






你好,AI愛好者們!👋 歡迎來到我們關於在ComfyUI中使用FLUX的介紹指南。FLUX是由Black Forest Labs開發的前沿模型。🌟 在本教學中,我們將深入探討ComfyUI FLUX的基本知識,展示這個強大模型如何提升你的創作流程,並協助你突破AI生成藝術的界限。🚀
我們將涵蓋:
- 1. FLUX簡介
- 2. FLUX的不同版本
- 3. FLUX硬體需求
- 3.1. FLUX.1 [Pro] 硬體需求
- 3.2. FLUX.1 [Dev] 硬體需求
- 3.3. FLUX.1 [Schnell] 硬體需求
- 4. 如何在ComfyUI中安裝FLUX
- 4.1. 安裝或更新ComfyUI
- 4.2. 下載ComfyUI FLUX文字編碼器與CLIP模型
- 4.3. 下載FLUX.1 VAE模型
- 4.4. 下載FLUX.1 UNET模型
- 5. ComfyUI FLUX工作流程 | 下載、線上訪問與使用指南
- 5.1. ComfyUI工作流程:FLUX Txt2Img
- 5.2. ComfyUI工作流程:FLUX Img2Img
- 5.3. ComfyUI工作流程:FLUX LoRA
- 5.4. ComfyUI工作流程:FLUX ControlNet
- 5.5. ComfyUI工作流程:FLUX 修復
- 5.6. ComfyUI工作流程:FLUX NF4與Upscale
- 5.7. ComfyUI工作流程:FLUX IPAdapter
- 5.8. ComfyUI工作流程:Flux LoRA訓練器
- 5.9. ComfyUI工作流程:Flux 潛變量Upscale
1. FLUX簡介#
FLUX.1是由Black Forest Labs開發的尖端AI模型,正重新定義我們如何從文字描述創造圖像。憑藉其卓越的能力,FLUX.1能夠生成與輸入提示高度匹配的驚人細緻且複雜的圖像,使其在眾多模型中脫穎而出。FLUX.1成功的關鍵在於其獨特的混合式架構,結合了多種類型的Transformer模組,並由強大的120億參數驅動。這讓FLUX.1能夠生成視覺上令人驚艷的圖像,並精準呈現文字所描述的內容。
FLUX.1最令人興奮的特色之一是它在生成各種風格圖像方面的多功能性,從寫實風格到藝術風格皆具備。FLUX.1甚至擁有將文字無縫整合進圖像的卓越能力,這是許多其他模型難以實現的壯舉。此外,FLUX.1以其優異的提示遵循能力而聞名,無論是簡單還是複雜的描述都能輕鬆處理。因此FLUX.1常被拿來與Stable Diffusion和Midjourney等知名模型比較,並因其使用友善與卓越成果而成為首選。
FLUX.1的強大能力使其成為應用廣泛的寶貴工具,從創作令人驚艷的視覺內容、激發創意設計,到協助科學可視化。FLUX.1能夠根據文字描述生成高度細緻與精確的圖像,為創作者、研究人員與愛好者開啟了無限的可能。隨著AI生成圖像技術的持續進化,FLUX.1站在最前線,樹立了品質、多樣性與易用性的全新標竿。
Black Forest Labs是開發FLUX.1的先驅AI公司,由AI產業知名人物Robin Rombach創立,他曾是Stability AI的核心成員。如果你想進一步了解Black Forest Labs與FLUX.1的革命性工作,歡迎造訪他們的官方網站:https://blackforestlabs.ai/

2. FLUX的不同版本#
FLUX.1擁有三個不同的版本,每個版本皆針對特定使用者需求設計:
- FLUX.1 [pro]:頂級版本,提供最佳畫質與效能,特別適合專業用途與高端專案。
- FLUX.1 [dev]:針對非商業用途進行優化,保有高品質輸出,效能更為高效,非常適合開發者與愛好者使用。
- FLUX.1 [schnell]:著重於速度與輕量化的版本,非常適合本機開發與個人專案。該版本為開源,並遵循Apache 2.0授權條款,對所有用戶友善開放。
| 名稱 | HuggingFace倉庫 | 授權 | md5sum |
FLUX.1 [pro] |
僅透過我們的API提供。 | ||
FLUX.1 [dev] |
https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev 非商業授權 | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] |
https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. FLUX硬體要求#
3.1. FLUX.1 [Pro] 硬體要求#
- 推薦GPU:NVIDIA RTX 4090或同等配置,擁有24 GB或更多VRAM。此模型針對高階GPU進行最佳化,以處理其複雜的操作。
- 記憶體:32 GB或更多系統記憶體。
- 磁碟空間:約30 GB。
- 運算需求:需要高精度;使用FP16(半精度)以避免記憶體不足錯誤。為了獲得最佳效果,建議使用
fp16Clip模型變體以達成最高品質。 - 其他要求:建議使用高速SSD以加快載入時間與整體效能。
3.2. FLUX.1 [Dev] 硬體要求#
- 推薦GPU:NVIDIA RTX 3080/3090或同等配置,至少擁有16 GB VRAM。與Pro模型相比,此版本對硬體要求稍微寬鬆,但仍需要相當的GPU效能。
- 記憶體:16 GB或更多系統記憶體。
- 磁碟空間:約25 GB。
- 運算需求:與Pro相似,使用FP16模型,但對較低精度計算有輕微容忍度。可依據GPU能力選擇使用
fp16或fp8Clip模型。 - 其他要求:建議使用高速SSD以獲得最佳效能。
3.3. FLUX.1 [Schnell] 硬體要求#
- 推薦GPU:NVIDIA RTX 3060/4060或同等配置,擁有12 GB VRAM。此版本針對更快推論及較低硬體需求進行最佳化。
- 記憶體:8 GB或更多系統記憶體。
- 磁碟空間:約15 GB。
- 運算需求:此版本要求較低,允許使用
fp8運算以避免記憶體不足。設計上著重於快速與效率,重點在速度而非極致品質。 - 其他要求:SSD 有助提升效能,但不像 Pro 與 Dev 版本那樣關鍵。
4. 如何在ComfyUI中安裝FLUX#
4.1. 安裝或更新ComfyUI#
要在ComfyUI環境中有效使用FLUX.1,關鍵在於確保安裝最新版本的ComfyUI。此版本支援FLUX.1模型所需的必要功能與整合。
4.2. 下載ComfyUI FLUX文本編碼器和CLIP模型#
為了使用FLUX.1實現最佳效能與精確的文字轉圖像生成,你需要下載特定的文本編碼器與CLIP模型。根據你的系統硬體,以下模型是必要的:
下載與安裝步驟:
- 下載
clip_l.safetensors模型。 - 根據你的系統VRAM與RAM,下載
t5xxl_fp8_e4m3fn.safetensors(適用於較低VRAM)或t5xxl_fp16.safetensors(適用於較高VRAM與RAM)。 - 將下載的模型放置於
ComfyUI/models/clip/目錄中。注意:如果你曾經使用過SD 3 Medium,可能已經擁有這些模型。
4.3. 下載 FLUX.1 VAE 模型#
變分自編碼器(VAE)模型對於提升FLUX.1的圖像生成品質至關重要。以下為可供下載的VAE模型:
| 檔案名稱 | 大小 | 連結 |
ae.safetensors |
335 MB | 下載(在新分頁開啟) |
下載與安裝步驟:
- 下載
ae.safetensors模型檔案。 - 將下載的檔案放置於
ComfyUI/models/vae目錄中。 - 為了方便識別,建議將檔案重新命名為
flux_ae.safetensors。
4.4. 下載 FLUX.1 UNET 模型#
UNET模型是FLUX.1中圖像合成的核心。根據系統規格,可選擇不同的變體:
下載與安裝步驟:
- 根據系統的記憶體配置下載相應的UNET模型。
- 將下載的模型檔案放置於
ComfyUI/models/unet/目錄中。
5. ComfyUI FLUX 工作流 | 下載、線上訪問與指南#
我們將持續更新 ComfyUI FLUX 工作流,為你提供最新與最完整的工作流程,以使用 ComfyUI FLUX 生成令人驚豔的圖像。
5.1. ComfyUI 工作流:FLUX Txt2Img#
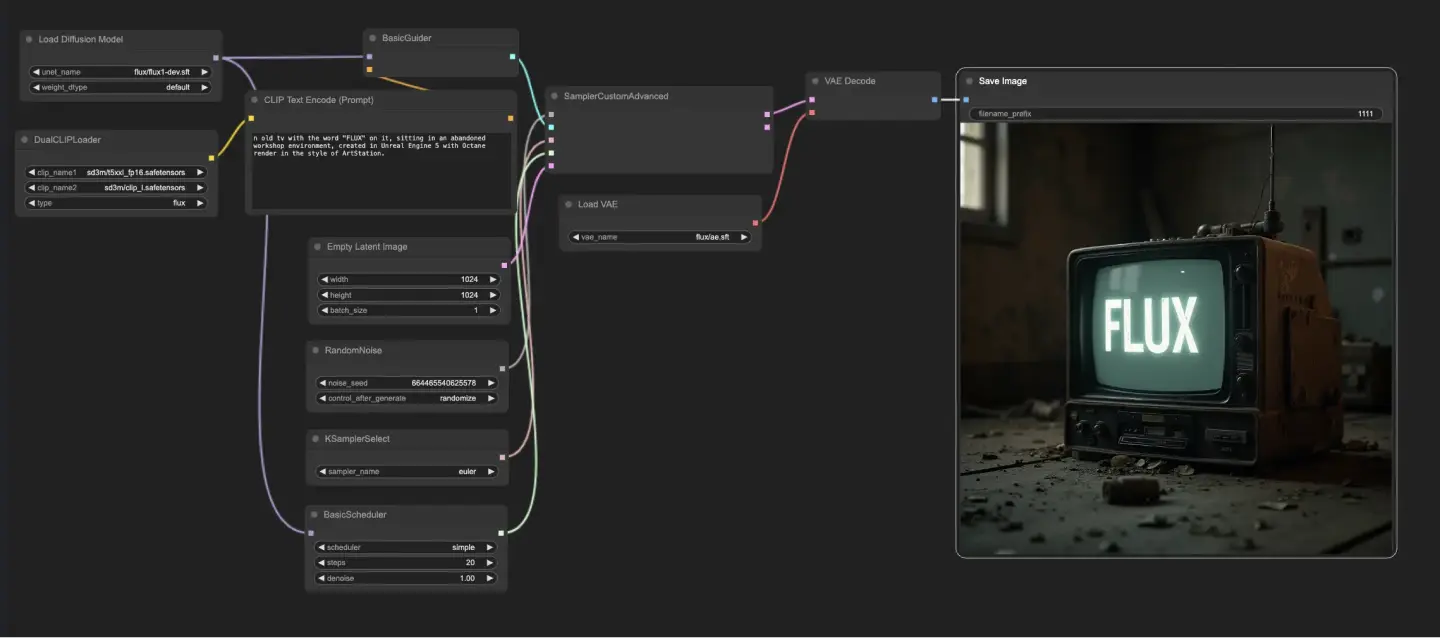
5.1.1. ComfyUI FLUX Txt2Img : <a href="https://cdn.runcomfy.net/tutorial_download/162/01.json" target="_blank">下載</a>#
5.1.2. ComfyUI FLUX Txt2Img 線上版本:ComfyUI FLUX Txt2Img#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX Txt2Img 的體驗。
5.1.3. ComfyUI FLUX Txt2Img 說明:#
ComfyUI FLUX Txt2Img 工作流首先載入基本組件,包括 FLUX UNET(UNETLoader)、FLUX CLIP(DualCLIPLoader)以及 FLUX VAE(VAELoader)。這些構成了 ComfyUI FLUX 圖像生成過程的基礎。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:載入用於文字編碼的 CLIP 模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分組:CLIP 模型的分組策略為 flux
- VAELoader:載入用於解碼潛在表示的變分自編碼器(VAE)模型。
- VAE 模型:flux/ae.sft
文字提示(prompt)描述了所需的輸出,透過 CLIPTextEncode 進行編碼。此節點將文字提示作為輸入,輸出編碼後的文本條件,在生成過程中引導 ComfyUI FLUX。
要啟動 ComfyUI FLUX 的生成流程,可使用 EmptyLatentImage 創建空的潛在表示。這是 ComfyUI FLUX 的起始點。
BasicGuider 在生成過程中扮演關鍵角色。它將編碼的文本條件與已載入的 FLUX UNET 作為輸入,確保生成的輸出與所提供的文字描述一致。
KSamplerSelect 允許你選擇 ComfyUI FLUX 的取樣方法,而 RandomNoise 則產生作為輸入的隨機噪聲。BasicScheduler 則在生成流程中為每個步驟調度噪聲等級(sigmas),控制最終輸出的細節與清晰度。
SamplerCustomAdvanced 將所有組件整合起來。它以隨機噪聲、指導條件、選定的取樣器、已排程的 sigmas 和空的潛在表示作為輸入,透過進階取樣程序生成一個對應於文字提示的潛在表示。
最後,VAEDecode 使用載入的 FLUX VAE 將生成的潛在表示解碼為最終圖像。SaveImage 則讓你將生成結果保存至指定位置,保留由 ComfyUI FLUX Txt2Img 所創造的驚艷作品。
5.2. ComfyUI 工作流:FLUX Img2Img#
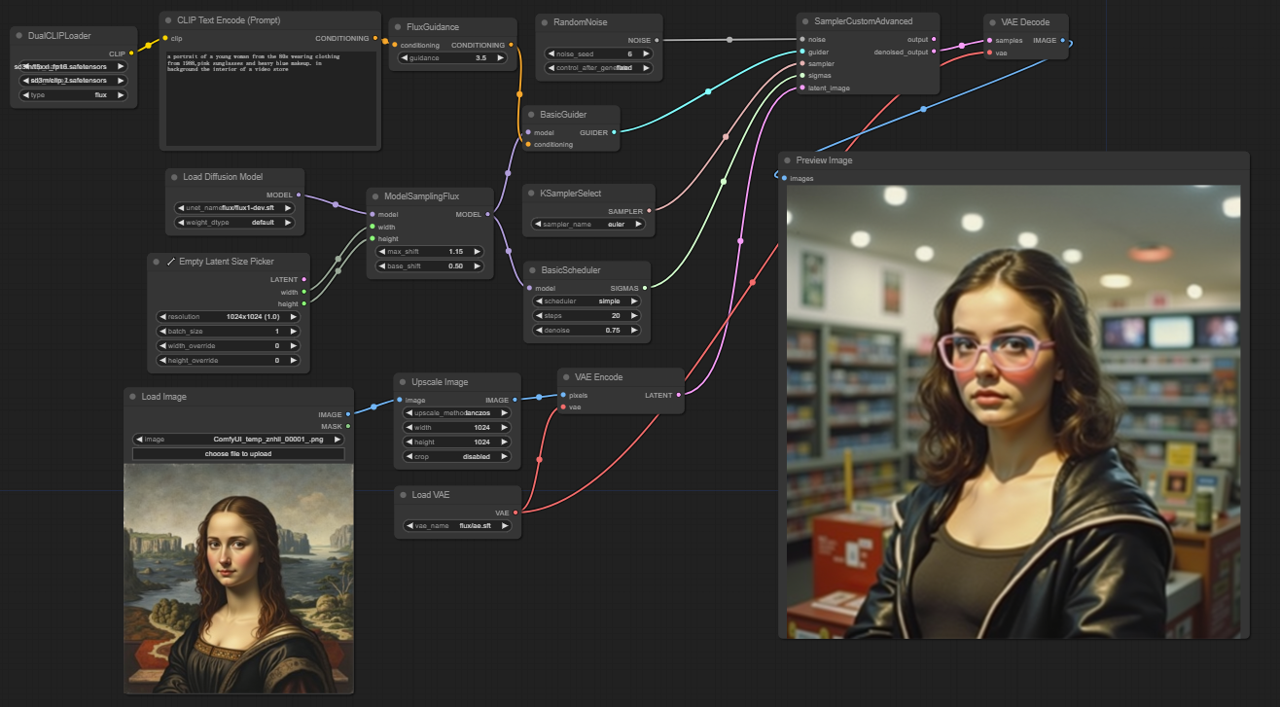
5.2.1. ComfyUI FLUX Img2Img : <a href="https://cdn.runcomfy.net/tutorial_download/162/02.json" target="_blank">下載</a>#
5.2.2. ComfyUI FLUX Img2Img 線上版本:ComfyUI FLUX Img2Img#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX Img2Img 的體驗。
5.2.3. ComfyUI FLUX Img2Img 說明:#
ComfyUI FLUX Img2Img 工作流基於 FLUX 的強大功能,根據文字提示與輸入圖像生成輸出。它會首先載入必要的組件,包括 CLIP 模型(DualCLIPLoader)、UNET 模型(UNETLoader)以及 VAE 模型(VAELoader)。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:載入用於文字編碼的 CLIP 模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分組:CLIP 模型的分組策略為 flux
- VAELoader:載入用於解碼潛在表示的變分自編碼器(VAE)模型。
- VAE 模型:flux/ae.sft
輸入圖像作為 ComfyUI FLUX Img2Img 的起點,透過 LoadImage 節點載入。ImageScale 接著將圖像縮放至所需尺寸,以確保相容性。
縮放後的圖像使用 VAEEncode 進行編碼,轉換為潛在表示。這個潛在表示捕捉了輸入圖像的核心特徵與細節,為後續流程提供基礎。
描述想要修改或增強的文字提示,透過 CLIPTextEncode 進行編碼。FluxGuidance 根據指定的指導強度套用提示,影響文字對最終結果的影響程度。
ModelSamplingFlux 設定 ComfyUI FLUX 的取樣參數,包括時間步重取樣、填充比例與輸出維度。這些參數控制輸出影像的細節程度與解析度。
KSamplerSelect 允許你選擇取樣方法,而 BasicGuider 根據編碼的文字提示與已載入的 FLUX UNET 指導整個生成流程。
使用 RandomNoise 產生隨機噪聲,BasicScheduler 則調度生成過程中的噪聲等級(sigmas),以引入控制變化並微調輸出細節。
SamplerCustomAdvanced 整合隨機噪聲、指導條件、取樣器選擇、sigmas 排程與輸入潛在表示,透過進階取樣過程生成新的潛在表示,融合提示所指定的修改,同時保留輸入圖像的基本特徵。
最後,VAEDecode 使用 FLUX VAE 將潛在表示解碼為圖像結果,PreviewImage 則會顯示最終預覽,展現由 ComfyUI FLUX Img2Img 實現的精彩效果。
5.3. ComfyUI 工作流:FLUX LoRA#
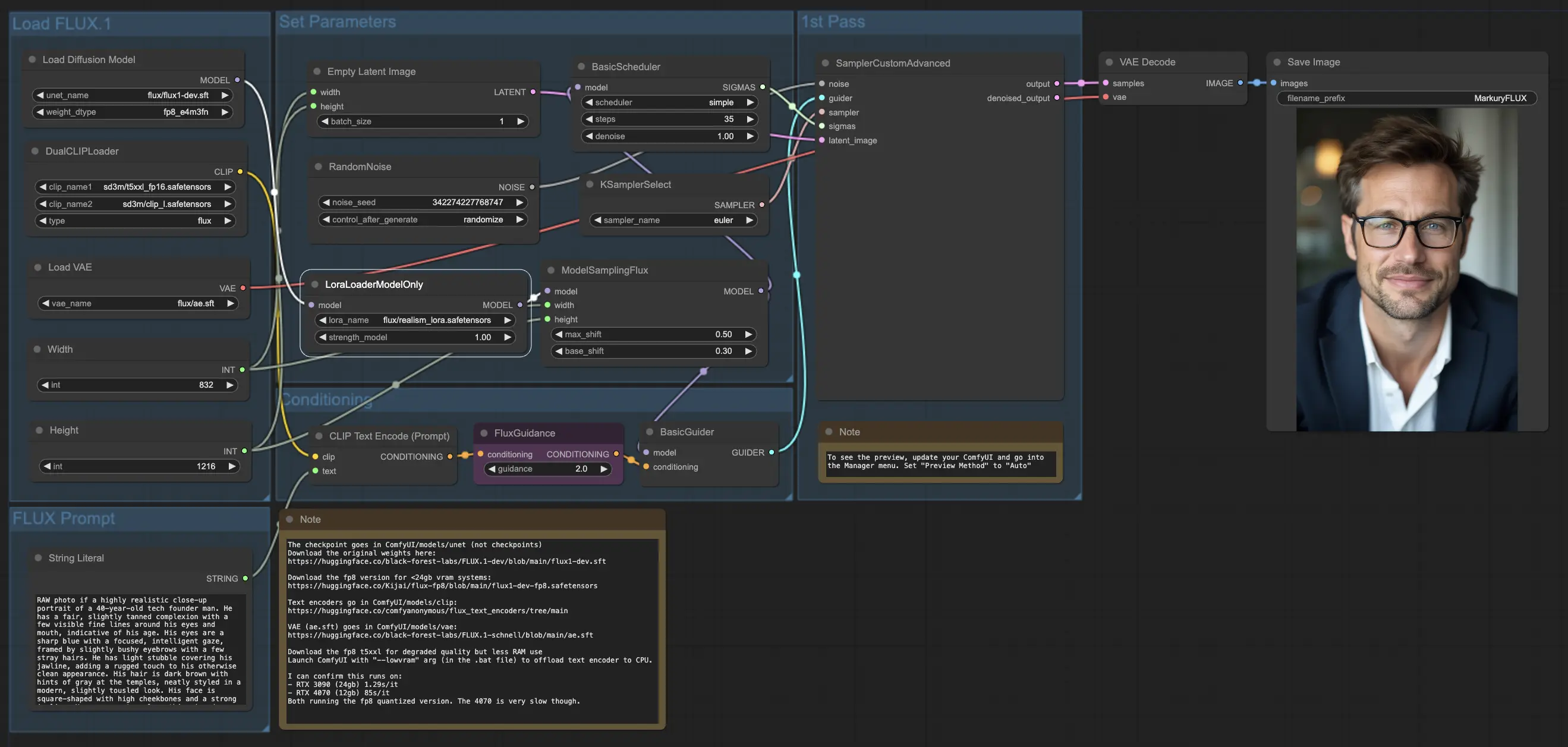
5.3.1. ComfyUI FLUX LoRA: <a href="https://cdn.runcomfy.net/tutorial_download/162/03.json" target="_blank">下載</a>#
5.3.2. ComfyUI FLUX LoRA 線上版本:ComfyUI FLUX LoRA#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX LoRA 的體驗。
5.3.3. ComfyUI FLUX LoRA 說明:#
ComfyUI FLUX LoRA 工作流利用低秩適應(LoRA)的強大功能來增強 ComfyUI FLUX 的效能。它會首先載入必要的組件,包括 UNET 模型(UNETLoader)、CLIP 模型(DualCLIPLoader)、VAE 模型(VAELoader)與 LoRA 模型(LoraLoaderModelOnly)。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:flux/flux1-dev.sft
- DualCLIPLoader:載入用於文字編碼的 CLIP 模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分組:CLIP 模型的分組策略為 flux
- VAELoader:載入用於解碼潛在表示的變分自編碼器(VAE)模型。
- VAE 模型:flux/ae.sft
- LoraLoaderModelOnly:載入用於增強 UNET 模型的 LoRA(低秩適應)模型。
- LoaderModel:flux/realism_lora.safetensors
描述所需輸出的文字提示使用 String Literal 指定。CLIPTextEncode 隨後會對文字提示進行編碼,生成引導 ComfyUI FLUX 生成流程的編碼文字條件。
FluxGuidance 對這些編碼後的文字條件應用指導,影響 ComfyUI FLUX 對提示的遵循度與方向。
使用 EmptyLatentImage 創建空的潛在表示作為生成的起始點。使用 Int Literal 指定輸出圖像的寬度與高度,以確保最終結果的所需尺寸。
ModelSamplingFlux 設定 ComfyUI FLUX 的取樣參數,包括填充比例與時間步重取樣。這些參數控制生成結果的解析度與細節粒度。
KSamplerSelect 允許你選擇 ComfyUI FLUX 的取樣方法,而 BasicGuider 根據編碼後的文字條件與已載入的 FLUX UNET(已透過 FLUX LoRA 增強)來引導生成過程。
使用 RandomNoise 產生隨機噪聲,BasicScheduler 調度生成過程中的噪聲等級(sigmas)。這些元件引入可控的變化並微調最終輸出。
SamplerCustomAdvanced 將隨機噪聲、指導條件、選定取樣器、sigmas 調度與空的潛在表示整合。透過進階取樣流程,它會生成一個代表文字提示內容的潛在表示,結合 FLUX 與 FLUX LoRA 的強大能力。
最後,VAEDecode 使用已載入的 FLUX VAE 將潛在表示解碼為最終圖像。SaveImage 則允許你將生成結果保存至指定位置,保留由 ComfyUI FLUX LoRA 工作流創作的驚艷圖像。
5.4. ComfyUI 工作流:FLUX ControlNet#
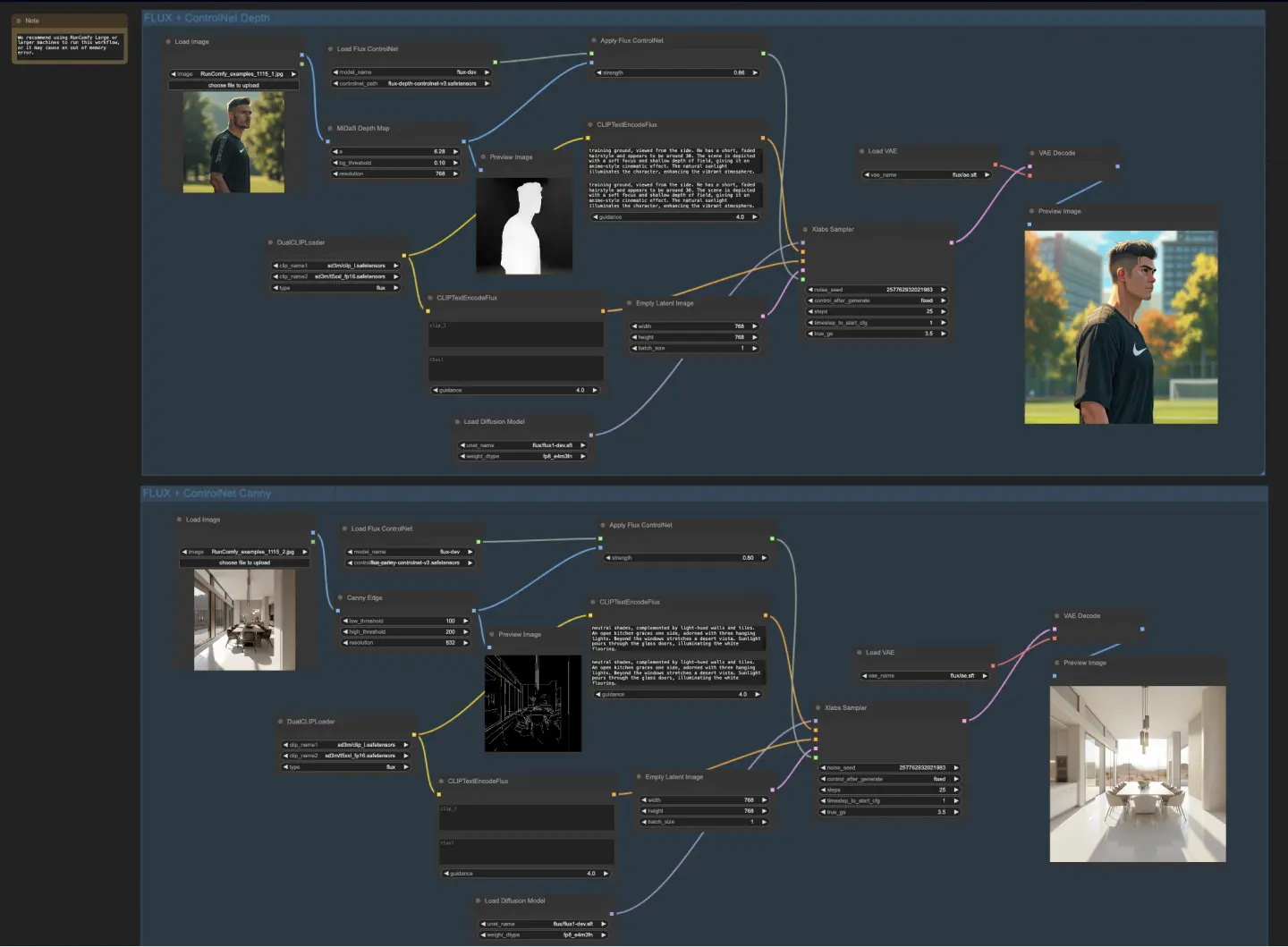
5.4.1. ComfyUI FLUX ControlNet: <a href="https://cdn.runcomfy.net/tutorial_download/162/04.json" target="_blank">下載</a>#
5.4.2. ComfyUI FLUX ControlNet 線上版本:ComfyUI FLUX ControlNet#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX ControlNet 的體驗。
5.4.3. ComfyUI FLUX ControlNet 說明:#
ComfyUI FLUX ControlNet 工作流展示了 ControlNet 與 ComfyUI FLUX 的整合能力,以增強生成輸出的控制力。工作流展示了兩個範例:基於深度的條件與基於 Canny 邊緣的條件。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:flux/flux1-dev.sft
- DualCLIPLoader:載入用於文字編碼的 CLIP 模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分組:CLIP 模型的分組策略為 flux
- VAELoader:載入用於解碼潛在表示的變分自編碼器(VAE)模型。
- VAE 模型:flux/ae.sft
在基於深度的工作流中,輸入圖像透過 MiDaS-DepthMapPreprocessor 進行預處理,生成深度圖。接著,該深度圖透過 ApplyFluxControlNet(Depth)與已載入的 FLUX ControlNet 進行深度條件處理。所產生的 FLUX ControlNet 條件作為 XlabsSampler(Depth)的輸入,結合已載入的 FLUX UNET、編碼的文字提示、負面提示與空潛在表示。XlabsSampler 根據這些輸入生成潛在表示,最終透過 VAEDecode 解碼為圖像輸出。
- MiDaS-DepthMapPreprocessor(Depth):使用 MiDaS 對輸入圖像進行深度預估。
- LoadFluxControlNet:載入 ControlNet 模型。
- 路徑:flux-depth-controlnet.safetensors
同樣地,在基於 Canny 邊緣的工作流中,輸入圖像經由 CannyEdgePreprocessor 預處理,生成 Canny 邊緣圖像。然後透過 ApplyFluxControlNet(Canny)與已載入的 FLUX ControlNet 結合進行條件處理。所產生的 ControlNet 條件作為 XlabsSampler(Canny)的輸入,並與已載入的 FLUX UNET、編碼的文字提示、負面提示與空潛在表示結合。XlabsSampler 根據這些資料生成潛在表示,並透過 VAEDecode 解碼為最終輸出。
- CannyEdgePreprocessor(Canny):對輸入圖像執行 Canny 邊緣檢測。
- LoadFluxControlNet:載入 ControlNet 模型。
- 路徑:flux-canny-controlnet.safetensors
ComfyUI FLUX ControlNet 工作流包含一系列節點,用於載入必要元件(DualCLIPLoader、UNETLoader、VAELoader、LoadFluxControlNet)、編碼提示(CLIPTextEncodeFlux)、創建潛在表示(EmptyLatentImage)與預覽結果(PreviewImage)。
透過善用 FLUX ControlNet 的強大能力,ComfyUI FLUX ControlNet 工作流能生成符合特定條件(如深度圖或 Canny 邊緣圖)的輸出。這種額外的控制與引導提升了生成過程的靈活性與精準度,讓你能創作出令人驚嘆且符合背景語意的結果。
5.5. ComfyUI 工作流:FLUX 修復#
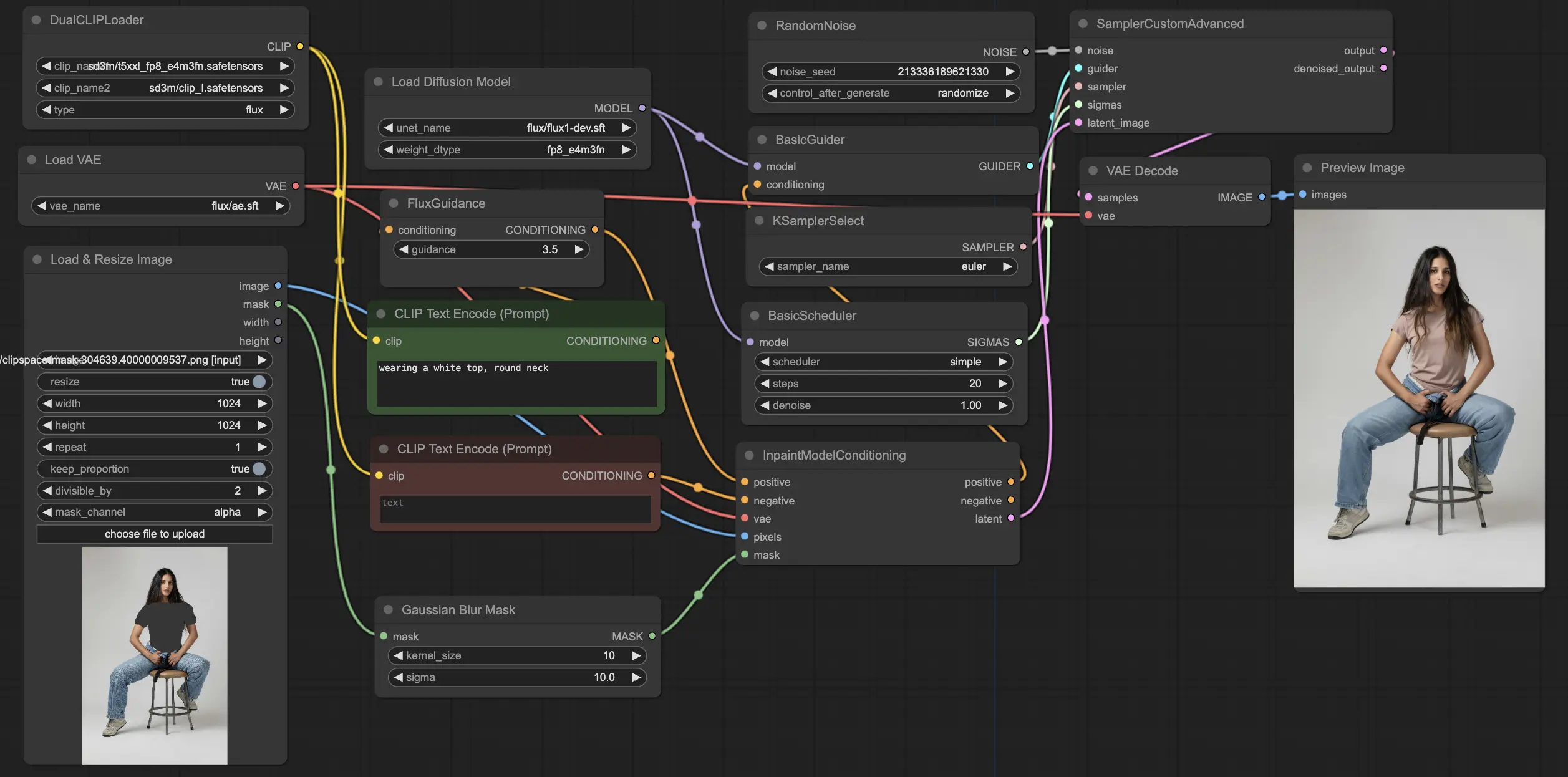
5.5.1. ComfyUI FLUX Inpainting: <a href="https://cdn.runcomfy.net/tutorial_download/162/05.json" target="_blank">下載</a>#
5.5.2. ComfyUI FLUX Inpainting 線上版本:ComfyUI FLUX Inpainting#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX Inpainting 的體驗。
5.5.3. ComfyUI FLUX Inpainting 說明:#
ComfyUI FLUX Inpainting 工作流展示了 FLUX 執行圖像修復的能力,能根據周圍上下文與所提供的文字提示,填補缺失或遮蔽區域。此工作流首先載入必要的組件,包括 UNET 模型(UNETLoader)、VAE 模型(VAELoader)與 CLIP 模型(DualCLIPLoader)。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:載入用於文字編碼的 CLIP 模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分組:CLIP 模型的分組策略為 flux
- VAELoader:載入用於解碼潛在表示的變分自編碼器(VAE)模型。
- VAE 模型:flux/ae.sft
正向與負向文字提示,用於描述修復區域的風格與內容,透過 CLIPTextEncodes 進行編碼。正向條件接著透過 FluxGuidance 進行指導,以影響 ComfyUI FLUX 的修復流程。
使用 LoadAndResizeImage 載入與調整輸入圖像與遮罩的尺寸,以符合 ComfyUI FLUX 的需求。ImpactGaussianBlurMask 對遮罩套用高斯模糊,使修復區域與原圖平滑銜接。
InpaintModelConditioning 結合已指導的正向條件、編碼的負向條件、已載入的 FLUX VAE、處理後的輸入圖像與遮罩,為 FLUX 修復建立必要條件。
接著,使用 RandomNoise 生成隨機噪聲,KSamplerSelect 選擇採樣方法。BasicScheduler 在修復過程中調度噪聲等級(sigmas),以控制修復區域的細節與清晰度。
BasicGuider 根據所準備的條件與已載入的 FLUX UNET,指導整個修復流程。SamplerCustomAdvanced 執行進階採樣程序,使用隨機噪聲、指導條件、選定的採樣器、sigmas 調度與潛在表示,輸出修復後的潛在表示。
最後,VAEDecode 使用已載入的 FLUX VAE 將潛在表示解碼為最終輸出,實現修補與原圖的自然融合。PreviewImage 顯示最終結果,展示 FLUX 在圖像修復方面令人印象深刻的能力。
透過 FLUX 的強大功能與精心設計的修復工作流,FLUX Inpainting 可產生視覺一致且符合語境的修復結果。無論是修補缺失區域、移除不必要物體或是修改特定內容,ComfyUI FLUX 修復工作流都提供強大工具。
5.6. ComfyUI 工作流:FLUX NF4#
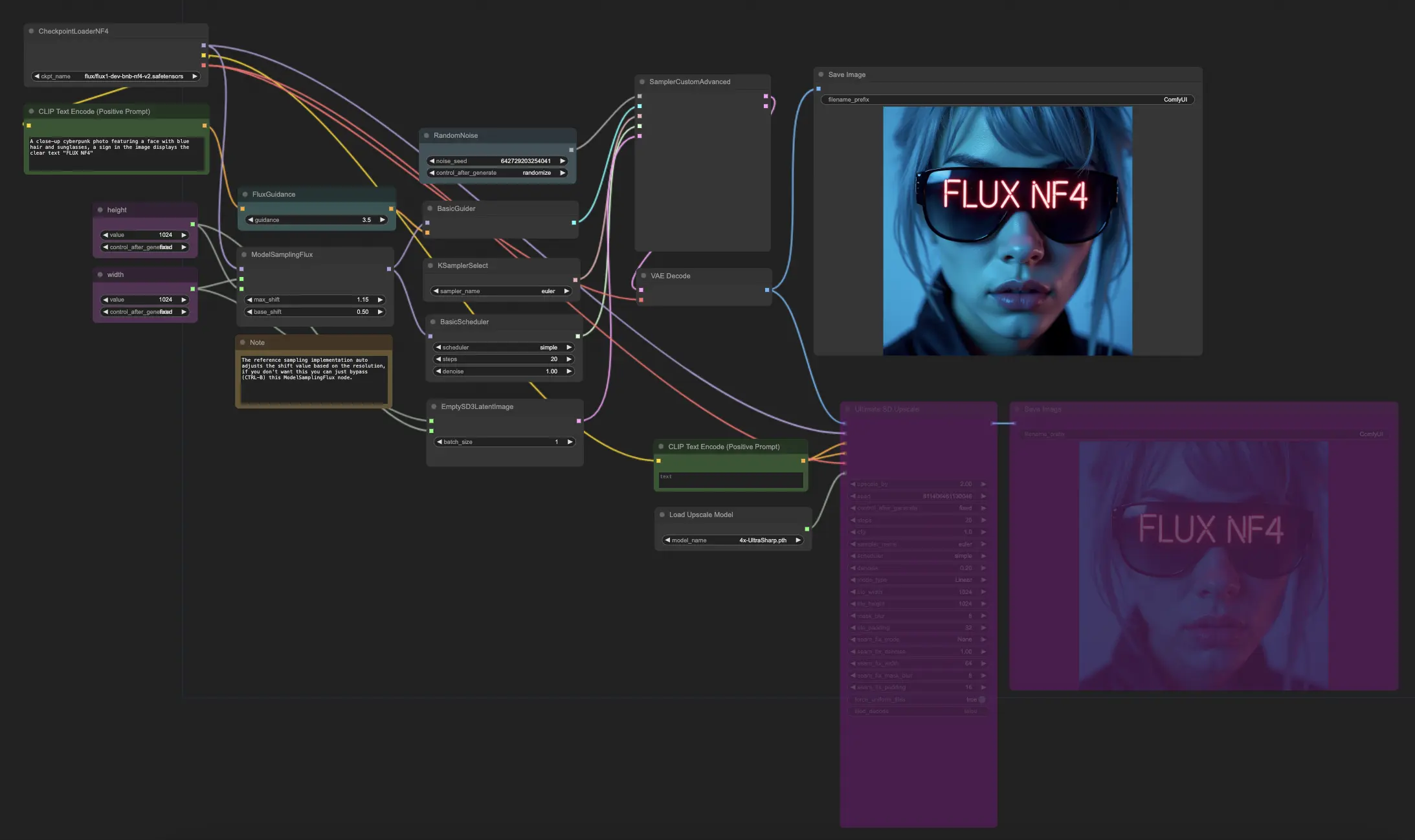
5.6.1. ComfyUI FLUX NF4: <a href="https://cdn.runcomfy.net/tutorial_download/162/06.json" target="_blank">下載</a>#
5.6.2. ComfyUI FLUX NF4 線上版本:ComfyUI FLUX NF4#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX NF4 的體驗。
5.6.3. ComfyUI FLUX NF4 說明:#
ComfyUI FLUX NF4 工作流展示了 FLUX 與 NF4(Normalizing Flow 4)架構的整合,實現高品質輸出。工作流首先使用 CheckpointLoaderNF4 載入必要元件,包括 FLUX UNET、FLUX CLIP 與 FLUX VAE。
- UNETLoader:載入用於圖像生成的 UNET 模型。
- 檢查點:TBD
PrimitiveNode(高度)與 PrimitiveNode(寬度)節點用來指定輸出的高度與寬度。ModelSamplingFlux 根據所載入的 UNET 與指定的尺寸,設定 ComfyUI FLUX 的採樣參數。
EmptySD3LatentImage 創建空的潛在表示,作為生成的起點。BasicScheduler 排程生成過程中的噪聲等級(sigmas)。
RandomNoise 產生隨機噪聲。BasicGuider 根據條件對生成過程進行指導。
KSamplerSelect 選擇採樣方法,SamplerCustomAdvanced 執行進階採樣流程,輸入包含:隨機噪聲、指導條件、選擇的採樣器、sigmas 與空的潛在表示,並輸出最終潛在表示。
VAEDecode 使用已載入的 FLUX VAE 解碼潛在表示為最終圖像。SaveImage 將結果儲存至指定位置。
若需放大,可使用 UltimateSDUpscale。它結合輸出圖像、已載入的 FLUX 模型、正向與負向放大提示、FLUX VAE 與 FLUX 放大模型。CLIPTextEncode(Upscale Positive Prompt)會對正向提示進行編碼。UpscaleModelLoader 載入 FLUX 放大模型。UltimateSDUpscale 執行放大流程,最後由 SaveImage(Upscaled) 將圖像儲存。
透過結合 FLUX 與 NF4 架構的強大效能,ComfyUI FLUX NF4 工作流可產出具真實感與高保真度的優質結果。FLUX 與 NF4 的無縫整合為創作提供極具力量的工具。
5.7. ComfyUI 工作流:FLUX IPAdapter#
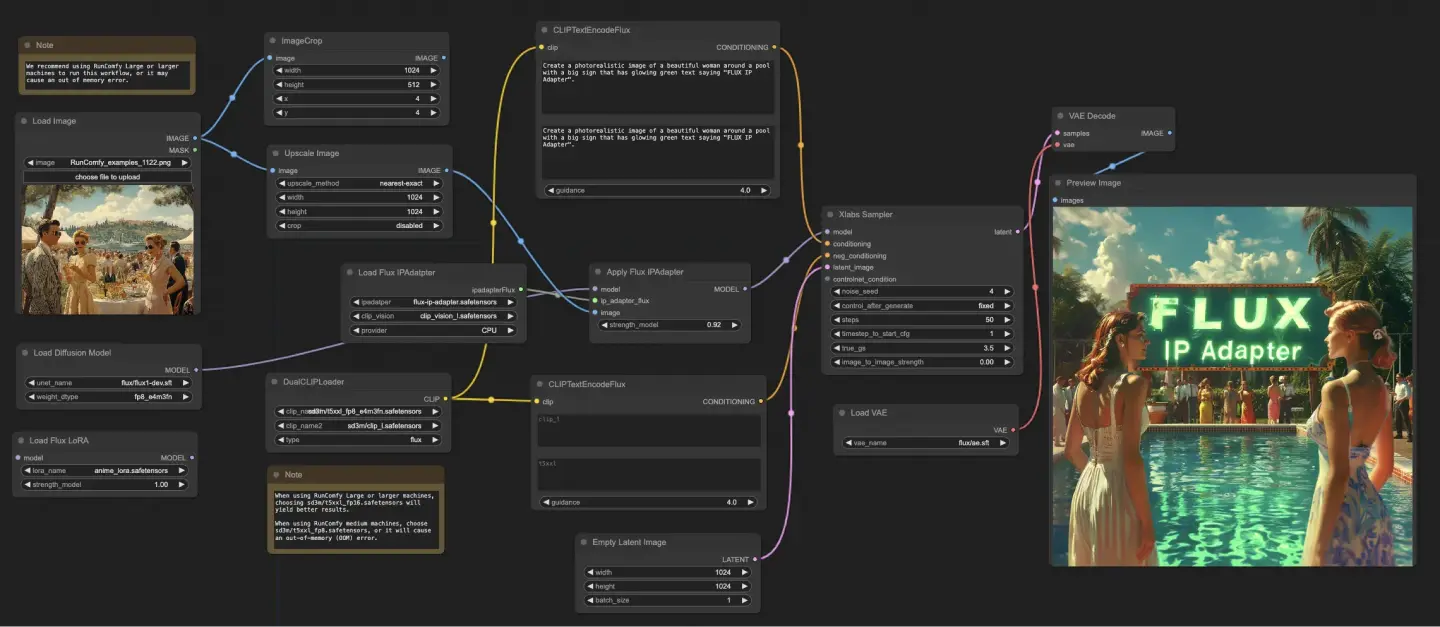
5.7.1. ComfyUI FLUX IPAdapter: <a href="https://cdn.runcomfy.net/tutorial_download/162/07.json" target="_blank">下載</a>#
5.7.2. ComfyUI FLUX IPAdapter 線上版本:ComfyUI FLUX IPAdapter#
在 RunComfy 平台,我們的線上版本預先載入了所有必要的模型與節點。此外,我們提供高效能 GPU 機器,確保你能輕鬆享受 ComfyUI FLUX IPAdapter 的體驗。
5.7.3. ComfyUI FLUX IPAdapter 說明:#
ComfyUI FLUX IPAdapter 工作流首先載入必要的模型,包括 UNET 模型(UNETLoader)、CLIP 模型(DualCLIPLoader)和 VAE 模型(VAELoader)。
正向與負向的文字提示使用 CLIPTextEncodeFlux 進行編碼。正向文本條件用於指導 ComfyUI FLUX 的生成流程。
使用 LoadImage 載入輸入圖像。LoadFluxIPAdapter 用於載入 FLUX 模型的 IP-Adapter,並透過 ApplyFluxIPAdapter 應用至已載入的 UNET 模型。ImageScale 將輸入圖像縮放至所需尺寸,再進行 IP-Adapter 的應用。
- LoadFluxIPAdapter:載入 FLUX 模型的 IP-Adapter。
- IP Adapter 模型:flux-ip-adapter.safetensors
- CLIP 視覺編碼器:clip_vision_l.safetensors
EmptyLatentImage 用來建立一個空的潛在表示,作為 ComfyUI FLUX 生成的起點。
XlabsSampler 執行採樣流程,將套用 IP-Adapter 的 FLUX UNET、編碼的正向與負向提示,以及空的潛在表示作為輸入,生成潛在表示。
VAEDecode 使用已載入的 FLUX VAE 將潛在表示解碼為最終圖像輸出。PreviewImage 節點顯示最終預覽。
ComfyUI FLUX IPAdapter 工作流結合 FLUX 與 IP-Adapter 的強大能力,能根據提供的文字提示生成高品質輸出。透過將 IP-Adapter 應用於 FLUX UNET,該工作流可產出高度貼合文字條件特徵與風格的影像。
5.8. ComfyUI 工作流:Flux LoRA 訓練器#

5.8.1. ComfyUI FLUX LoRA 訓練器: <a href="https://cdn.runcomfy.net/tutorial_download/162/08.json" target="_blank">下載</a>#
5.8.2. ComfyUI FLUX LoRA 訓練器說明:#
ComfyUI FLUX LoRA 訓練器工作流由多個階段組成,用於在 ComfyUI 中基於 FLUX 架構進行 LoRA 訓練。
ComfyUI FLUX 選擇與配置: FluxTrainModelSelect 節點用於選擇訓練所需的組件,包括 UNET、VAE、CLIP 和 CLIP 文字編碼器。 OptimizerConfig 節點配置訓練的優化器設定,例如優化器類型、學習率與權重衰減。 TrainDatasetGeneralConfig 與 TrainDatasetAdd 節點用於設定訓練資料集,包括解析度、資料增強與批次大小等。
ComfyUI FLUX 訓練初始化: InitFluxLoRATraining 節點利用所選組件、資料集設定與優化器設定初始化 LoRA 訓練流程。 FluxTrainValidationSettings 節點設定驗證參數,包括樣本數、解析度與批次大小。
ComfyUI FLUX 訓練循環: FluxTrainLoop 節點執行指定步數的 LoRA 訓練循環。 每輪訓練後,FluxTrainValidate 會使用驗證設定評估訓練結果並生成驗證輸出。 PreviewImage 節點顯示驗證結果預覽。 FluxTrainSave 節點會在指定的間隔儲存訓練好的 LoRA 模型。
ComfyUI FLUX 損失可視化: VisualizeLoss 用來視覺化訓練過程中損失的變化。 SaveImage 節點將損失圖儲存以供後續分析。
ComfyUI FLUX 驗證輸出處理: AddLabel 與 SomethingToString 節點為驗證輸出添加標籤,指示訓練步驟。 ImageBatchMulti 與 ImageConcatFromBatch 節點將驗證輸出整合為便於預覽的圖像集。
ComfyUI FLUX 訓練結束: FluxTrainEnd 節點完成 LoRA 訓練流程並儲存模型。 UploadToHuggingFace 節點可用於將訓練好的 LoRA 上傳至 Hugging Face,便於分享與部署。
5.9. ComfyUI 工作流:Flux Latent Upscaler#
5.9.1. ComfyUI Flux Latent Upscaler: <a href="https://cdn.runcomfy.net/tutorial_download/162/09.json" target="_blank">下載</a>#
5.9.2. ComfyUI Flux Latent Upscaler 說明:#
ComfyUI Flux Latent Upscale 工作流首先載入必要元件,包括 CLIP(DualCLIPLoader)、UNET(UNETLoader)與 VAE(VAELoader)。 文字提示透過 CLIPTextEncode 進行編碼,並透過 FluxGuidance 套用指導。
SDXLEmptyLatentSizePicker+ 用來設定空的潛在表示尺寸,作為 FLUX 放大的起點。之後潛在表示會經過一系列處理,透過 LatentUpscale 與 LatentCrop 節點完成放大與裁剪。
放大流程由文字提示編碼所引導,並使用 SamplerCustomAdvanced 結合所選取樣器(KSamplerSelect)與噪聲調度(BasicScheduler)。ModelSamplingFlux 用於設定取樣參數。
隨後,透過 SolidMask 與 FeatherMask 生成遮罩,再透過 LatentCompositeMasked 節點將放大後的潛在表示與原始表示合成。InjectLatentNoise+ 節點將隨機噪聲注入潛在表示中以增強效果。
最終,VAEDecode 節點將潛在表示解碼為圖像,ImageSmartSharpen+ 節點對輸出應用智慧銳化。PreviewImage 顯示最終生成的圖像預覽。
此外,工作流還結合 SimpleMath+、SimpleMathFloat+、SimpleMathInt+ 與 SimpleMathPercent+ 節點,進行尺寸比例與其他數學參數的動態計算,以輔助放大流程的控制與精度。