
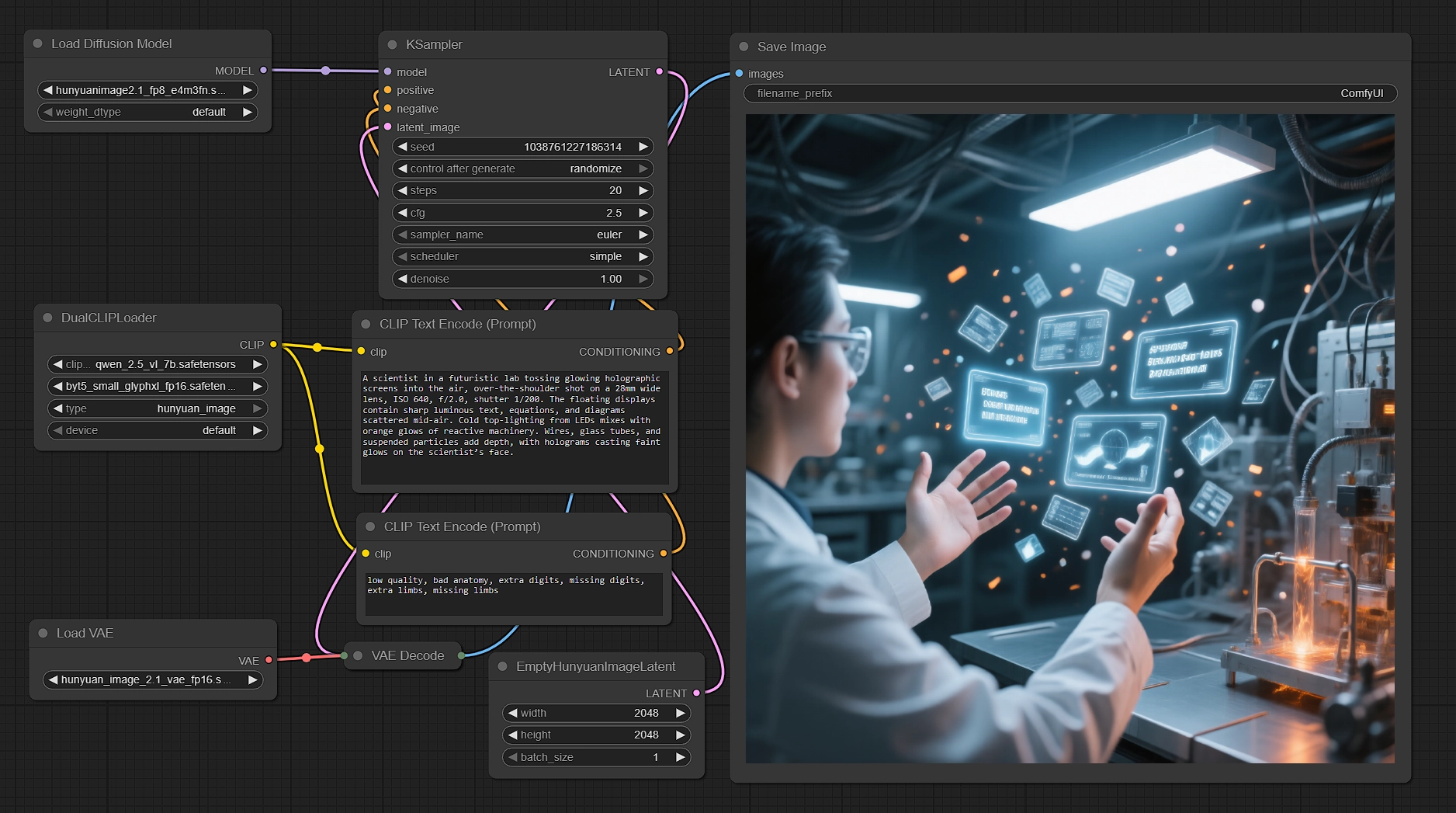










Erzeugen Sie native 2K-Bilder mit Hunyuan Image 2.1 in ComfyUI#
Dieser Workflow verwandelt Ihre Eingaben in scharfe, native 2048×2048-Renderings mit Hunyuan Image 2.1. Er kombiniert Tencent’s Diffusion Transformer mit dualen Text-Encodern, um die semantische Ausrichtung und die Textwiedergabequalität zu verbessern, dann wird effizient gesampelt und durch die passende hochkomprimierte VAE dekodiert. Wenn Sie produktionsreife Szenen, Charaktere und klaren Text in Bildern bei 2K benötigen, während Geschwindigkeit und Kontrolle erhalten bleiben, ist dieser ComfyUI Hunyuan Image 2.1-Workflow für Sie entwickelt.
Kreative, Artdirektoren und technische Künstler können mehrsprachige Eingaben vornehmen, einige Regler feinjustieren und konstant scharfe Ergebnisse erzielen. Das Diagramm wird mit einer sinnvollen negativen Eingabe, einer nativen 2K-Leinwand und einem FP8 UNet geliefert, um VRAM im Zaum zu halten und zu zeigen, was Hunyuan Image 2.1 direkt aus der Box liefern kann.
Wichtige Modelle im ComfyUI Hunyuan Image 2.1 Workflow#
- HunyuanImage‑2.1 von Tencent. Basis Text-zu-Bild-Modell mit einem Diffusion Transformer-Backbone, dualen Text-Encodern, einer 32× VAE, RLHF-Nachtraining und Meanflow-Distillation für effizientes Sampling. Links: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Multimodaler Vision-Language-Encoder, der hier als semantischer Text-Encoder verwendet wird, um das Verständnis von Eingaben in komplexen Szenen und Sprachen zu verbessern. Link: Hugging Face
- ByT5 Small. Tokenizer-freier Byte-Level-Encoder, der die Handhabung von Zeichen und Glyphen für die Textwiedergabe in Bildern stärkt. Links: Hugging Face · Paper
Verwendung des ComfyUI Hunyuan Image 2.1 Workflows#
Das Diagramm folgt einem klaren Pfad von der Eingabe zu den Pixeln: Text mit zwei Encodern kodieren, eine native 2K latente Leinwand vorbereiten, mit Hunyuan Image 2.1 sampeln, durch die passende VAE dekodieren und das Ergebnis speichern.
Textkodierung mit dualen Encodern#
- Der
DualCLIPLoader(#33) lädt Qwen2.5‑VL‑7B und ByT5 Small, konfiguriert für Hunyuan Image 2.1. Diese duale Einrichtung lässt das Modell Szenensemantiken parsen, während es robust gegenüber Glyphen und mehrsprachigem Text bleibt. - Geben Sie Ihre Hauptbeschreibung in
CLIPTextEncode(#6) ein. Sie können auf Englisch oder Chinesisch schreiben, Kamera-Hinweise und Beleuchtung mischen und Text-in-Bild-Anweisungen einfügen. - Eine gebrauchsfertige negative Eingabe in
CLIPTextEncode(#7) unterdrückt häufige Artefakte. Sie können es an Ihren Stil anpassen oder es so lassen, wie es ist, für ausgewogene Ergebnisse.
Latente Leinwand in nativer 2K#
EmptyHunyuanImageLatent(#29) initialisiert die Leinwand bei 2048×2048 mit einem einzigen Batch. Hunyuan Image 2.1 ist für die 2K-Generierung ausgelegt, daher werden native 2K-Größen für beste Qualität empfohlen.- Passen Sie Breite und Höhe bei Bedarf an und halten Sie das Seitenverhältnis, das Hunyuan unterstützt. Für alternative Verhältnisse bleiben Sie bei modellfreundlichen Dimensionen, um Artefakte zu vermeiden.
Effizientes Sampling mit Hunyuan Image 2.1#
UNETLoader(#37) lädt den FP8-Checkpoint, um VRAM zu reduzieren, während die Treue erhalten bleibt, und füttert dannKSampler(#3) zum Denoising.- Verwenden Sie die positiven und negativen Konditionierungen der Encoder, um Komposition und Klarheit zu steuern. Variieren Sie den Seed für Vielfalt, die Schritte für Qualität versus Geschwindigkeit und die Anleitung für die Eingabebindung.
- Der Workflow konzentriert sich auf den Basismodellpfad. Hunyuan Image 2.1 unterstützt auch eine Verfeinerungsstufe; Sie können später eine hinzufügen, wenn Sie zusätzlichen Feinschliff möchten.
Dekodieren und Speichern#
VAELoader(#34) bringt die Hunyuan Image 2.1 VAE undVAEDecode(#8) rekonstruiert das finale Bild aus dem gesampelten Latenten mit dem 32× Kompressionsschema des Modells.SaveImage(#9) schreibt das Ergebnis in Ihr gewähltes Verzeichnis. Setzen Sie ein klares Dateinamenpräfix, wenn Sie über Seeds oder Eingaben hinweg iterieren möchten.
Wichtige Knoten im ComfyUI Hunyuan Image 2.1 Workflow#
DualCLIPLoader (#33)#
Dieser Knoten lädt das Paar von Text-Encodern, das Hunyuan Image 2.1 erwartet. Halten Sie den Modelltyp für Hunyuan gesetzt und wählen Sie Qwen2.5‑VL‑7B und ByT5 Small, um starkes Szenenverständnis mit glyphenbewusster Texthandhabung zu kombinieren. Wenn Sie den Stil iterieren, passen Sie die positive Eingabe im Einklang mit der Anleitung an, anstatt die Encoder zu wechseln.
CLIPTextEncode (#6 und #7)#
Diese Knoten verwandeln Ihre positiven und negativen Eingaben in Konditionierung. Halten Sie die positive Eingabe oben prägnant, fügen Sie dann Linsen-, Beleuchtungs- und Stilhinweise hinzu. Verwenden Sie die negative Eingabe, um Artefakte wie zusätzliche Gliedmaßen oder störenden Text zu unterdrücken; kürzen Sie es, wenn Sie es für Ihr Konzept als zu einschränkend empfinden.
EmptyHunyuanImageLatent (#29)#
Definiert die Arbeitsauflösung und den Batch. Die Standardauflösung 2048×2048 stimmt mit Hunyuan Image 2.1’s nativer 2K-Fähigkeit überein. Für andere Seitenverhältnisse wählen Sie modellfreundliche Breite- und Höhe-Paare und erwägen Sie eine leichte Erhöhung der Schritte, wenn Sie sich weit vom Quadrat entfernen.
KSampler (#3)#
Steuert den Denoising-Prozess mit Hunyuan Image 2.1. Erhöhen Sie die Schritte, wenn Sie feinere Mikrodetails benötigen, verringern Sie sie für schnelle Entwürfe. Erhöhen Sie die Anleitung für stärkere Eingabebindung, aber achten Sie auf Übersättigung oder Steifheit; verringern Sie sie für mehr natürliche Variation. Wechseln Sie die Seeds, um Kompositionen zu erkunden, ohne Ihre Eingabe zu ändern.
UNETLoader (#37)#
Lädt das Hunyuan Image 2.1 UNet. Der enthaltene FP8-Checkpoint hält den Speicherverbrauch für 2K-Ausgaben bescheiden. Wenn Sie über reichlich VRAM verfügen und maximalen Spielraum für aggressive Einstellungen wünschen, sollten Sie eine höherpräzise Variante desselben Modells aus den offiziellen Veröffentlichungen in Betracht ziehen.
VAELoader (#34) und VAEDecode (#8)#
Diese Knoten müssen mit der Hunyuan Image 2.1-Veröffentlichung übereinstimmen, um korrekt zu dekodieren. Die hochkomprimierte VAE des Modells ist der Schlüssel zur schnellen 2K-Generierung; das richtige VAE-Paar vermeidet Farbverschiebungen und blockige Texturen. Wenn Sie das Basismodell ändern, aktualisieren Sie immer entsprechend die VAE.
Optionale Extras#
- Eingabeaufforderung
- Hunyuan Image 2.1 reagiert gut auf strukturierte Eingaben: Subjekt, Aktion, Umgebung, Kamera, Beleuchtung, Stil. Für Text im Bild, zitieren Sie die genauen Worte, die Sie möchten, und halten Sie sie kurz.
- Geschwindigkeit und Speicher
- Der FP8 UNet ist bereits effizient. Wenn Sie noch weiter optimieren müssen, deaktivieren Sie große Batches und bevorzugen Sie weniger Schritte. Optionale GGUF Loader-Knoten sind im Diagramm vorhanden, aber standardmäßig deaktiviert; fortgeschrittene Benutzer können sie beim Experimentieren mit quantisierten Checkpoints einfügen.
- Seitenverhältnisse
- Halten Sie sich an nativen 2K-freundlichen Größen für beste Ergebnisse. Wenn Sie sich auf breite oder hohe Formate begeben, überprüfen Sie eine saubere Wiedergabe und ziehen Sie eine kleine Erhöhung der Schritte in Betracht.
- Verfeinerung
- Hunyuan Image 2.1 unterstützt eine Verfeinerungsstufe. Um es auszuprobieren, fügen Sie nach dem Basisdurchlauf einen zweiten Sampler mit einem Verfeinerungs-Checkpoint und einem leichten Denoising hinzu, um die Struktur zu erhalten, während Mikrodetails verstärkt werden.
- Referenzen
- Hunyuan Image 2.1 Modell-Details und Downloads: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small und Papier: Hugging Face · Paper
Anerkennungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken @Ai Verse und Hunyuan für Hunyuan Image 2.1 Demo für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und Repositories, die unten verlinkt sind.
Ressourcen#
- Hunyuan/Hunyuan Image 2.1 Demo
- Dokumente / Release Notes: Hunyuan Image 2.1 Demo tutorial from @Ai Verse
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartenden bereitgestellt werden.

