
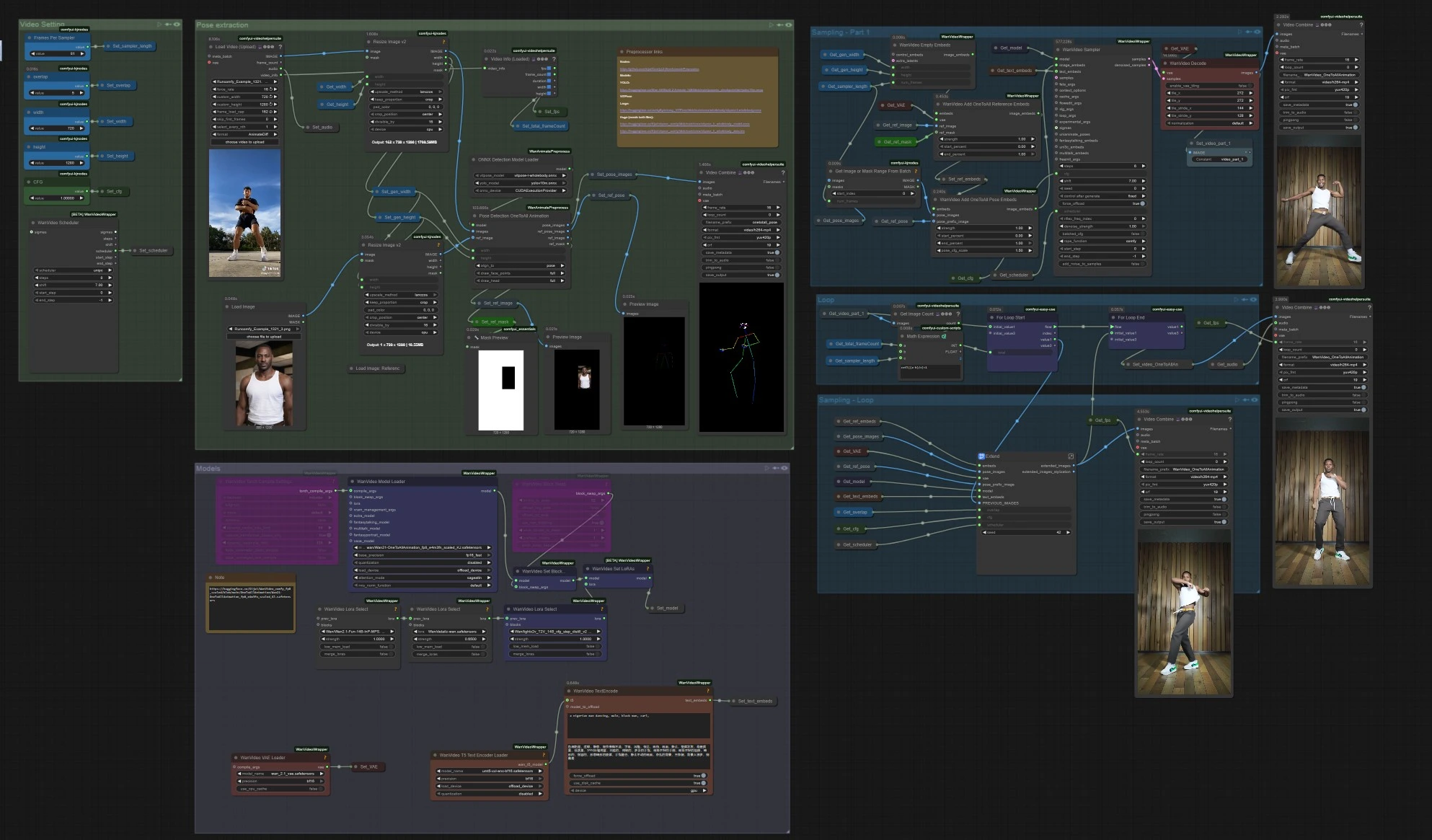
One to All Animation: Langform-, pose-abgestimmtes Charaktervideo in ComfyUI#
Dieser One to All Animation-Workflow verwandelt einen kurzen Referenzclip in ein erweitertes, hochauflösendes Video, während Bewegung, Pose-Abstimmung und Charakteridentität über die gesamte Sequenz hinweg konsistent bleiben. Er basiert auf der Wan 2.1 Videogenerierung mit Ganzkörper-Pose-Anleitung und einem Sliding-Window-Erweiterungstool und ist ideal für Tanz, Performance Capture und narrative Aufnahmen, bei denen Sie möchten, dass ein einzelner Look einer komplexen Bewegung folgt.
Wenn Sie ein Ersteller sind, der stabile, posegesteuerte Ergebnisse ohne Zittern oder Identitätsdrift benötigt, bietet Ihnen One to All Animation einen klaren Weg: Extrahieren Sie Posen aus Ihrem Quellvideo, verschmelzen Sie sie mit einem Referenzbild und einer Maske, generieren Sie das erste Segment und erweitern Sie dieses Segment wiederholt, bis die volle Länge abgedeckt ist.
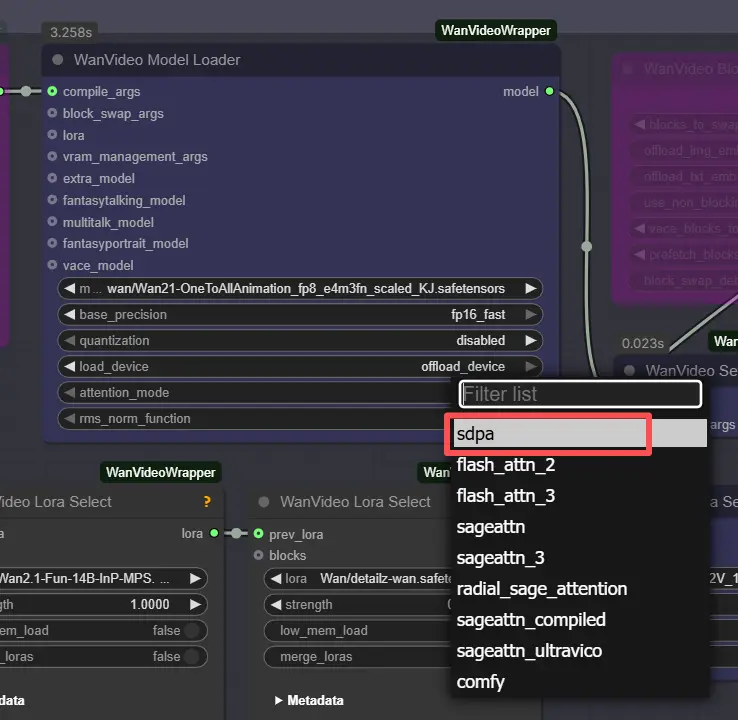
Hinweis: Auf 2XL- oder 3XL-Maschinen setzen Sie bitte den attention_mode auf "sdpa" im WanVideo Model Loader-Knoten. Das Standard-Segeattn-Backend kann Kompatibilitätsprobleme bei High-End-GPUs verursachen.
Wichtige Modelle im Comfyui One to All Animation-Workflow#
- Wan 2.1 OneToAllAnimation (Videogenerierung). Das Haupt-Diffusionsmodell, das für hochwertige Bewegung und Identitätsbewahrung verwendet wird. Beispiel-Gewichte: Wan21-OneToAllAnimation fp8 skaliert von Kijai. Model card
- UMT5-XXL-Text-Encoder. Kodiert Eingabeaufforderungen für die Wan-Videogenerierung. Model card
- ViTPose Whole-Body (Pose-Schätzung). Produziert dichte Skelett-Schlüsselpunkte, die die Pose-Treue antreiben. Siehe das ViTPose-Paper und die Ganzkörper-ONNX-Gewichte. Paper • Weights
- YOLOv10m-Detektor (Personen-/Regions-Erkennung). Beschleunigt die robuste Pose-Extraktion, indem der Schätzer auf das Subjekt fokussiert wird. Paper • Weights
- Optionales ViTPose-H-Alternativmodell. Hochkapazitäts-Ganzkörpermodell für herausfordernde Bewegungen. Weights und data file
- Optionale LoRA-Pakete für Stil/Steuerung. Beispiel-LoRAs, die in diesem Graphen verwendet werden, umfassen Wan2.1-Fun-InP-MPS, detailz-wan und lightx2v T2V; sie verfeinern Textur, Detail oder In-Place-Steuerung ohne erneutes Training.
So verwenden Sie den Comfyui One to All Animation-Workflow#
Gesamtfluss
- Der Workflow liest Ihr Referenzbewegungsvideo, extrahiert Ganzkörper-Posen, bereitet One to All Animation-Einbettungen vor, die Pose und eine Charakterreferenz verschmelzen, generiert einen Anfangsclip und erweitert diesen Clip dann mit Überlappung wiederholt, bis die gesamte Dauer abgedeckt ist. Schließlich werden Audio zusammengeführt und ein vollständiges Video exportiert.
Pose-Extraktion
- Laden Sie Ihre Bewegungsquelle in
VHS_LoadVideo(#454). Frames werden mitImageResizeKJv2(#131) in der Größe angepasst, um das Generierungsseitenverhältnis für stabiles Sampling zu erreichen. OnnxDetectionModelLoader(#128) lädt YOLOv10m und ViTPose-Ganzkörper;PoseDetectionOneToAllAnimation(#141) gibt dann eine pro-Frame-Pose-Karte, ein Referenz-Pose-Bild und eine saubere Referenzmaske aus.- Verwenden Sie
PreviewImage(#145), um schnell zu überprüfen, dass Posen das Subjekt verfolgen. Klare, kontrastreiche Aufnahmen mit minimaler Bewegungsunschärfe liefern die besten One to All Animation-Ergebnisse.
Modelle
WanVideoModelLoader(#22) lädt Wan 2.1 OneToAllAnimation-Gewichte;WanVideoVAELoader(#38) stellt das zugehörige VAE bereit. Bei Bedarf stapeln Sie Stil-/Steuerungs-LoRAs überWanVideoLoraSelect(#452, #451, #56) und wenden Sie sie mitWanVideoSetLoRAs(#80) an.- Texteingabeaufforderungen werden von
WanVideoTextEncode(#16) kodiert. Schreiben Sie eine prägnante, identitätsfokussierte positive Eingabeaufforderung und eine starke Bereinigung-negative, um den Charakter im Modell zu halten.
Videoeinstellungen
- Breite und Höhe werden in der Gruppe „Video Setting“ festgelegt und zur Pose-Extraktion und -Generierung propagiert, damit alles ausgerichtet bleibt.
Hinweis: ⚠️ Auflösungsgrenze : Dieser Workflow ist fest auf 720×1280 (720p) eingestellt. Die Verwendung einer anderen Auflösung führt zu Dimensionsfehlanpassungsfehlern, es sei denn, der Workflow wird manuell umkonfiguriert.
WanVideoScheduler(#231) und dieCFG-Steuerung wählen den Rauschzeitplan und die Eingabeaufforderungsstärke. Höhere CFG passt sich stärker der Eingabeaufforderung an; niedrigere Werte verfolgen die Pose etwas lockerer, können jedoch Artefakte reduzieren.VHS_VideoInfoLoaded(#440) liest die fps und Bildanzahl des Quellclips, die die Schleife verwendet, um zu bestimmen, wie viele One to All Animation-Fenster benötigt werden.
Sampling – Teil 1
WanVideoEmptyEmbeds(#99) erstellt einen Container für die Konditionierung in der Zielgröße.WanVideoAddOneToAllReferenceEmbeds(#105) injiziert Ihr Referenzbild und seineref_mask, um Identität zu sperren und Bereiche wie Hintergrund oder Kleidung zu bewahren oder zu ignorieren.WanVideoAddOneToAllPoseEmbeds(#98) fügt die extrahiertenpose_imagesundpose_prefix_imagehinzu, sodass das erste generierte Segment der Quellbewegung ab Bild eins folgt.WanVideoSampler(#27) erzeugt den ersten latenten Clip, der vonWanVideoDecode(#28) dekodiert und optional mitVHS_VideoCombine(#139) in der Vorschau betrachtet oder gespeichert wird. Dies ist das Ausgangssegment, das erweitert werden soll.
Schleife
VHS_GetImageCount(#327) undMathExpression|pysssss(#332) berechnen, wie viele Erweiterungspässe basierend auf der Gesamtanzahl der Frames und der pro-Pass-Länge erforderlich sind.easy forLoopStart(#329) startet die Erweiterungspässe unter Verwendung des anfänglichen Clips als Ausgangskontext.
Sampling – Schleife
Extend(#263) ist das Herzstück der langwierigen One to All Animation. Es berechnet die Konditionierung mitWanVideoAddOneToAllExtendEmbeds(innerhalb des Untergraphen) neu, um die Kontinuität von den vorherigen Latents zu erhalten, und sampelt und dekodiert dann das nächste Fenster.ImageBatchExtendWithOverlap(innerhalb vonExtend) mischt jedes neue Fenster auf das angesammelte Video unter Verwendung eineroverlap-Region, glättet Grenzen und reduziert zeitliche Nähte.easy forLoopEnd(#334) fügt jeden erweiterten Block hinzu. Das Ergebnis wird überSet_video_OneToAllAnimation(#386) zur Export gespeichert.
Export
VHS_VideoCombine(#344) schreibt das endgültige Video unter Verwendung der Quell-fps und optionalem Audio vonVHS_LoadVideo. Wenn Sie ein stilles Ergebnis bevorzugen, lassen Sie den Audioeingang hier weg oder stummschalten Sie ihn.
Wichtige Knoten im Comfyui One to All Animation-Workflow#
PoseDetectionOneToAllAnimation (#141)
- Erkennt das Subjekt und schätzt Ganzkörper-Schlüsselstellen, die die Pose-Anleitung steuern. Unterstützt von YOLOv10 und ViTPose, ist es robust gegen schnelle Bewegungen und teilweise Verdeckung. Wenn Ihr Subjekt driftet oder Mehrpersonenszenen den Detektor verwirren, beschneiden Sie Ihre Eingabe oder wechseln Sie zu den oben verlinkten ViTPose-H-Gewichten mit höherer Kapazität.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Verschmilzt ein Referenzbild und
ref_maskin die Konditionierung, sodass Identität, Outfit oder geschützte Bereiche über die Frames hinweg stabil bleiben. Enge Masken bewahren Gesichter und Haare; breitere Masken können Hintergründe sperren. Wenn Sie das Aussehen ändern, tauschen Sie die Referenz aus und behalten Sie die gleiche Bewegung.
WanVideoAddOneToAllPoseEmbeds (#98)
- Bindet Posenkarten und eine Präfixpose an die One to All Animation-Einbettungen. Für strengere Choreografie erhöhen Sie den Pose-Einfluss; für freiere Interpretation reduzieren Sie ihn leicht. Kombinieren Sie mit LoRAs, wenn Sie eine konsistente Textur wünschen, während Sie dennoch die Bewegung anpassen.
WanVideoSampler (#27)
- Der Haupt-Videosampler, der Einbettungen und Text in den ersten latenten Clip verwandelt.
cfgsteuert die Eingabeaufforderungsbindung, undschedulertauscht Qualität, Geschwindigkeit und Stabilität aus. Verwenden Sie dieselbe Samplerfamilie hier und in der Schleife, um Flimmern zu vermeiden.
Extend (#263)
- Ein kompakter Untergraph, der Sliding-Window-Erweiterung mit Überlappung durchführt. Die
overlap-Einstellung ist das zentrale Steuerelement: Mehr Überlappung mischt Übergänge glatter auf Kosten zusätzlicher Berechnung; weniger Überlappung ist schneller, kann jedoch Nähte offenbaren. Dieser Knoten verwendet auch vorherige Latents erneut, um Szene und Charakter über Fenster hinweg kohärent zu halten.
VHS_VideoCombine (#344)
- Finale Muxing und Speicherung. Stellen Sie die
frame_ratevon den erkannten fps ein, um die Bewegungstiming treu zu Ihrem Original zu halten. Sie können in der Nachbearbeitung trimmen oder loopen, aber das Exportieren im Originalrhythmus bewahrt das Gefühl der Performance.
Optionale Extras#
- Installationshinweise für Vorprozessoren. Die Pose-Extraktor-Knoten stammen aus dem Community-Add-on. Siehe das Repo für Einrichtung und ONNX-Platzierung. ComfyUI-WanAnimatePreprocess
- Bevorzugen Sie ViTPose-H für schwierige Bewegungen. Wechseln Sie zu ViTPose-H, wenn Hände/Füße schnell oder teilweise verdeckt sind; laden Sie sowohl das Modell als auch seine Datendatei von den oben verlinkten Seiten herunter.
- Feinabstimmung für lange Läufe. Wenn Sie VRAM-Grenzen erreichen, reduzieren Sie die Fensterlänge pro Pass oder vereinfachen Sie LoRA-Stapel. Die Überlappung kann dann ein wenig nach oben geschoben werden, um Übergänge sauber zu halten.
- Starke Identitätsbewahrung. Verwenden Sie eine hochwertige, frontale Referenz und malen Sie eine präzise
ref_mask, um Gesicht, Haare oder Outfit zu schützen. Dies ist entscheidend für lange One to All Animation-Sequenzen. - Sauberes Filmmaterial hilft. Hohe Verschlussgeschwindigkeit, gleichmäßige Beleuchtung und ein klarer Vordergrund verbessern die Pose-Verfolgung erheblich und reduzieren das Zittern in One to All Animation-Ausgaben.
- Video-Dienstprogramme. Der Exporteur und die Hilfsknoten stammen aus der Video Helper Suite. Wenn Sie zusätzliche Kontrolle über Codecs oder Vorschauen wünschen, lesen Sie die Projektdokumentation. Video Helper Suite
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Innovate Futures @ Benji für das One to All Animation-Workflow-Tutorial und ssj9596 für das One-to-All Animation-Projekt für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Docs / Release Notes: Patreon post
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.

