerst Ihren Vorschauwert wieder)seed: Sperren Sie den Seed, während Sie die Ausrichtung validieren, indem Sie control_after_generate auf 'fixed' setzen, dann variieren Sie ihn für neue Sampleslora_scale: LoRA-Stärke; beginnen Sie nahe Ihrem Vorschauwert und passen Sie in kleinen Schritten an
Dies ist ein Text-zu-Bild-Workflow, daher müssen Sie kein Eingabebild bereitstellen.
Trainingsausrichtungs-Hinweis: Wenn Sie das Sampling während des Trainings angepasst haben, öffnen Sie Ihr AI Toolkit-Trainings-YAML und spiegeln Sie width, height, sample_steps, guidance_scale, seed und lora_scale wider. Wenn Sie auf RunComfy trainiert haben, öffnen Sie Trainer → LoRA Assets → Konfiguration und kopieren Sie die Vorschau/Sample-Werte in RCQwenImage2512, bevor Sie iterieren.

Schritt 4: Führen Sie Qwen Image 2512 LoRA Inferenz durch#
Klicken Sie auf Queue/Run. Der SaveImage-Knoten speichert das erzeugte Bild in Ihrem Standard-ComfyUI-Ausgabeverzeichnis.
Fehlersuche bei Qwen Image 2512 LoRA Inferenz#
Der benutzerdefinierte Knoten RC Qwen Image 2512 (RCQwenImage2512) von RunComfy ist darauf ausgelegt, die Inferenz pipeline-ausgerichtet mit Qwen Image 2512 Vorschau-Stil-Sampling zu halten, indem er:
- eine Qwen-native Inferenz-Pipeline innerhalb des Knotens ausführt (nicht ein generischer Sampler-Graph), und
- das LoRA über
lora_path+lora_scaleinnerhalb dieser Pipeline injiziert (konsistenter Patchpunkt).
(1)Qwen-Image Loras funktionieren nicht in comfyui#
Warum das passiert
Benutzer berichteten, dass AI Toolkit-trainierte Qwen-Image LoRAs in ComfyUI nicht angewendet werden können, da die LoRA-State-Dict-Schlüsselpräfixe nicht mit dem übereinstimmen, was der ComfyUI-Seiten-Loader/Inferenzpfad erwartet (sodass der Adapter "still" geladen wird, aber die Qwen-Transformator-Module nicht tatsächlich gepatcht werden).
Wie man es behebt (benutzerverifizierte Optionen)
- Verwenden Sie RCQwenImage2512 für Pipeline-Level-LoRA-Injektion: Laden Sie den Adapter nur über
lora_path+lora_scaleauf RCQwenImage2512 (vermeiden Sie es, zusätzliche LoRA-Loader-Knoten oben zu stapeln, während Sie Fehler beheben). Dies hält den LoRA-Patchpunkt ausgerichtet mit der Qwen-Pipeline, die von Vorschau-Stil-Sampling verwendet wird. - Wenn Sie einen Nicht-RC-Inferenzanbieter/Loader-Pfad verwenden müssen: Eine benutzerberichtete Lösung besteht darin, die LoRA-Schlüssel umzubenennen, indem das erste Segment des LoRA-Schlüsselpräfixes von
diffusion_model→transformerersetzt wird, sodass die Gewichte auf die erwarteten Qwen-Transformator-Module abgebildet werden (siehe das Problem für den genauen Kontext und warum dies erforderlich ist).
(2)Patch für Absturz bei Verwendung von inference_lora_path mit qwen image (ermöglicht die Erstellung von Samples mit Turbo LoRA)#
Warum das passiert
Einige Benutzer stoßen auf einen Absturz, wenn sie versuchen, ein Inferenz-LoRA für Qwen (einschließlich Qwen-Image-2512) über den inference_lora_path-Fluss von AI Toolkit zu laden. Dies ist kein "prompt/CFG/seed"-Problem—es ist ein Inferenz-Ladepfad-Problem.
Wie man es behebt (benutzerverifiziert)
- Wenden Sie den Patch an / aktualisieren Sie auf eine Version, die den im Problem beschriebenen Patch enthält. Der Autor des Problems berichtet, dass der Patch den Absturz beim Laden eines Inferenz-LoRA für Qwen behebt (siehe das Problem für die genaue Änderung und den Konfigurationskontext).
- Speziell für ComfyUI-Inferenz: bevorzugen Sie RCQwenImage2512 und laden Sie den Adapter über
lora_path/lora_scaleinnerhalb des RC-Knotens. Dies vermeidet die Abhängigkeit von externen Inferenz-LoRA-Laderouten und hält die Pipeline konsistent mit Vorschau-Stil-Sampling.
(3)Verwendung von sageattention 2 qwen-image in comfyui zeigt schwarze Bilder aufgrund von NaNs (d.h. schwarze Bilder)#
Warum das passiert
Benutzer berichteten, dass das Ausführen von Qwen Image in ComfyUI mit SageAttention NaNs erzeugen kann, die zu schwarzen Bildern führen. Dies kann wie "mein LoRA ist kaputt" aussehen, aber tatsächlich erzeugt das Aufmerksamkeits-Backend ungültige Werte—die Pipeline-Ausführung schlägt fehl, bevor Sie das LoRA-Verhalten sinnvoll bewerten können.
Wie man es behebt (benutzerverifiziert)
- Verwenden Sie nicht
--use-sage-attentionfür Qwen Image, wenn es NaNs/schwarze Ausgaben verursacht. Validieren Sie zuerst eine saubere Basislinie (nicht-schwarze Ausgaben), dann bewerten Sie den LoRA-Einfluss. - Wenn Sie SageAttention-Geschwindigkeitsvorteile benötigen: Behebung der schwarzen Qwen-Ausgabe durch Erzwingen eines CUDA-Backend-Pfads. In der Praxis bedeutet dies oft die Verwendung eines Workflow-Level-Patches (z.B. eines "Patch Sage Attention"-Knotens) und die Auswahl einer CUDA-Backend-Variante, die den kaputten Triton-Pfad für die betroffene GPU/Architektur vermeidet.
- Nachdem Sie stabile (nicht-schwarze) Basisausgaben haben, führen Sie die Qwen Image 2512 Inferenz durch RCQwenImage2512 aus, sodass die Pipeline + LoRA-Injektionspunkt vorschau-ausgerichtet bleibt, während Sie
width/height/sample_steps/guidance_scale/seed/lora_scaleanpassen.
Führen Sie jetzt die Qwen Image 2512 LoRA Inferenz aus#
Öffnen Sie den geteilten Workflow, fügen Sie Ihre LoRA-URL in lora_path ein, passen Sie Ihre Vorschau-Sampling-Werte an und führen Sie RCQwenImage2512 für training-übereinstimmende Qwen Image 2512-Generationen in ComfyUI aus.
