
Hunyuan Video 1.5 ComfyUI Workflow: Schnelles Text-zu-Video und Bild-zu-Video mit 1080p Superauflösung#
Dieser Workflow integriert Hunyuan Video 1.5 in ComfyUI, um schnelle, kohärente Videogenerierung auf Consumer-GPUs zu liefern. Er unterstützt sowohl Text-zu-Video als auch Bild-zu-Video und skaliert optional auf 1080p mit einem dedizierten latenten Upsampler und einem destillierten Super-Resolution-Modell. Unter der Haube kombiniert Hunyuan Video 1.5 einen Diffusion Transformer mit einem 3D kausalen VAE und einer selektiven Sliding-Tile-Aufmerksamkeitsstrategie, um Qualität, Bewegungsgenauigkeit und Geschwindigkeit zu balancieren.
Kreative, Produktteams und Forscher können diesen ComfyUI Hunyuan Video 1.5 Workflow nutzen, um schnell von Eingabeaufforderungen oder einem einzelnen Standbild zu iterieren, Vorschauen in 720p zu erstellen und bei Bedarf mit klaren 1080p-Ausgaben abzuschließen.
Wichtige Modelle im ComfyUI Hunyuan Video 1.5 Workflow#
- HunyuanVideo 1.5 720p Bild-zu-Video UNet. Erzeugt Bewegung und zeitliche Kohärenz aus einem Startbild. Gewichte sind in der Comfy-Org-Neuverpackung auf Hugging Face verfügbar Comfy-Org/HunyuanVideo_1.5_repackaged.
- HunyuanVideo 1.5 720p Text-zu-Video UNet. Generiert Videos direkt aus Texteingaben mit derselben Kernarchitektur, abgestimmt auf eingabeaufforderungsorientierte Workflows. Siehe das oben erwähnte Repackage-Repository.
- HunyuanVideo 1.5 1080p Super-Resolution UNet (destilliert). Verfeinert 720p Latents zu höherem Detail, während Bewegung und Szenenstruktur erhalten bleiben. In derselben Neuverpackung auf Hugging Face enthalten.
- HunyuanVideo 1.5 3D VAE. Codiert und decodiert Video-Latents für effiziente Generierung und gekacheltes Decoding.
- HunyuanVideo 1.5 Latent Upsampler 1080p. Skaliert latente Sequenzen auf 1920×1080 vor der SR-Verfeinerung für Geschwindigkeit und Speichereffizienz.
- Qwen 2.5 VL 7B Text-Encoder und ByT5 Small Text-Encoder. Bieten robuste Anweisungsfolgen und Tokenisierung für diverse Eingabeaufforderungen, neuverpackt für diesen Workflow im Hugging Face-Bundle oben. ByT5’s originale Modellkarte: google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). Extrahiert hochwertige visuelle Merkmale aus dem Startbild, um die Bild-zu-Video-Konditionierung zu leiten: Comfy-Org/sigclip_vision_384.
So verwenden Sie den ComfyUI Hunyuan Video 1.5 Workflow#
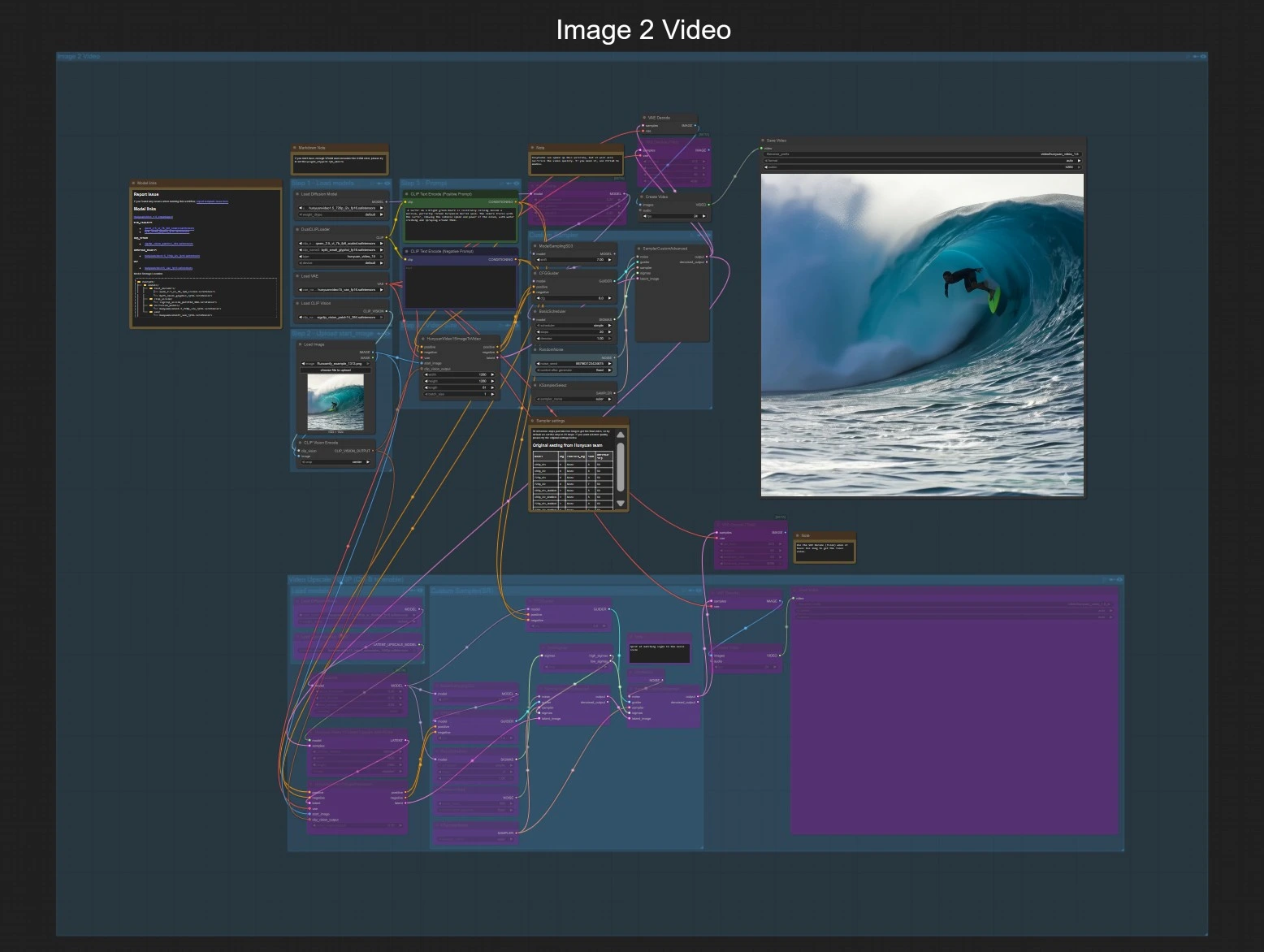
Dieses Diagramm zeigt zwei unabhängige Pfade, die dieselbe Export- und optionale 1080p-Abschlussstufe teilen. Wählen Sie entweder Bild zu Video oder Text zu Video und aktivieren Sie dann optional die 1080p-Gruppe zum Abschluss.
Bild zu Video#
Schritt 1 — Modelle laden Die Lader bringen das Hunyuan Video 1.5 UNet für Bild-zu-Video, das 3D VAE, die dualen Text-Encoder und SigCLIP Vision herein. Dieser Workflow ist bereit, ein einzelnes Startbild und eine Eingabeaufforderung zu akzeptieren. Es ist keine Benutzeraktion erforderlich, außer zu bestätigen, dass Modelle verfügbar sind.
Schritt 2 — Startbild hochladen Stellen Sie ein sauberes, gut belichtetes Bild in LoadImage (#80) bereit. Das Diagramm kodiert dieses Bild mit CLIPVisionEncode (#79), sodass Hunyuan Video 1.5 Bewegung und Stil an Ihrem Referenzbild verankern kann. Bevorzugen Sie Bilder, die ungefähr Ihrem Ziel-Seitenverhältnis entsprechen, um Beschneidung oder Auffüllung zu reduzieren.
Schritt 3 — Eingabeaufforderung Schreiben Sie Ihre Beschreibung in CLIP Text Encode (Positive Prompt) (#44). Verwenden Sie die negative Eingabeaufforderung CLIP Text Encode (Negative Prompt) (#93), um unerwünschte Artefakte oder Stile zu vermeiden. Halten Sie Eingabeaufforderungen kurz, aber spezifisch in Bezug auf das Thema, die Bewegung und das Kameraverhalten.
Schritt 4 — Videogröße und -dauer HunyuanVideo15ImageToVideo (#78) legt die räumliche Auflösung und die Anzahl der zu synthetisierenden Frames fest. Längere Sequenzen erfordern mehr VRAM und Zeit, also beginnen Sie kürzer und skalieren Sie hoch, sobald Ihnen die Bewegung gefällt.
Benutzerdefiniertes Sampling Der Sampler-Stack (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125)) steuert die Stärke der Führung, die Schritte, den Samplertyp und den Seed. Erhöhen Sie die Schritte für mehr Detail und Stabilität und verwenden Sie einen festen Seed, um Ergebnisse bei der Iteration von Eingabeaufforderungen zu reproduzieren.
Vorschau und speichern Die latente Sequenz wird mit VAEDecode (#8) dekodiert, zu einem Video mit 24 fps mit CreateVideo (#101) gerahmt und von SaveVideo (#102) geschrieben. Dies gibt Ihnen eine schnelle 720p-Vorschau, die bereit ist, überprüft zu werden.
1080p-Abschluss (optional) Schalten Sie die Gruppe „Video Upscale 1080P“ ein, um die Abschlusskette zu aktivieren. Der latente Upsampler erweitert auf 1920×1080, dann verfeinert das destillierte Super-Resolution UNet Details in zwei Phasen. VAEDecodeTiled und ein zweites CreateVideo/SaveVideo Paar exportieren das 1080p-Ergebnis.
Text zu Video#
Schritt 1 — Modelle laden Die Lader holen das Hunyuan Video 1.5 720p Text-zu-Video UNet, das 3D VAE und die dualen Text-Encoder. Dieser Pfad benötigt kein Startbild.
Schritt 3 — Eingabeaufforderung Geben Sie Ihre Beschreibung im positiven Encoder CLIP Text Encode (Positive Prompt) (#149) ein und fügen Sie optional eine negative Eingabeaufforderung in CLIP Text Encode (Negative Prompt) (#155) hinzu. Beschreiben Sie Szene, Thema, Bewegung und Kamera, wobei die Sprache konkret bleibt.
Schritt 4 — Videogröße und -dauer EmptyHunyuanVideo15Latent (#183) weist das initiale Latent mit Ihrer gewählten Breite, Höhe und Bildanzahl zu. Verwenden Sie dies, um festzulegen, wie lang und groß Ihr Video sein soll.
Benutzerdefiniertes Sampling ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162) und SamplerCustomAdvanced (#166) arbeiten zusammen, um Rauschen in ein kohärentes Video zu verwandeln, das von Ihrem Text geleitet wird. Passen Sie Schritte und Führung an, um Geschwindigkeit gegen Treue zu tauschen, und fixieren Sie den Seed, um Läufe vergleichbar zu machen.
Vorschau und speichern Die dekodierten Frames werden von CreateVideo (#168) zusammengefügt und von SaveVideo (#167) für eine schnelle 720p-Überprüfung bei 24 fps gespeichert.
1080p-Abschluss (optional) Aktivieren Sie die Gruppe „Video Upscale 1080P“, um Latents auf 1080p hochzuskalieren und mit dem destillierten SR UNet zu verfeinern. Das zweistufige Sampling verbessert die Schärfe, während die Bewegung erhalten bleibt. Ein gekachelter Decoder und eine zweite Speicherstufe exportieren das endgültige 1080p-Video.
Wichtige Knoten im ComfyUI Hunyuan Video 1.5 Workflow#
HunyuanVideo15ImageToVideo (#78) Erzeugt ein Video, indem es auf einem Startbild und Ihren Eingabeaufforderungen basiert. Passen Sie seine Auflösung und die Gesamtanzahl der Frames an Ihr kreatives Ziel an. Höhere Auflösungen und längere Clips erhöhen VRAM und Zeit. Dieser Knoten ist zentral für die Bild-zu-Video-Qualität, da er CLIP-Vision-Merkmale mit Textführung vor dem Sampling verschmilzt.
EmptyHunyuanVideo15Latent (#183) Initialisiert das latente Raster für Text-zu-Video mit Breite, Höhe und Bildanzahl. Verwenden Sie es, um die Sequenzlänge im Voraus festzulegen, damit der Scheduler und der Sampler eine stabile Denoising-Trajektorie planen können. Halten Sie das Seitenverhältnis konsistent mit Ihrem beabsichtigten Ausgabeformat, um späteres Auffüllen zu vermeiden.
CFGGuider (#129) Legt die Stärke der classifier-free guidance fest, um die Einhaltung der Eingabeaufforderung gegen Natürlichkeit auszubalancieren. Erhöhen Sie die Führung, um der Eingabeaufforderung strikter zu folgen; verringern Sie sie, um Übersättigung und Flimmern zu reduzieren. Verwenden Sie moderate Werte während der Basisgenerierung und niedrigere Führung für die Super-Resolution-Verfeinerung.
BasicScheduler (#126) Steuert die Anzahl der Denoising-Schritte und den Zeitplan. Mehr Schritte bedeuten normalerweise bessere Details und Stabilität, aber längere Renderzeiten. Kombinieren Sie die Schrittanzahl mit der Sampler-Wahl für beste Ergebnisse; dieser Workflow verwendet standardmäßig einen schnellen, universellen Sampler.
SamplerCustomAdvanced (#125) Führt die Denoising-Schleife mit Ihrem ausgewählten Sampler und der Führung aus. In der 1080p-Abschlusskette arbeitet es in zwei Phasen, die durch SplitSigmas geteilt sind, um zuerst Struktur bei höherem Rauschen zu etablieren und dann Details bei niedrigem Rauschen zu verfeinern. Halten Sie die Seeds fixiert, während Sie Schritte und Führung abstimmen, damit Sie Ausgaben zuverlässig vergleichen können.
HunyuanVideo15LatentUpscaleWithModel (#109) Skaliert die latente Sequenz auf 1920×1080 mit dem dedizierten Upsampler aus den neuverpackten Gewichten. Upscaling im latenten Raum ist schneller und speicherschonender als die Größenänderung im Pixelraum und bereitet den Weg für das destillierte SR-Modell, um feine Details hinzuzufügen. Größere Ziele erfordern mehr VRAM; halten Sie 16:9 für den besten Durchsatz.
HunyuanVideo15SuperResolution (#113) Verfeinert das hochskalierte Latent mit dem 1080p SR destillierten UNet aus dem Hunyuan Video 1.5 Bundle, wobei optional Startbild- und CLIP-Vision-Hinweise für Konsistenz aufgenommen werden. Dies fügt scharfe Texturen und Linienarbeit hinzu, während die Bewegung beibehalten wird. Die SR-Gewichte sind in Comfy-Org/HunyuanVideo_1.5_repackaged verfügbar.
EasyCache (#116) Zwischenspeichert Zwischenmodelzustände, um Vorschau-Iterationen zu beschleunigen. Aktivieren Sie es, wenn Sie schnellere Durchläufe wünschen, und deaktivieren Sie es für maximale Qualität beim letzten Durchlauf. Es ist besonders nützlich, wenn Sie mit denselben Auflösungen und Dauern an Eingabeaufforderungen arbeiten.
Optionale Extras#
- Halten Sie Eingabeaufforderungen konkret. Beschreiben Sie das Thema, Bewegungsverben und Kamerabewegungen. Verwenden Sie eine kurze negative Eingabeaufforderung, um wiederholt auftretende Artefakte zu unterdrücken.
- Bevorzugen Sie saubere, kontrastreiche Startbilder für Bild-zu-Video. Passen Sie das Seitenverhältnis an Ihre Zielauflösung an, um Auffüllungen zu minimieren.
- Um Geschwindigkeit zu erreichen, iterieren Sie bei kürzeren Dauern und 720p; schalten Sie die 1080p-Gruppe nur für endgültige Durchläufe ein.
- Wenn VRAM knapp ist, aktivieren Sie das gekachelte VAE-Decoding und erwägen Sie das Laden von Gewichten in einer niedrigeren Präzisionseinstellung, die vom Modell-Lader bereitgestellt wird.
- Fixieren Sie die Seeds, während Sie Schritte, Führung und Formulierung abstimmen, um Änderungen über Läufe hinweg messbar zu machen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Comfy.org für das Hunyuan Video 1.5 Workflow-Tutorial für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Hunyuan Video 1.5 Quelle
- Dokumente / Versionshinweise: Hunyuan Video 1.5 Quelle
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Wartungsmitarbeiter.