
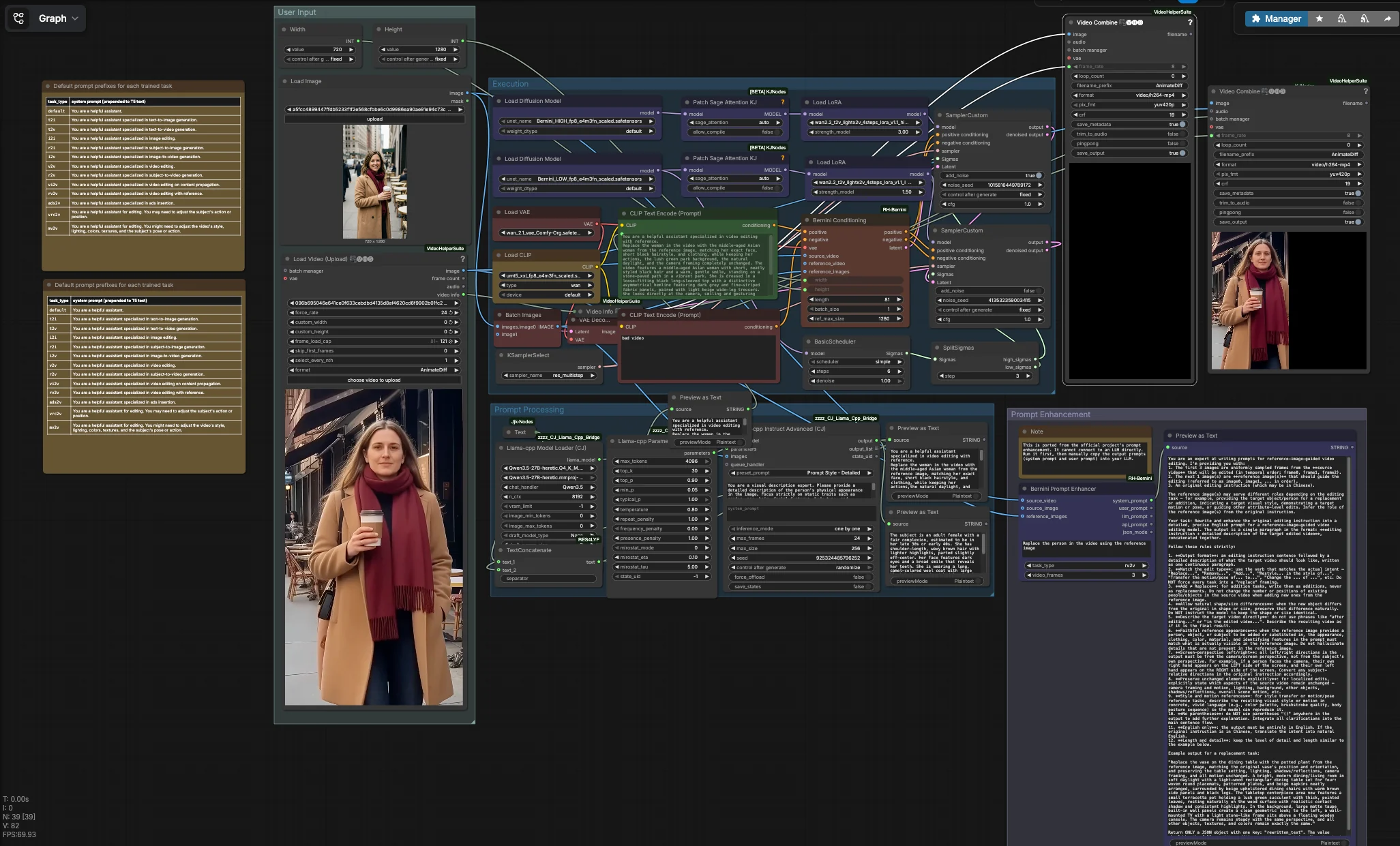
Bernini-Workflow für multimodale Videogenerierung und -bearbeitung#
Dieser Bernini-Workflow für multimodale Videogenerierung und -bearbeitung ist eine schlüsselfertige ComfyUI-Pipeline für identitätsbewusste, referenzgesteuerte Videobearbeitung und Video-zu-Video-Transformation. Er kombiniert ein Quellvideo, ein oder mehrere Referenzbilder und einen fokussierten Prompt, um Bewegung und Kameraverhalten zu bewahren, während das Motiv ersetzt oder umgestaltet wird. Der Workflow kombiniert Berninis High- und Low-Diffusions-Backbones mit Wan-Style-Textkodierung, einem Bernini-kompatiblen VAE, LightX2V LoRAs und Bernini-spezifischer Konditionierung, sodass die Ergebnisse von Frame zu Frame konsistent aussehen.
Entwickelt für Kreative und Forscher, die Bernini in ComfyUI evaluieren, glänzt der Workflow bei Charakterersetzungen, bewegungserhaltenden Bearbeitungen, Nachahmungen und kameraorientierter Kurzformgenerierung. Er exportiert ein bearbeitetes MP4 sowie optional einen Vergleich nebeneinander, was es einfach macht, die Auswirkungen Ihres Prompts und Ihres Referenzsatzes zu überprüfen. In diesem README bezieht sich der Begriff Bernini-Workflow für multimodale Videogenerierung und -bearbeitung auf diesen umfassenden Graphen.
Wichtige Modelle im Comfyui Bernini-Workflow für multimodale Videogenerierung und -bearbeitung#
- ByteDance Bernini-Diffusionsmodellfamilie (HIGH und LOW Backbones). Bietet die Kernentrauschungsnetzwerke, die in einem zweistufigen Zeitplan verwendet werden: Das HIGH-Modell behandelt die Struktur unter stärkerem Rauschen, während das LOW-Modell Details und zeitliche Konsistenz verfeinert. Siehe den Modellhub für Referenzgewichte und Notizen: ByteDance/Bernini.
- Wan-Textkodierer (umT5-XXL). Ein Wan-Style T5-Kodierer, der Ihre Anweisung in Konditionierung für Bernini umwandelt; in ComfyUI über eine CLIP-kompatible Schnittstelle verfügbar. Geeignete Assets für ComfyUI sind hier verfügbar: Kijai/WanVideo_comfy_fp8_scaled.
- Wan 2.1 VAE. Führt latente Dekodierung durch, um entrauschte Latenten in Videoframes mit Farbtongenauigkeit, die dem Training von Wan/Bernini entspricht, zu verwandeln. Ein ComfyUI-bereiter VAE ist im selben Asset-Paket enthalten: Kijai/WanVideo_comfy_fp8_scaled.
- LightX2V LoRA-Paar (high_noise und low_noise). Leichte Adapter, die Bernini in Richtung stabiler Bewegung lenken und die Referenzidentität über die Frames hinweg bewahren. Die bereitgestellten FP8-LoRA-Gewichte stimmen mit der zweistufigen Abtastung überein, die in diesem Workflow verwendet wird, und sind mit den oben genannten Bernini-Assets verpackt: Kijai/WanVideo_comfy_fp8_scaled.
Wie man den Comfyui Bernini-Workflow für multimodale Videogenerierung und -bearbeitung verwendet#
Dieser Workflow hat vier koordinierte Gruppen. Sie stellen ein Quellvideo und ein oder mehrere Referenzbilder bereit, formen den Anweisungstext, dann führt die Ausführungsgruppe einen zweiphasigen Bernini-Durchlauf durch, der zu Frames dekodiert und Ihr Ausgabenvideo zusammenstellt. Ein paralleles Dienstprogramm kann systematische und benutzerdefinierte Prompts für LLM-unterstütztes Prompt-Schreiben generieren.
Benutzereingabe#
Laden Sie Ihr Quellvideo mit VHS_LoadVideo (#90). Der Knoten liest den Clip und legt seine Metadaten offen, sodass das endgültige Rendern die ursprüngliche Bildrate erbt, was hilft, das Bewegungsgefühl zu bewahren. Fügen Sie ein oder mehrere Identitätsreferenzen mit LoadImage (#31) hinzu; frontal, gut beleuchtete Gesichter mit neutralen Ausdrücken funktionieren am besten. Legen Sie die Zielgröße mit Width (#109) und Height (#110) fest, idealerweise im Verhältnis zum Quellseitenverhältnis, um Streckungen zu vermeiden. Ein Standard-Negativprompt wird von CLIPTextEncode (#4) kodiert, um häufige Artefakte in Videos niedriger Qualität zu unterdrücken; Sie können ihn bei Bedarf verfeinern.
Prompt-Verarbeitung#
Wenn Sie möchten, dass die Anweisung genau mit der Referenzidentität übereinstimmt, kann der Graph statische Merkmale aus Ihren Referenzbildern mithilfe eines lokalen LLM zusammenfassen. llama_cpp_model_loader (#93) und llama_cpp_instruct_adv (#92) analysieren Bilder, die von BatchImagesNode (#74) gruppiert wurden, und geben eine prägnante Beschreibung unveränderlicher Attribute wie Haar, Alter und Kleidung zurück. Diese Beschreibung wird mit Ihrer Aufgabenanweisung von JjkText (#104) über TextConcatenate (#102) zusammengeführt. Das Ergebnis fließt in CLIPTextEncode (#3), was zur positiven Konditionierung für Bernini wird. Vorschauknoten zeigen den zusammengesetzten Text, sodass Sie schnell iterieren können, bevor Sie die schweren Phasen ausführen.
Prompt-Verbesserung#
BerniniPromptEnhancer (#60) generiert strukturierte „System“- und „Benutzer“-Prompts, die auf den ausgewählten Aufgabentyp und die Eingaben zugeschnitten sind. Führen Sie es aus, um stärkere Anweisungen zu erhalten, die Sie in Ihr LLM einfügen können, um reichere Prompterweiterungen zu erhalten; es ist absichtlich nicht in den Hauptgraphen verdrahtet. Dieses Dienstprogramm stammt aus dem Bernini-Benutzerknotenpaket: ComfyUI-RH-Bernini. Behandeln Sie es als ein Vorbereitungswerkzeug, um Sprache zu standardisieren, die gut mit Berninis Konditionierung funktioniert.
Ausführung#
Der Kernpfad beginnt mit dem Laden von Berninis HIGH und LOW UNets und dem Anbringen von LightX2V LoRAs für jede Phase. BerniniConditioning (#34) verbindet Ihre positiven und negativen Kodierungen, VAE, Quellvideoframes und Referenzbilder, um Bernini-spezifische Konditionierung und ein anfängliches Latent zu erstellen, das auf Ihre Auflösung und Frameanzahl abgestimmt ist. Ein BasicScheduler (#18) erstellt den Entrauchungsplan, dann teilt SplitSigmas (#17) ihn in HIGH- und LOW-Bereiche. Der HIGH-Sampler SamplerCustom (#19) stellt Struktur und Identität unter stärkerem Rauschen her und übergibt sein Latent an den LOW-Sampler SamplerCustom (#15) für Details und zeitlichen Feinschliff. KSamplerSelect (#27) wählt den Sampler-Algorithmus, VAEDecode (#16) verwandelt das endgültige Latent in Frames, und VHS_VideoCombine (#87) rendert ein MP4, das die Quellbildrate erbt. Parallel dazu erzeugen ImageConcanate (#97) und ein zweites VHS_VideoCombine (#96) einen Vergleich nebeneinander für schnelle Qualitätsprüfungen. Video-I/O und -Zusammenstellung werden von der Video Helper Suite bereitgestellt: ComfyUI-VideoHelperSuite.
Wichtige Knoten im Comfyui Bernini-Workflow für multimodale Videogenerierung und -bearbeitung#
BerniniConditioning (#34) Erstellt Bernini-native Konditionierung durch die Kombination Ihrer Textkodierungen, VAE, Quellvideo und Referenzbilder. Es bereitet auch das startende Latentvolumen vor und behandelt räumliche und zeitliche Größenanpassungen. Passen Sie width und height an, um Ihre Zielauflösung zu erreichen, und verwenden Sie length, um die Anzahl der generierten Frames zu steuern. Wenn das Referenzmotiv im Bild klein ist, erhöhen Sie ref_max_size, damit das Modell Identitätsdetails besser wahrnimmt. Dieser Knoten ist Teil des Bernini-Benutzerpakets: ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Wendet das LightX2V high_noise LoRA auf das HIGH-Backbone an. Das Erhöhen seines strength_model erhöht die Übereinstimmung mit der Referenz in der Strukturphase, nützlich, wenn die Silhouette oder grobe Merkmale des Motivs nicht mit dem Quellvideo übereinstimmen. Senken Sie es, wenn die Bearbeitung zu starr wird oder natürliche Bewegung unterdrückt. Verwenden Sie es im Tandem mit dem LOW-Stage LoRA, um Treue und Flüssigkeit auszugleichen.
LoraLoaderModelOnly (#29) Wendet das LightX2V low_noise LoRA auf das LOW-Backbone an. Dieses LoRA verfeinert Texturen wie Haar, Haut und Kleidung, während es die vom HIGH-Stadium festgelegte Bewegung beibehält. Wenn Identitätsdetails zwischen den Frames abdriften, erhöhen Sie die Stärke leicht; wenn Texturen überscharf oder überangepasst aussehen, reduzieren Sie sie. Zusammen mit dem HIGH-Stage LoRA bildet es ein komplementäres Paar.
SplitSigmas (#17) Teilt den Entrauchungsplan in HIGH- und LOW-Bereiche. Ein früherer Split führt zu sanfteren Bearbeitungen, die mehr vom ursprünglichen Video behalten, während ein späterer Split dem HIGH-Stadium mehr Einfluss für stärkere Ersetzungen gewährt. Passen Sie den Split an, wenn Sie Prompts oder LoRA-Stärken ändern, damit beide Stadien ausgewogen bleiben. Diese Steuerung ist besonders hilfreich für kamera-gesperrte, bewegungserhaltende Bearbeitungen.
KSamplerSelect (#27) Wählt den Sampler-Algorithmus, der von beiden Entrauchungsstadien verwendet wird. Einige Sampler begünstigen Stabilität und zeitliche Glätte, während andere Detail oder Geschwindigkeit betonen. Wenn Sie Flackern sehen, versuchen Sie einen Sampler, der für Konsistenz bekannt ist; wenn Sie zusätzliche Schärfe benötigen, versuchen Sie einen Algorithmus, der mehr Varianz einbringt. Behalten Sie dieselbe Wahl für beide Stadien, um vorhersehbares Verhalten zu gewährleisten.
VHS_VideoCombine (#87) Kodiert dekodierte Frames in ein endgültiges MP4, während es die Bildrate erbt, die von VHS_VideoInfo gemeldet wird, sodass die Wiedergabegeschwindigkeit mit dem Quellclip übereinstimmt. Verwenden Sie Dateinamenkontrollen, um Läufe zu organisieren, und aktivieren Sie die Metadatenspeicherung, wenn Sie planen, Einstellungen zu überprüfen. Eine zweite Instanz (#96) gibt einen Vergleich nebeneinander für schnelle visuelle Vergleiche aus. Bereitgestellt von ComfyUI-VideoHelperSuite.
Optionale Extras#
- Für identitätskritische Aufgaben stellen Sie zwei oder drei hochwertige Referenzbilder bereit, die konsistentes Haar, Beleuchtung und Ausdruck zeigen. Verwenden Sie die Batch-Eingabe, um sie zusammenzuführen.
- Halten Sie das Zielseitenverhältnis nahe am Quellvideo. Große Unterschiede können Gesichter strecken und die Bewegung destabilisieren.
- Wenn der Hintergrund oder die Kamera driftet, verstärken Sie die Sprache in Ihrer Anweisung, die die Kameraposition und die Szene fixiert, und verstärken Sie sie mit einem prägnanten Negativprompt.
- Verwenden Sie den Vergleich nebeneinander, wenn Sie LoRA-Stärken oder den Sigma-Split abstimmen. Es verkürzt die Iterationszeit, indem es Unterschiede offensichtlich macht.
- Für schnellere Tests begrenzen Sie die Anzahl der geladenen Frames, dann skalieren Sie auf, sobald Sie mit der Identitätsübereinstimmung und Bewegungsqualität zufrieden sind.
Dieser Bernini-Workflow für multimodale Videogenerierung und -bearbeitung ist so konzipiert, dass er sicher bearbeitet werden kann: Beginnen Sie mit den Standardeinstellungen, iterieren Sie die Anweisung und die Referenzen, dann feinabstimmen Sie die LoRA-Stärken und den Sigma-Split für Ihr Motiv und Ihre Szene.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken ByteDance für Bernini, RH-RunningHub für ComfyUI-RH-Bernini und Kosinkadink für ComfyUI-VideoHelperSuite für ihre Beiträge und Wartung. Für autoritative Details, konsultieren Sie bitte die Originaldokumentation und -repositories, die unten verlinkt sind.
Ressourcen#
- RunningHub/Bernini Multimodale Videogenerierung und -bearbeitung (ComfyUI-Workflow)
- Docs / Release Notes: RunningHub Workflow-Referenz
- RunComfy/Cloud Save Workflow
- Docs / Release Notes: RunComfy Cloud Save Workflow
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- Docs / Release Notes: ByteDance Bernini Modellquelle
- Kijai/WanVideo_comfy_fp8_scaled (Bernini Assets)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- Docs / Release Notes: Kijai Bernini ComfyUI fp8 Modell-Assets
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- Docs / Release Notes: RunComfy Bernini Benutzerdefinierte Knoten
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- Docs / Release Notes: ComfyUI Video Helper Suite
Hinweis: Die Nutzung der genannten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.

