






Nunchaku Qwen Bild Mehrbildbearbeitung und Compositing für ComfyUI#
Nunchaku Qwen Bild ist ein promptgesteuerter, mehrbildbearbeitender und compositing Workflow für ComfyUI. Er akzeptiert bis zu drei Referenzbilder, lässt Sie festlegen, wie diese gemischt oder transformiert werden sollen, und erzeugt ein kohäsives Ergebnis, das durch natürliche Sprache geleitet wird. Typische Anwendungsfälle umfassen das Zusammenführen von Motiven, das Ersetzen von Hintergründen oder das Übertragen von Stilen und Details von einem Bild auf ein anderes.
Dieser Workflow, der auf der Qwen-Bildfamilie basiert, bietet Künstlern, Designern und Kreativen präzise Kontrolle und bleibt dabei schnell und vorhersagbar. Er umfasst auch eine Einzelbild-Bearbeitungsroute und eine reine Text-zu-Bild-Route, sodass Sie innerhalb einer Nunchaku Qwen Bild-Pipeline generieren, verfeinern und komponieren können.
Hinweis: Bitte wählen Sie Maschinentypen im Bereich von Medium bis 2XLarge. Die Verwendung von 2XLarge Plus oder 3XLarge Maschinentypen wird nicht unterstützt und führt zu einem Laufversagen.
Schlüsselmodelle im ComfyUI Nunchaku Qwen Bild-Workflow#
- Nunchaku Qwen Bild Edit 2509. Bearbeitungsgesteuerte Diffusion/DiT-Gewichte, optimiert für promptgesteuerte Bildbearbeitung und Attributübertragung. Stark bei lokalisierten Bearbeitungen, Objektwechsel und Hintergrundänderungen. Model card
- Nunchaku Qwen Bild (Basis). Basisgenerator, der vom Text-zu-Bild-Zweig für kreative Synthese ohne Quellfoto verwendet wird. Model card
- Qwen2.5-VL 7B Text-Encoder. Multimodales Sprachmodell, das Prompts interpretiert und sie mit visuellen Merkmalen für Bearbeitung und Erzeugung in Einklang bringt. Model page
- Qwen Bild VAE. Variational Autoencoder, der Quellbilder in Latents kodiert und finale Ergebnisse mit treuen Farben und Details dekodiert. Assets
Verwendung des ComfyUI Nunchaku Qwen Bild-Workflows#
Dieser Graph enthält drei unabhängige Routen, die dieselbe visuelle Sprache und Abtastlogik teilen. Verwenden Sie einen Zweig nach dem anderen, je nachdem, ob Sie mehrere Bilder bearbeiten, ein einzelnes Bild verfeinern oder aus Text generieren.
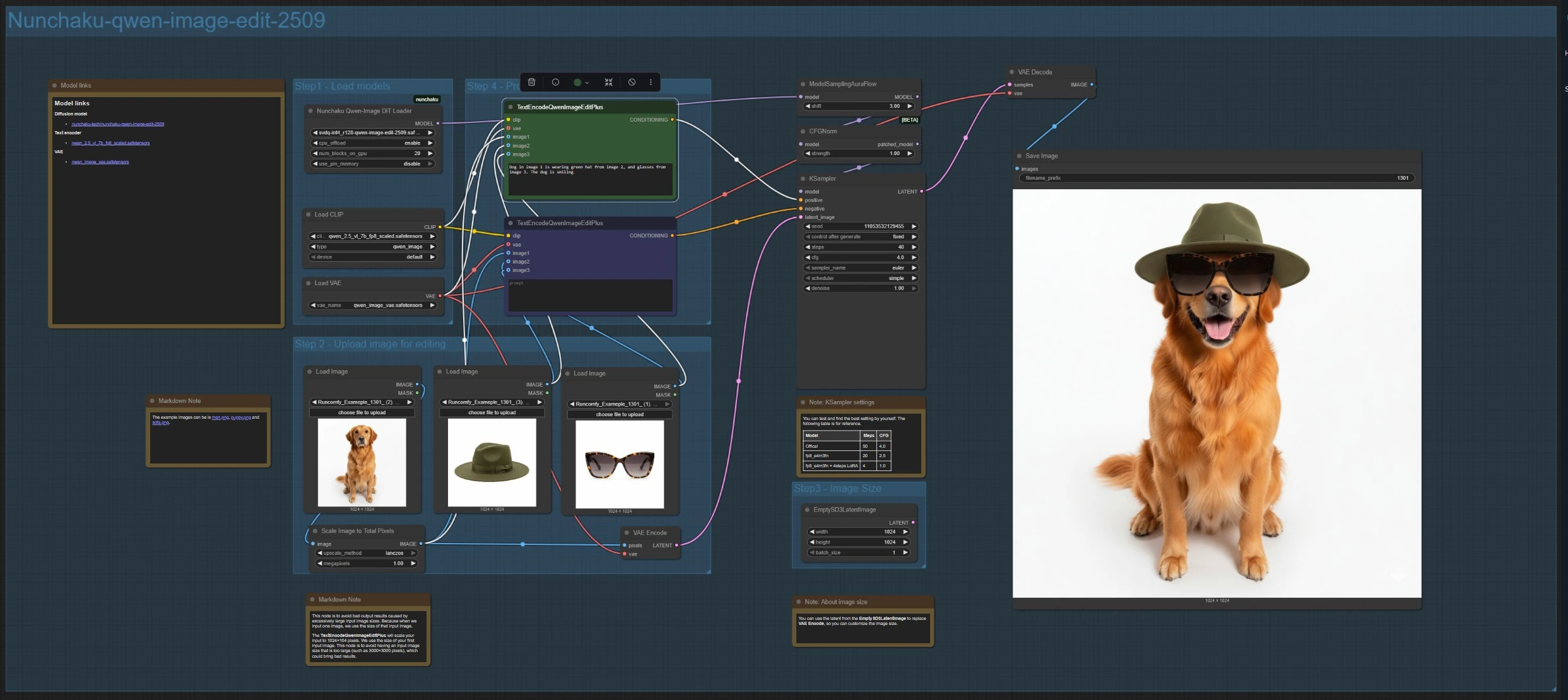
Nunchaku-qwen-image-edit-2509 (Mehrbildbearbeitung und Compositing)#
Dieser Zweig lädt das Bearbeitungsmodell mit NunchakuQwenImageDiTLoader (#115), leitet es durch ModelSamplingAuraFlow (#66) und CFGNorm (#75) und synthetisiert dann mit KSampler (#3). Laden Sie bis zu drei Bilder mit LoadImage (#78, #106, #108) hoch. Die Hauptreferenz wird durch VAEEncode (#88) kodiert, um die Leinwand festzulegen, und ImageScaleToTotalPixels (#93) hält die Eingaben innerhalb eines stabilen Größenbereichs.
Schreiben Sie Ihre Anweisung in TextEncodeQwenImageEditPlus (#111) und, falls erforderlich, platzieren Sie Entfernungen oder Einschränkungen im gepaarten TextEncodeQwenImageEditPlus (#110). Beziehen Sie sich ausdrücklich auf Quellen, zum Beispiel: "Hund im Bild 1 trägt den grünen Hut aus Bild 2 und die Brille aus Bild 3." Für eine benutzerdefinierte Ausgabengröße können Sie das kodierte Latent mit EmptySD3LatentImage (#112) ersetzen. Ergebnisse werden durch VAEDecode (#8) dekodiert und mit SaveImage (#60) gespeichert.
Nunchaku-qwen-image-edit (Einzelbildverfeinerung)#
Wählen Sie dies, wenn Sie gezielte Bereinigungen, Hintergrundänderungen oder Stilanpassungen an einem Bild vornehmen möchten. Das Modell wird von NunchakuQwenImageDiTLoader (#120) geladen, durch ModelSamplingAuraFlow (#125) und CFGNorm (#123) angepasst und von KSampler (#127) abgetastet. Importieren Sie Ihr Foto mit LoadImage (#129); es wird durch ImageScaleToTotalPixels (#130) normalisiert und durch VAEEncode (#131) kodiert.
Geben Sie Ihre Anweisung in TextEncodeQwenImageEdit (#121) und optionales Gegenlenkung in TextEncodeQwenImageEdit (#122) an, um Elemente beizubehalten oder zu entfernen. Der Zweig dekodiert mit VAEDecode (#124) und schreibt Dateien über SaveImage (#128).
Nunchaku-qwen-image (Text-zu-Bild)#
Verwenden Sie diesen Zweig, um neue Bilder von Grund auf mit dem Basismodell zu erstellen. NunchakuQwenImageDiTLoader (#146) speist ModelSamplingAuraFlow (#138). Geben Sie Ihre positiven und negativen Prompts in CLIPTextEncode (#143) und CLIPTextEncode (#137) ein. Legen Sie Ihre Leinwand mit EmptySD3LatentImage (#136) fest, generieren Sie dann mit KSampler (#141), dekodieren Sie mit VAEDecode (#142) und speichern Sie mit SaveImage (#147).
Schlüsselmodule im ComfyUI Nunchaku Qwen Bild-Workflow#
NunchakuQwenImageDiTLoader (#115) Lädt die Qwen Bild-Gewichte und Variante, die vom Zweig verwendet werden. Wählen Sie das Bearbeitungsmodell für fotogeführte Bearbeitungen oder das Basismodell für Text-zu-Bild. Wenn VRAM es zulässt, können Varianten mit höherer Präzision oder höherer Auflösung mehr Details liefern; leichtere Varianten priorisieren Geschwindigkeit.
TextEncodeQwenImageEditPlus (#111) Steuert Mehrbildbearbeitungen, indem Ihre Anweisung analysiert und an bis zu drei Referenzen gebunden wird. Halten Sie Anweisungen explizit darüber, welches Bild welches Attribut beiträgt. Verwenden Sie prägnante Formulierungen und vermeiden Sie widersprüchliche Ziele, um Bearbeitungen fokussiert zu halten.
TextEncodeQwenImageEditPlus (#110) Fungiert als gepaarter negativer oder Einschränkungs-Encoder für den Mehrbildzweig. Verwenden Sie es, um Objekte, Stile oder Artefakte auszuschließen, die nicht erscheinen sollen. Dies hilft oft, die Komposition zu bewahren und UI-Overlays oder unerwünschte Requisiten zu entfernen.
TextEncodeQwenImageEdit (#121) Positive Anweisung für den Einzelbild-Bearbeitungszweig. Beschreiben Sie das gewünschte Ergebnis, Oberflächenqualitäten und die Komposition in klaren Begriffen. Streben Sie ein bis drei Sätze an, die die Szene und Änderungen spezifizieren.
TextEncodeQwenImageEdit (#122) Negative oder Einschränkungs-Prompt für den Einzelbild-Bearbeitungszweig. Listen Sie Artikel oder Merkmale auf, die vermieden werden sollen, oder beschreiben Sie Elemente, die aus dem Quellbild entfernt werden sollen. Dies ist nützlich, um streunenden Text, Logos oder Interface-Elemente zu bereinigen.
ImageScaleToTotalPixels (#93) Verhindert, dass übergroße Eingaben Ergebnisse destabilisieren, indem sie auf eine Zielgesamtpixelanzahl skaliert werden. Verwenden Sie es, um unterschiedliche Quellauflösungen vor dem Compositing zu harmonisieren. Wenn Sie inkonsistente Schärfe zwischen den Quellen bemerken, bringen Sie sie hier in eine ähnliche effektive Größe.
ModelSamplingAuraFlow (#66) Wendet einen DiT/Fluss-abstimmenden Abtastplan an, der auf die Qwen Bild-Modelle abgestimmt ist. Wenn Ausgaben dunkel, matschig oder strukturlos erscheinen, erhöhen Sie die Verschiebung des Plans, um den globalen Ton zu stabilisieren; wenn sie flach aussehen, reduzieren Sie die Verschiebung, um zusätzliche Details zu verfolgen.
KSampler (#3) Der Hauptsampler, bei dem Sie Geschwindigkeit, Wiedergabetreue und stochastische Vielfalt ausbalancieren. Passen Sie Schritte und die Führungsskala für Konsistenz versus Kreativität an, wählen Sie eine Samplermethode und sperren Sie einen Seed, wenn Sie bei Läufen genaue Reproduzierbarkeit wünschen.
CFGNorm (#75) Normalisiert die classifier-free guidance, um Übersättigung oder Kontrastübersteigerungen bei höheren Führungsskalen zu reduzieren. Lassen Sie es im Pfad, wie bereitgestellt; es hilft, während der Iteration an Prompts eine gleichmäßige Farbe und Belichtung zu bewahren.
Optionale Extras#
- Für beste Mehrbildergebnisse wählen Sie Quellen mit ähnlicher Perspektive und Beleuchtung; das Nunchaku Qwen Bild-Bearbeitungsmodell konzentriert sich dann auf Inhalte statt auf Geometriekorrekturen.
- Beziehen Sie sich auf Quellen nach Reihenfolge ("Bild 1", "Bild 2", "Bild 3") und seien Sie explizit darüber, welche Attribute wohin übertragen werden.
- Wenn Ausgaben dunkel oder verschwommen neigen, schieben Sie die
ModelSamplingAuraFlowVerschiebung nach oben; wenn Sie zusätzliche Textur wünschen, probieren Sie eine etwas niedrigere Verschiebung. - Um eine spezifische Auflösung festzulegen, tauschen Sie das kodierte Latent gegen
EmptySD3LatentImageim verwendeten Zweig aus. - Verwenden Sie negative Prompts, um UI-Text, Wasserzeichen oder unerwünschte Objekte zu entfernen, bevor Sie in detaillierte Stilgestaltung investieren; dies hält die Nunchaku Qwen Bild-Bearbeitungen von Anfang an sauber.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Nunchaku für den Qwen-Bild-Workflow (ComfyUI-nunchaku) für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und -repositories, die unten verlinkt sind.
Ressourcen#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.



