
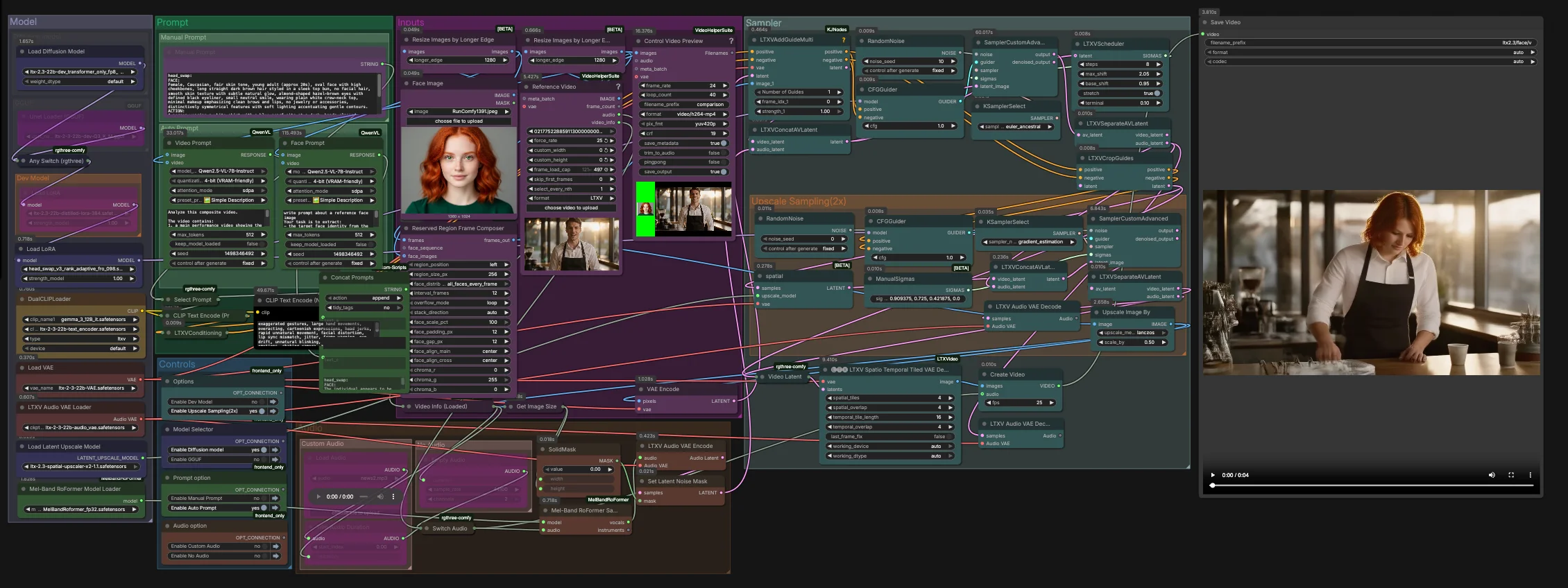
LTX-2.3-Video-Face-Swap für ComfyUI#
Dieser Workflow liefert hochauflösenden, zeitlich stabilen Video-Gesichtsersatz mit der LTX 2.3-Familie. Entwickelt für RunComfy und ComfyUI, kombiniert er ein Identitätsleitbild mit einem Zielvideo und optionaler Audioguidance, um Ausdrücke, Beleuchtung und Bewegung über Frames hinweg zu bewahren. Das Ergebnis ist ein realistischer, flackerfreier Austausch, der in Nahaufnahmen und mittleren Aufnahmen überzeugt.
Kreative, VFX-Künstler und KI-Filmemacher können LTX-2.3-Video-Face-Swap nutzen, um volle kreative Kontrolle zu behalten: Manuell promoten oder strukturierte Prompts aus den Eingaben generieren, zwischen dev, distilled, FP8 oder GGUF-Varianten wählen und mit einem spatio-temporalen Dekodieren und optionalem 2x latentem Upscaling für scharfe Details abschließen.
Schlüsselmodelle im Comfyui LTX-2.3-Video-Face-Swap-Workflow#
- LTX 2.3 22B Video Diffusion Transformer. Kernmodell für Videogenerierung und -bearbeitung, das Identitätserhaltung und zeitliche Kohärenz antreibt. Siehe die offizielle Modelfamilie bei Lightricks/LTX-2.3.
- LTX 2.3 Text Encoder. Der Graph paart den LTX 2.3 Text Encoder mit einem Gemma 3 12B Instruct Encoder, um die Promptaussage für die Videobearbeitung zu verbessern. Beispielartefakte: ltx-2-3-22b-text_encoder.safetensors und gemma_3_12B_it.safetensors.
- LTX 2.3 VAE und Audio VAE. Encoder/Decoder, die zur Komprimierung und Rekonstruktion von visuellen Frames und Audiotracks verwendet werden, während Details und Synchronisation erhalten bleiben. Siehe Lightricks/LTX-2.3 VAE files und Audio VAE-Varianten im Split-Repository vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Latent-space 2x Upscaler, der die räumliche Treue vor dem endgültigen Dekodieren erhöht, ideal für Gesichtsdetails. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head-swap LoRA. Ein rangadaptives LoRA, das auf Identitätstransfer spezialisiert ist und Ähnlichkeit und Stabilität bei der Bearbeitung verbessert. Beispiel: head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Optionales Musikquellentrennungsmodell, das hier verwendet wird, um Gesang zu isolieren, für stärkere Mundbewegungsführung. Kijai/MelBandRoFormer_comfy.
- Optionale Bereitstellungsvarianten. FP8 Transformator-Only-Gewichte für Geschwindigkeit auf unterstützten GPUs Kijai/LTX2.3_comfy und leichte UNet GGUF-Builds für CPU- oder Low-VRAM-Szenarien vantagewithai/LTX-2.3-GGUF.
So verwenden Sie den Comfyui LTX-2.3-Video-Face-Swap-Workflow#
Dieser Graph läuft in zwei Phasen. Phase eins führt den Kernaustausch in der nativen latenten Auflösung mit audio-bewusster Führung durch. Phase zwei skaliert im latenten Raum hoch und verfeinert den Gesichtsbereich vor einem spatio-temporalen Dekodieren und finalem Mux zum Video.
Eingaben#
- Laden Sie Ihr Identitätsbild in
Face Image(LoadImage(#255)). Verwenden Sie eine gut beleuchtete, frontale oder dreiviertel Aufnahme für die zuverlässigste Identitätsextraktion. - Laden Sie das Zielmaterial in
Reference Video(VHS_LoadVideo(#393)). Die Frames werden überResizeImagesByLongerEdgeundControl Video Preview(VHS_VideoCombine(#396)) normalisiert und zur schnellen Überprüfung vor dem Sampling bereitgestellt. - Der
ReservedRegionFrameComposer(#395) bereitet Führungsframes vor, die das Gesichtsbild an das Szenenlayout anpassen, wodurch das Modell sich während der Konditionierung auf den Austauschbereich konzentrieren kann.
Prompt#
- Sie können das gewünschte Aussehen und die Aktion manuell in
Manual Promptbeschreiben oder den Graphen ein strukturiertes Prompt automatisch erstellen lassen.Video Prompt(AILab_QwenVL(#400)) extrahiert die Körperbewegung und Szene aus dem Video, währendFace Prompt(AILab_QwenVL(#401)) Identitätsdetails aus dem Gesichtsbild extrahiert. Concat Promptsfügt Identität und Aktion zu einer prägnanten Anweisung zusammen, dann leitetSelect Promptentweder Ihren manuellen Text oder das automatische Prompt zuCLIP Text Encode. Negativer Prompt-Text wird separat kodiert, um häufige Videoartefakte zu unterdrücken.
Modell#
- Die
Model-Gruppe lädt das LTX 2.3 UNet oder seine GGUF-Variante, wendet das destillierte LoRA und das Head-swap LoRA an und bringt die LTX VAEs und dualen Text-Encoder hoch. Das Zwei-Encoder-Setup verbessert die Abstimmung für gesprochenen Inhalt und Kamerablockierung, ohne die Identität übermäßig einzuschränken. - Wenn Sie für Geschwindigkeit oder Speicher optimieren, wechseln Sie zwischen dev, distilled, FP8 Transformator-Only oder GGUF im bereitgestellten Modellselektor. Kein zusätzlicher Setup ist in RunComfy erforderlich.
Sampler#
- Phase eins kombiniert Video- und Audiolatenten in
LTXVConcatAVLatent(#321), dann wird mitCFGGuider(#326),LTXVScheduler(#324) undSamplerCustomAdvanced(#257) entrauscht. DerLTXVAddGuideMulti(#392) injiziert Ihren Identitätsleitfaden, sodass das Gesicht früh etabliert wird und im Laufe der Zeit stabil bleibt. - Nach einem ersten Durchgang trennt
LTXVSeparateAVLatent(#323) die Streams, sodassLTXVCropGuides(#282) die Bearbeitung auf das Gesicht konzentrieren kann. Dies konzentriert die Rechenleistung dort, wo sie zählt, und verbessert die zeitliche Konsistenz.
Upscale Sampling (2x)#
LTXVLatentUpsampler(#279) wendet den LTX 2.3 x2 räumlichen Upscaler im latenten Raum an. Das hochskalierte Videolatent wird dann mit dem Audiolatent inLTXVConcatAVLatent(#287) wieder zusammengeführt und von einem zweitenSamplerCustomAdvanced(#288) Durchgang, geleitet vonCFGGuider(#284), verfeinert.- Diese zweistufige Strategie liefert schärfere Haut, Augen und Haare, während der Austausch auf die beabsichtigte Identität fixiert bleibt.
Audio#
- Die
Audio-Gruppe ermöglicht es Ihnen, Originalaudio, Stille oder ein gekürztes Segment überSwitch Audiozu leiten. Für stärkere Lippenbewegungshinweise wird der ausgewählte Track durchMelBandRoFormerSampler(#355) gesendet, um Gesang zu isolieren, dann mitLTXVAudioVAEEncode(#364) kodiert. - Eine solide Rauschmaske (
SetLatentNoiseMask(#365)) verhindert unbeabsichtigte audio-getriebene Änderungen außerhalb des Mundbereichs, während die Sprachzeitung weiterhin Ausdrucksweisen lenken kann.
Dekodieren und exportieren#
- Die endgültigen Frames werden mit
LTXVSpatioTemporalTiledVAEDecode(#377) rekonstruiert, das mit zeitbewusster Kachelung dekodiert, um Nähte zu vermeiden und Bewegungs-Kontinuität zu wahren.CreateVideo(#292) verbindet die Bilder mit Ihrem gewählten Audio, undSaveVideospeichert den fertigen Clip.
Schlüssel-Knoten im Comfyui LTX-2.3-Video-Face-Swap-Workflow#
LTXVAddGuideMulti(#392). Führt den ausgerichteten Gesichtsleitfaden in den Konditionierungsstrom ein, sodass das Modell von den ersten Schritten an auf die Zielidentität fixiert wird. Wenn die Ähnlichkeit bei schnellen Bewegungen abweicht, erhöhen Sie die Anzahl oder Häufigkeit der Leitbilder anstatt die globale Führung zu erhöhen.LTXVCropGuides(#282). Fokussiert automatisch den zweiten Durchgang auf die aus Phase-eins-Latenzen und Prompts abgeleitete Gesichtsregion. Verwenden Sie es, um den Bearbeitungsbereich zu straffen, wenn Hintergründe oder Hände um Aufmerksamkeit konkurrieren.SamplerCustomAdvanced(#257). Primärer Denoise-Durchgang, der Identität, Beleuchtung und grobe Bewegung etabliert. Kombinieren Sie es mit demLTXVSchedulerfür Schrittformung und halten Sie die Samplerauswahl stabil über Experimente hinweg, um Vergleiche sinnvoll zu machen.LTXVLatentUpsampler(#279). Führt eine 2x latente Hochskalierung mit dem LTX räumlichen Upscaler vor der Verfeinerung durch. Verwenden Sie dies, wenn Sie schärfere Poren, Wimpern und Hutnähte benötigen, ohne Flackern von Post-Dekodierungs-Pixel-Upscalern einzuführen.SamplerCustomAdvanced(#288). Verfeinerungspass nach der Hochskalierung. Passen Sie die Führung hier moderat an, um Merkmale zu schärfen, während die von der ersten Phase gesetzte Identität erhalten bleibt.LTXVSpatioTemporalTiledVAEDecode(#377). Zeitbewusster Decoder, der Kachelnähte über Frames hinweg reduziert. Wenn Sie bei langen Clips auf VRAM-Beschränkungen stoßen, passen Sie lieber das Kachellayout an, anstatt die Auflösung zu senken.MelBandRoFormerSampler(#355). Nur zur Führung verwendete Gesangstrennung. Wenn das Quell-Audio verrauscht ist, wechseln Sie zu originalem oder stillem Audio, um zu vermeiden, dass Artefakte in die Mundbewegung übertragen werden.
Optionale Extras#
- Die Qualität des Gesichtsbildes ist wichtig. Verwenden Sie ein neutrales, gut beleuchtetes, frontales oder leicht dreiviertel Foto in einem ähnlichen Alter und Ausdruck wie die Performance.
- Halten Sie das Referenzvideo stabil. Statische oder Stativaufnahmen liefern die stabilsten LTX-2.3-Video-Face-Swap-Ergebnisse, insbesondere bei mittleren und Nahaufnahmen.
- Prompts sollten prägnant sein. Geben Sie die Szene und Aktion in einem einzigen Absatz an und reservieren Sie Identitätsadjektive für das Gesichts-Prompt, nicht für das Aktions-Prompt.
- Audioguidance ist optional. Klare Sprache verbessert die Mundformen; Musik-Only-Tracks bieten wenig Nutzen, wählen Sie also Stille, um Rechenleistung auf visuelle Inhalte zu konzentrieren.
- Für Low-VRAM- oder CPU-Only-Läufe bevorzugen Sie den GGUF UNet-Build; für hohen Durchsatz auf modernen GPUs sind FP8 Transformator-Only-Gewichte eine gute Wahl.
- Verwenden Sie verantwortungsbewusst. Holen Sie die Zustimmung für jegliche Ähnlichkeit ein, die Sie tauschen, und halten Sie sich an geltende Gesetze und Plattformrichtlinien.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken LTX-2.3 für das LTX-2.3-Modell und EyeForAILabs für das YouTube-Tutorial für ihre Beiträge und Wartung. Für autoritative Details beziehen Sie sich bitte auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- LTX-2.3/LTX-2.3 Modell
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartenden bereitgestellt werden.