
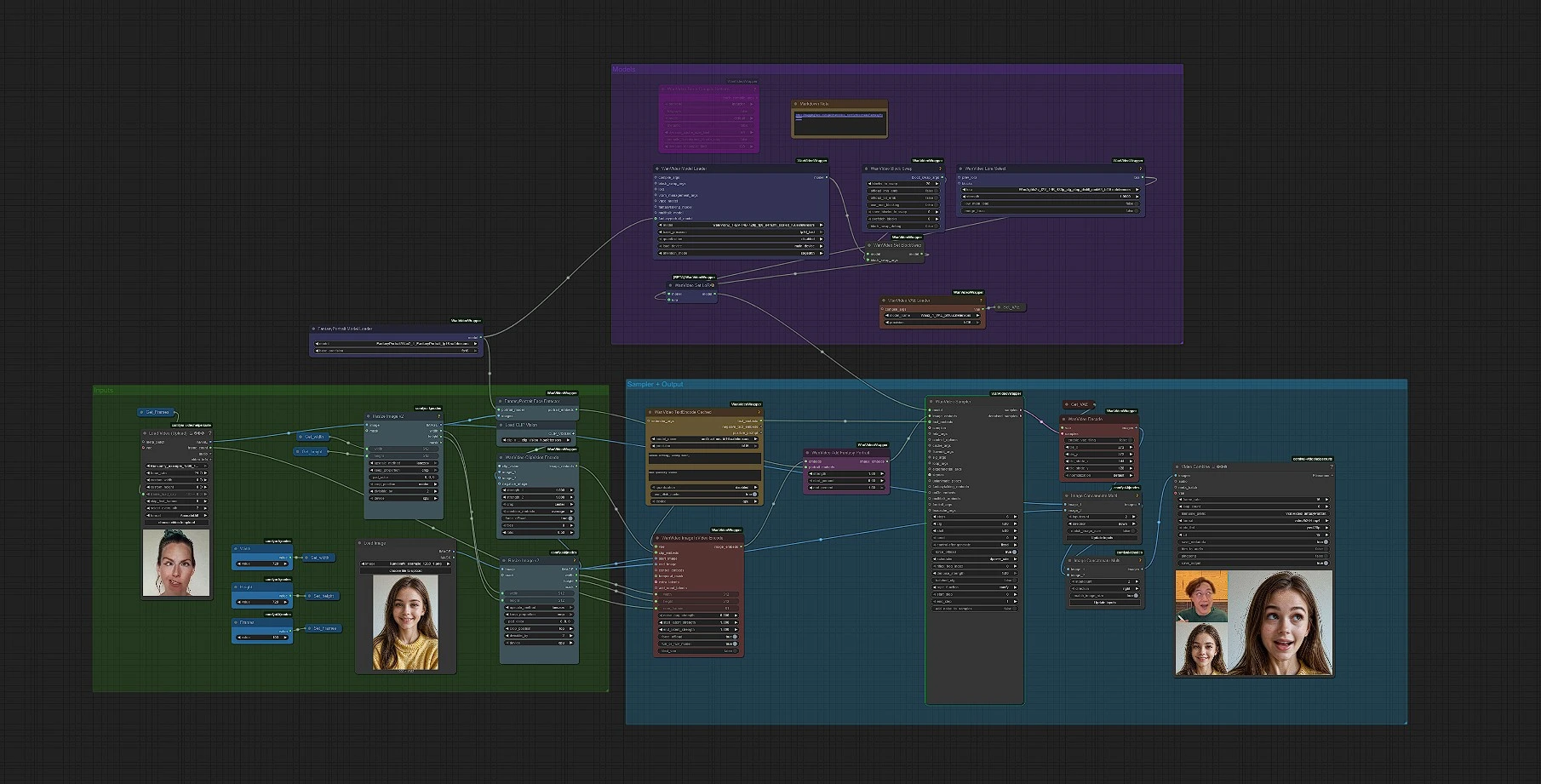
Fantasy-Porträt: Ausdrucksreiche Porträtanimation in ComfyUI#
Dieser Workflow verwandelt ein einzelnes Standbild in eine hochauflösende Fantasy-Porträt-Animation. Er integriert das Fantasy-AMAP FantasyPortrait-Modell mit ausdrucksverstärkten Diffusionstransformatoren und verpackt es in eine Wan Video 2.1 Bild-zu-Video-Pipeline, sodass Sie identitätsbewahrende, emotionsreiche Sprechaufnahmen mit minimalem Setup erzeugen können. Er ist für Kreative konzipiert, die filmische Fantasy-Porträt-Bewegungen aus einem einzigen Foto mit klaren Steuerungen für Framing, Dauer und Stil wünschen.
Die Pipeline ist vollautomatisiert: Porträt einfügen, Auflösung und Bildanzahl wählen, optional ein Prompt und LoRA hinzufügen und dann in MP4 rendern. Unter der Haube erkennt der Graph das Gesicht, kodiert Bild- und Textanweisungen, fusioniert Fantasy-Porträt-Identitätsembeddings in Wans I2V-Conditioner, sampelt ein Video und dekodiert die Frames, bevor der endgültige Clip gespeichert wird.
Schlüsselmodelle im ComfyUI Fantasy-Porträt-Workflow#
FantasyPortrait (Fantasy-AMAP)
Kernmodul für Identität und Ausdruck. Bietet ausdrucksverstärkte Embeddings, die Subjekteigenschaften bewahren und nuancierte Gesichtsbewegungen ermöglichen. GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
Video-Diffusions-Backbone, das für das Sampeln der Animation aus dem Porträt und der Text-/Bildkonditionierung verwendet wird. Quantisierte, Comfy-bereite Gewichte sind über Kijais Modellpaket verfügbar. Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL Encoder
Hochleistungs-Textencoder, der für die Prompt-Führung im Videosampler verwendet wird. Beispielgewicht: umt5-xxl-enc-bf16.safetensors in Kijai/WanVideo_comfy
Wan 2.1 VAE
Video-optimiertes VAE für das Kodieren/Dekodieren von Latenten. Beispielgewicht: Wan2_1_VAE_bf16.safetensors in Kijai/WanVideo_comfy
So verwenden Sie den ComfyUI Fantasy-Porträt-Workflow#
Der Workflow läuft von links nach rechts, von den Eingaben bis zum finalen Video. Sie richten hauptsächlich drei Dinge vorneweg ein: Bild, Dimensionen und Dauer. Dann können Sie mit einem kurzen Prompt oder einer LoRA verfeinern, wenn Sie möchten.
1) Bildeingabe und Größenanpassung#
Laden Sie ein einzelnes Porträt in LoadImage, dann wird es für die Verarbeitung angepasst. Zwei Größenanpassungsstufen sorgen dafür, dass das Bild mit Ihrer gewählten Breite und Höhe übereinstimmt und die Komposition beibehält. Verwenden Sie die Steuerungen Width, Height und Frames, um die Ausgabegröße (Standard 720 × 720) und die Animationslänge zu definieren. Dies hält Ihr Fantasy-Porträt-Framing über die Pipeline hinweg konsistent.
2) Gesichtserkennung und Fantasy-Porträt-Embeddings#
FantasyPortraitModelLoader lädt die FantasyPortrait-Gewichte, und FantasyPortraitFaceDetector extrahiert identitäts- und ausdrucksbewusste Porträt-Embeddings aus Ihrem Bild. Die Kernidee ist, zu trennen, wer das Subjekt ist, von dem, wie es Emotionen ausdrückt, sodass die finale Animation die Identität bewahrt und gleichzeitig ausdrucksstarke Bewegungen ermöglicht. Sie müssen hier nichts anpassen, es sei denn, Sie wechseln die Modelle.
3) Bild- und Textkonditionierung#
Für die Bildführung erzeugt CLIPVisionLoader mit WanVideoClipVisionEncode robuste visuelle Merkmale aus dem Porträt. Für die Textführung verwendet WanVideoTextEncodeCached den UMT5-XXL-Encoder, um Ihre positiven und negativen Prompts in Videokondition-Embeddings zu verwandeln. Ein kurzer, einfacher Prompt wie „natürliches Studio-Nahaufnahme, sanftes Lächeln“ reicht oft für einen klaren Fantasy-Porträt-Look aus.
4) I2V-Kodierung mit Dauerkontrolle#
VHS_LoadVideo wird als praktischer Frame-Zähler verwendet. Sie können den Platzhalterclip belassen oder eine Referenz mit Ihrer bevorzugten Dauer laden; die Bildanzahl speist WanVideoImageToVideoEncode, das Ihr Startbild plus Bild-/Text-Embeddings in I2V-Konditionierung verwandelt. Wenn Sie eine feste Länge bevorzugen, setzen Sie Frames einfach direkt und ignorieren Sie den Referenzlader.
5) Fantasy-Porträt-Fusion#
WanVideoAddFantasyPortrait fusioniert die I2V-Konditionierung mit den Porträt-Embeddings aus Schritt 2. Dies verleiht der finalen Fantasy-Porträt-Animation ihre starke Identitätsbewahrung und ausdrucksstarke Details. Keine zusätzlichen Eingaben sind erforderlich, sobald Ihr Bild geladen ist.
6) LoRA und Modelleinstellung#
WanVideoModelLoader lädt Wan 2.1, dann wendet WanVideoLoraSelect optional eine leichte I2V-LoRA aus dem Kijai-Paket an, um Bewegung oder Ästhetik ohne Neutrainieren zu beeinflussen. Dies ist ein guter Ort, um zu experimentieren, wenn Sie ein etwas stilisierteres Fantasy-Porträt wünschen, während die Identität erhalten bleibt.
7) Video-Sampling und Dekodierung#
WanVideoSampler erzeugt latente Frames mit den fusionierten Konditionen. Halten Sie die Prompts einfach, erhöhen Sie die Schritte moderat, wenn Sie mehr Details benötigen, und vermeiden Sie übermäßiges Einschränken mit langen Negativen. WanVideoDecode konvertiert Latente zurück in Bilder, und der Workflow fügt Vorschauen zusammen, bevor VHS_VideoCombine ein MP4 schreibt (Standard 16 fps, yuv420p). Der Präfix des Ausgabedateinamens ist der Bequemlichkeit halber festgelegt.
Wichtige Knoten im ComfyUI Fantasy-Porträt-Workflow#
FantasyPortraitModelLoader (#138)#
Lädt die FantasyPortrait-Gewichte. Tauschen Sie hier, wenn Sie eine neuere Fantasy-AMAP-Version testen. Keine Abstimmung erforderlich, aber halten Sie die Präzision konsistent mit Ihrem Wan-Modell und VAE.
FantasyPortraitFaceDetector (#142)#
Extrahiert Porträt-Embeddings aus dem angepassten Bild. Gute Ergebnisse kommen von gut beleuchteten, frontalen Fotos mit minimalen Verdeckungen. Wenn die Bewegung seltsam aussieht, überprüfen Sie den Eingabeschnitt und versuchen Sie es mit einer saubereren Quelle.
WanVideoImageToVideoEncode (#151)#
Erstellt Wans I2V-Konditionierung aus CLIP-Bildmerkmalen, Ihrem Startbild und der Dauer. Passen Sie width, height und num_frames an, um den Render-Footprint und die Länge zu steuern. Längere Sequenzen benötigen mehr VRAM und Zeit.
WanVideoAddFantasyPortrait (#150)#
Fusioniert Fantasy-Porträt-Identität/Ausdrücke in den I2V-Conditioner. Verwenden Sie dies, um das Subjekt über die Frames hinweg erkennbar gleich zu halten, während nuancierte Ausdrucksänderungen ermöglicht werden. Keine Parameter erfordern typischerweise Anpassungen.
WanVideoSampler (#149)#
Erzeugt die Video-Latenten. Wenn Sie schärfere Details wünschen, erhöhen Sie die Schritte maßvoll. Wenn die Bewegung driftet, reduzieren Sie die Prompt-Komplexität oder versuchen Sie eine andere LoRA. Halten Sie die Führung kohärent statt ausführlich.
WanVideoTextEncodeCached (#155)#
Kodiert positive/negative Prompts mit UMT5-XXL. Verwenden Sie kurze, beschreibende Phrasen. Zu starke negative Prompts (z.B. schwere „schlechte Qualität“-Stapel) können den Ausdruck unterdrücken.
Tipps#
- Beginnen Sie mit quadratischen 720 × 720 und 4 bis 6 Sekunden für schnelle Iterationen, dann skalieren Sie bei Bedarf hoch.
- Verwenden Sie ein sauberes, frontales Porträt mit sichtbaren Augen. Vermeiden Sie starke Verdeckungen, Sonnenbrillen oder extreme Winkel.
- Halten Sie Fantasy-Porträt-Prompts prägnant. Beschreiben Sie Beleuchtung und Stimmung, nicht die Identität.
- Probieren Sie ein sanftes LoRA aus dem Kijai-Paket, wenn Sie ein anderes Bewegungsgefühl wünschen, ohne die Identität zu verlieren.
Danksagungen#
Dieser Workflow nutzt das Fantasy-Porträt-Modell des Fantasy-AMAP Teams, integriert Expression-Augmented Diffusion Transformers in ComfyUI für eine vollautomatisierte, hochwertige Porträtanimations-Pipeline. Besonderer Dank an kijai für die Erstellung und Integration des Wan Video Wrapper Node, der es ermöglicht, Porträtanimation nahtlos in einem Bild-zu-Video-Framework auszuführen. Wir danken auch der breiteren ComfyUI-Gemeinschaft für ihre kontinuierlichen Beiträge zu offenen Kreativwerkzeugen.
Links:
