
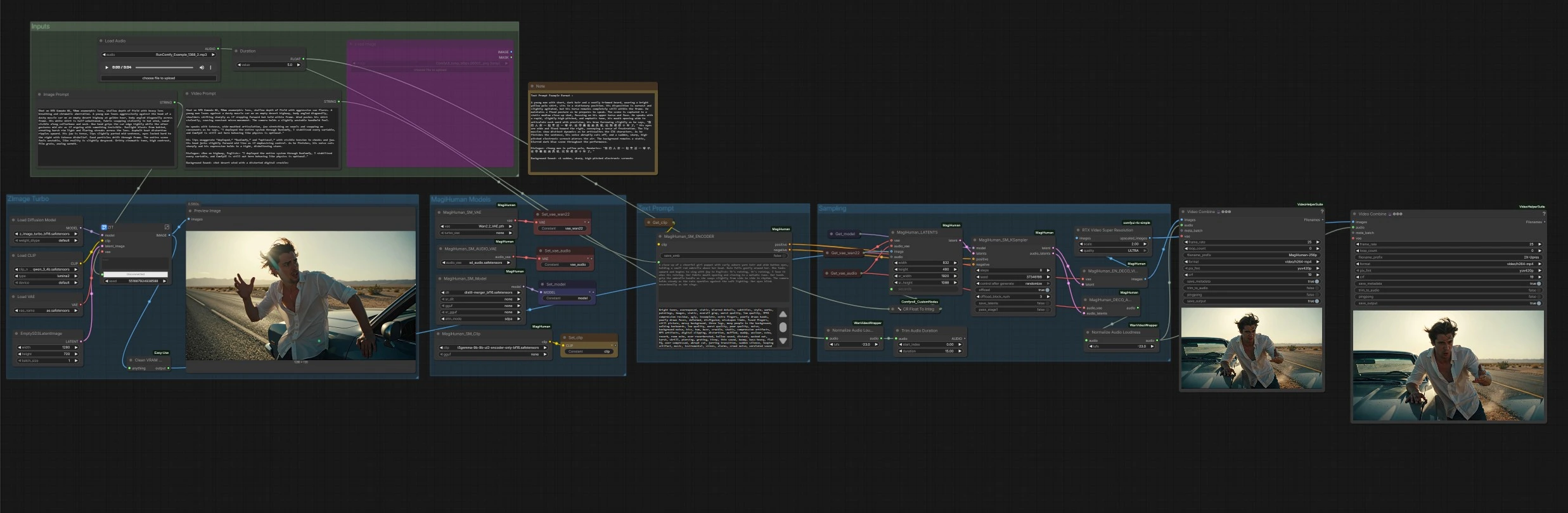
daVinci-MagiHuman sprechender digitaler Menschen-Workflow für ComfyUI#
Dieser ComfyUI-Workflow baut eine vollständige Text-zu-Video-Pipeline um daVinci-MagiHuman auf, um realistische sprechende digitale Menschen mit synchronisierter Sprache, Lippenbewegung, Ausdruck und Körpermikrobewegung zu erzeugen. Er ist für Ersteller gedacht, die einen schnellen, einstufigen Weg von einer beschreibenden Eingabeaufforderung zu einem MP4 mit sauberem Audio suchen. Der Graph kann ein frisch generiertes Porträt oder ein beliebiges Referenzbild animieren und rendert dann Video und Sprache zusammen, wobei optionales Hochskalieren und automatische Audio-Lautstärkenormalisierung abgeschlossen werden.
Der daVinci-MagiHuman-Kern verwendet einen Single-Stream-Transformer, um Video und Audio aus einer Eingabeaufforderung zu ko-generieren, was hilft, das Timing und die Lippenabgleich-Treue selbst bei kurzen Clips zu bewahren. Diese ComfyUI-Implementierung hält die Steuerungen einfach: Schreiben Sie eine Bild-Eingabeaufforderung, um das Aussehen zu definieren, eine Video-Eingabeaufforderung, um die Leistung und den Dialog zu definieren, setzen Sie die Clip-Dauer und führen Sie aus.
Schlüsselmodelle im ComfyUI daVinci-MagiHuman Workflow#
- daVinci-MagiHuman (15B Single-Stream Audio-Video-Generator). Rolle: produziert gemeinsam Videoframes und Sprache aus Text, während es zeitliche Konsistenz und Lippenabgleich beibehält. Referenzen: GitHub, arXiv, Hugging Face.
- T5Gemma 9B Encoder (UL2-adaptiert). Rolle: codiert die Video-Eingabeaufforderung in reichhaltige Konditionierung, die Bewegung, Lieferung und Stil für daVinci-MagiHuman steuert. Referenz: Hugging Face.
- Z-Image Turbo Diffusionsmodell. Rolle: generiert schnell ein hochwertiges Standbild-Porträt aus der Bild-Eingabeaufforderung zur Verwendung als Identität/Referenz für die Animation. Referenzen: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Qwen 3 4B Textencoder für Z-Image Turbo. Rolle: analysiert die Bild-Eingabeaufforderung zur Steuerung der Porträtgenerierung. Referenz: Hugging Face Datei.
- Wan 2.2 VAE. Rolle: dekodiert MagiHuman Video-Latents zu RGB-Frames mit starker zeitlicher Konsistenz. Referenzen: GitHub, Hugging Face Beispielmodell.
- Audio VAE (sd_audio). Rolle: dekodiert MagiHuman Audio-Latents zu einer Sprachwellenform zum Muxing mit dem endgültigen Video. Referenz: benutzerdefiniertes Node-Bundle für MagiHuman GitHub.
- RTX Video Super Resolution (optional). Rolle: post-skaliert dekodierte Frames, um die wahrgenommene Schärfe zu erhöhen und Kompressionsartefakte vor der finalen Kodierung zu reduzieren. Referenz: ComfyUI Wrapper GitHub.
So verwenden Sie den ComfyUI daVinci-MagiHuman Workflow#
Gesamtfluss: Die Z-Image Turbo-Gruppe erstellt ein Identitätsporträt aus Ihrer Bild-Eingabeaufforderung. Die MagiHuman-Modelle-Gruppe lädt den daVinci-MagiHuman-Checkpoint, das Video-VAE und das Audio-VAE und bereitet den Text-Encoder vor. Die Text-Eingabeaufforderungsgruppe verwandelt Ihre Video-Eingabeaufforderung in Konditionierung. Die Sampling-Gruppe fusioniert das Referenzbild und die Eingabeaufforderung in gemeinsame Video- und Audio-Latents und dekodiert dann beide. Schließlich muxiert die Ausgabestufe Frames mit Audio in MP4, mit einer optional hochskalierten Version.
Eingaben#
Verwenden Sie die Textfelder Bild-Eingabeaufforderung und Video-Eingabeaufforderung, um Aussehen und Leistung zu beschreiben. Die Dauersteuerung legt die Clip-Länge in Sekunden fest. Ein Audio-Loader ist zur Bequemlichkeit vorhanden, falls Sie mit audio-gesteuerten Varianten experimentieren möchten, aber diese Vorlage läuft standardmäßig im text-gesteuerten Modus.
ZImage Turbo#
Diese Stufe rendert ein einzelnes Referenzporträt aus der Bild-Eingabeaufforderung mit dem Z-Image Turbo UNet mit dem Qwen 3 4B Textencoder und dessen gebündeltem VAE. Es ist für schnelle, saubere Identitätsgenerierung mit filmischen Looks optimiert. Das Ergebnis wird angezeigt und dann als Referenzbild für die Animation weitergeleitet. Wenn Sie bereits ein Porträt haben, können Sie dies umgehen, indem Sie Ihr Bild direkt an die Animationsstufe weiterleiten.
MagiHuman Modelle#
Hier lädt der Graph den daVinci-MagiHuman-Basis- oder destillierten Checkpoint zusammen mit dem Wan 2.2 Video VAE, dem Audio VAE und dem T5Gemma Encoder. Dies hält Textkodierung, Video-Latents und Audio-Latents für die Single-Stream-Sampling ausgerichtet. Sie können Gewichte austauschen, wenn Sie Alternativen in Ihrer Umgebung haben.
Text-Eingabeaufforderung#
Ihre Video-Eingabeaufforderung wird in positive und negative Konditionierung kodiert. Positiver Text sollte Kameradistanz, Pose, Sprache, Lieferstil und den genauen Dialoginhalt beschreiben. Negativer Text kann visuelle oder Audio-Defekte auflisten, die vermieden werden sollen. Der Encoder füttert beide Sets von Konditionierung in den Sampler, um Bewegung, Lippenbewegungen und Timbre zu formen.
Sampling#
Der Sampler erstellt eine anfängliche latente Sequenz aus dem Referenzbild und der angeforderten Dauer und führt dann ein Denoising mit daVinci-MagiHuman durch, um synchronisierte Video- und Audio-Latents zu erzeugen. Ein Dienstprogramm wandelt die Dauer in ganze Sekunden um, um eine stabile Zeitplanung zu gewährleisten. Wenn das Sampling abgeschlossen ist, gehen die Video-Latents an den Videodecoder und die Audio-Latents an den Audio-Decoder.
Dekodieren, Lautstärke und Export#
Video-Latents werden mit dem Wan 2.2 VAE zu Bild-Frames dekodiert. Audio-Latents werden zu Sprache dekodiert und dann auf broadcast-freundliche Lautstärke normalisiert, damit das endgültige MP4 konsistent über Geräte hinweg abgespielt wird. Es werden zwei Exporte erstellt: ein Basenrender und ein optional hochskalierter Render mit RTX Video Super Resolution. Beide werden mit Audio zu MP4 gemuxed und mit klaren Dateinamen-Präfixen gespeichert.
Schlüssel-Nodes im ComfyUI daVinci-MagiHuman Workflow#
MagiHuman_LATENTS(#13)
Erstellt die gemeinsame latente Leinwand für Video und optionales Audio, indem es das Referenzbild und die Clip-Länge nimmt. Passen Sie seconds an, um die Dauer festzulegen, und stellen Sie sicher, dass Ihr Referenzbild gut gerahmt ist für die von Ihnen beschriebene Bewegung. Höhere Basisauflösung hilft, die Gesichtstreue zu verbessern, erhöht jedoch auch den VRAM- und Dekodierzeitbedarf.
MagiHuman_SM_ENCODER(#95)
Kodiert die Video-Eingabeaufforderung in positive und negative Konditionierung für den Sampler. Setzen Sie die genau gesprochene Zeile in Anführungszeichen und benennen Sie die Sprache, um den Lippenverschluss und das Timing zu verbessern. Verwenden Sie das negative Feld, um Artefakte wie "Untertitel", "statisches Rauschen" oder "Raumecho" zu unterdrücken.
MagiHuman_SM_KSampler(#9)
Führt das Denoising von daVinci-MagiHuman durch, um Video- und Sprach-Latents gemeinsam zu erzeugen. Der seed steuert die Reproduzierbarkeit, während steps und der interne Zeitplan Geschwindigkeit gegen Detail und Bewegungsstabilität eintauschen. Für Variation ohne Verlust der Identität ändern Sie seed oder formulieren Sie den Leistungsanteil Ihrer Eingabeaufforderung leicht um.
MagiHuman_EN_DECO_VIDEO(#5)
Dekodiert Video-Latents mit dem Wan 2.2 VAE in RGB-Frames zum Export oder Hochskalieren. Verwenden Sie diesen Pfad für das schnellste End-to-End-Rendering; lange Clips oder höhere Auflösungen erhöhen linear die Dekodierzeit.
MagiHuman_DECO_AUDIO(#6)
Dekodiert Audio-Latents zu einer Wellenform und sendet sie durch die Lautstärkenormalisierung für gleichmäßige Wiedergabe. Wenn Sie später zu audio-gesteuerter Generierung wechseln, leiten Sie Ihr externes Audio in den Latenten-Builder und behalten Sie diesen Dekodierpfad für das finale Muxing bei.
RTXVideoSuperResolution(#93)
Optionaler Post-Upscaler, der Kanten schärft und Klingeln reduziert. Verwenden Sie moderate Stärke, um die Klarheit zu verbessern, ohne zeitliches Flimmern einzuführen.
Optionale Extras#
- Eingabeaufforderungsmuster für zuverlässigen Lippenabgleich: Fügen Sie ein Sprecher-Tag und eine Sprache plus eine zitierte Zeile ein, zum Beispiel Dialog: <Presenter, English>: "Welcome to the show." Fügen Sie eine kurze Notiz über Lieferung, Bildgröße und Kamerastabilität hinzu.
- Halten Sie das Referenzporträt als mittlere Nahaufnahme mit dem Kopf vollständig im Rahmen. Enge Zuschnitte lassen wenig Raum für Kiefer- und Wangenbewegungen.
- Wenn Sie strengere Zeitvorgaben benötigen, schneiden oder erweitern Sie Ihr Skript, um es an die gewählte Dauer anzupassen. Sehr lange Sätze in sehr kurzen Clips können unnatürliche Artikulation erzwingen.
- Diese Vorlage läuft im rein textgesteuerten Modus. Für audio-gesteuerte Tests verbinden Sie eine externe Audiodatei mit dem Audioeingang auf
MagiHuman_LATENTS(#13) und passen Sie Ihre Video-Eingabeaufforderung an, um Ausdruck anstelle von gesprochenem Inhalt zu beschreiben.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken daVinci-MagiHuman für die daVinci-MagiHuman Workflow Source für ihre Beiträge und Wartung. Für autoritative Details beziehen Sie sich bitte auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- daVinci-MagiHuman/Workflow Source
- Docs / Release Notes: daVinci-MagiHuman Workflow Source
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Erhaltern bereitgestellt werden.
