
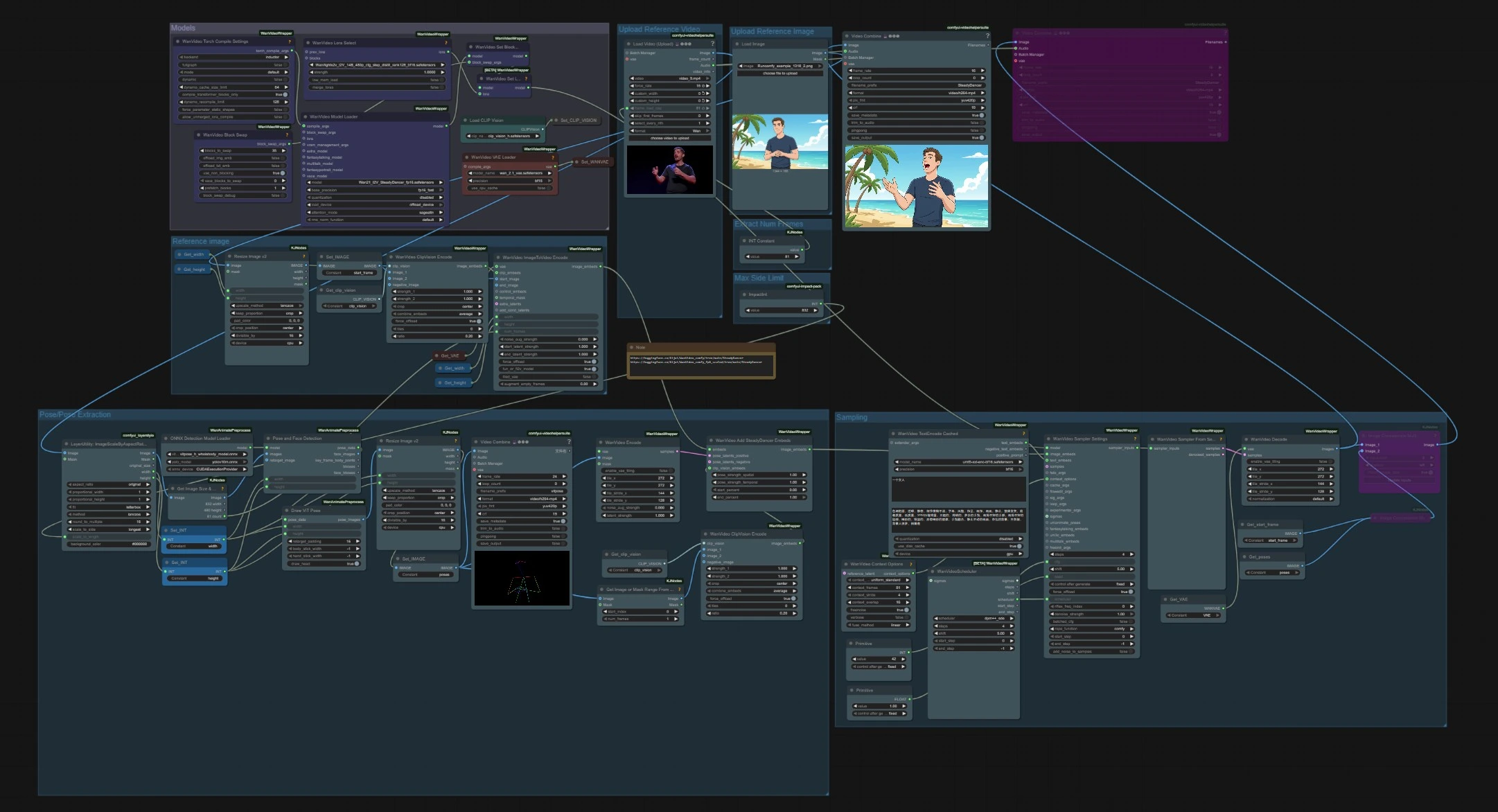
SteadyDancer 圖像轉影片姿勢動畫工作流程#
此 ComfyUI 工作流程將單一參考圖像轉換為由獨立姿勢源驅動的連貫影片。它基於 SteadyDancer 的圖像轉影片範式,使第一幀保持輸入圖像的身份和外觀,而其餘序列則遵循目標運動。該圖形通過 SteadyDancer 專屬嵌入和姿勢管道調和姿勢和外觀,產生流暢、真實的全身運動,具有強大的時間一致性。
SteadyDancer 非常適合人類動畫、舞蹈生成以及讓角色或肖像栩栩如生。提供一張靜止圖像加上一段運動剪輯,ComfyUI 管道便會處理姿勢提取、嵌入、取樣和解碼,提供一個可分享的影片。
Comfyui SteadyDancer 工作流程中的關鍵模型#
- SteadyDancer。身份保護圖像轉影片的研究模型,具有條件調和機制和協同姿勢調製。此處用作核心 I2V 方法。GitHub
- Wan 2.1 I2V SteadyDancer 權重。為 ComfyUI 移植的檢查點,實現了 SteadyDancer 在 Wan 2.1 堆疊上的應用。Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) 和 Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE。用於管道內潛在編碼和解碼的影片 VAE。包括在上方的 WanVideo 移植中。
- OpenCLIP CLIP ViT‑H/14。從參考圖像中提取穩健外觀嵌入的視覺編碼器。Hugging Face
- ViTPose‑H WholeBody (ONNX)。用於身體、手和臉的高質量關鍵點模型,用來推導驅動姿勢序列。GitHub
- YOLOv10 (ONNX)。在多樣化影片中改善人物定位的檢測器,在姿勢估計前使用。GitHub
- umT5‑XXL 編碼器。可選的文本編碼器,用於與參考圖像一起進行風格或場景指導。Hugging Face
如何使用 Comfyui SteadyDancer 工作流程#
此工作流程有兩個獨立的輸入,在取樣時匯合:一個用於身份的參考圖像和一段用於運動的驅動影片。模型在前期加載一次,從驅動剪輯中提取姿勢,SteadyDancer 嵌入將姿勢和外觀融合在一起,然後生成和解碼。
模型#
此組件加載整個圖形中使用的核心權重。WanVideoModelLoader (#22) 選擇 Wan 2.1 I2V SteadyDancer 檢查點,並處理注意力和精度設置。WanVideoVAELoader (#38) 提供影片 VAE,CLIPVisionLoader (#59) 準備 CLIP ViT‑H 視覺骨幹。高級用戶可使用 LoRA 選擇節點和 BlockSwap 選項,以更改內存行為或附加附加權重。
上傳參考影片#
使用 VHS_LoadVideo (#75) 導入運動源。該節點讀取幀和音頻,讓您設置目標幀率或限制幀數。剪輯可以是任何人體運動,如舞蹈或運動動作。然後影片流向縱橫比縮放和姿勢提取。
提取幀數#
一個簡單的常數控制從驅動影片中加載多少幀。這限制了姿勢提取和生成的 SteadyDancer 輸出的長度。增加它以獲得更長的序列,或減少它以更快地進行迭代。
最大側邊限制#
LayerUtility: ImageScaleByAspectRatio V2 (#146) 在保持縱橫比的同時縮放幀,使它們適合模型的步幅和內存預算。設置適合您的 GPU 和所需細節級別的長邊限制。縮放的幀被下游檢測節點使用,並作為輸出尺寸的參考。
姿勢/姿勢提取#
人在縮放的幀上運行檢測和姿勢估計。PoseAndFaceDetection (#89) 使用 YOLOv10 和 ViTPose‑H 強健地找到人和關鍵點。DrawViTPose (#88) 渲染運動的乾淨骨架表示,ImageResizeKJv2 (#77) 將結果的姿勢圖像調整為匹配生成畫布。WanVideoEncode (#72) 將姿勢圖像轉換為潛在變量,以便 SteadyDancer 可以在不干擾外觀信號的情況下調制運動。
上傳參考圖像#
加載您希望 SteadyDancer 動畫化的身份圖像。圖像應清晰顯示您打算移動的主題。使用與驅動影片大致匹配的姿勢和攝影角度,以獲得最忠實的轉移。該幀被轉發到參考圖像組以進行嵌入。
參考圖像#
靜止圖像使用 ImageResizeKJv2 (#68) 調整大小,並通過 Set_IMAGE (#96) 註冊為起始幀。WanVideoClipVisionEncode (#65) 提取保持身份、服裝和粗略佈局的 CLIP ViT‑H 嵌入。WanVideoImageToVideoEncode (#63) 將寬度、高度和幀數與起始幀打包,以準備 SteadyDancer 的 I2V 調節。
取樣#
這是外觀和運動匯聚以生成影片的地方。WanVideoAddSteadyDancerEmbeds (#71) 接收來自 WanVideoImageToVideoEncode 的圖像調節,並用姿勢潛在變量加上一個 CLIP‑vision 參考增強,使 SteadyDancer 的條件調和。上下文窗口和重疊設置在 WanVideoContextOptions (#87) 中,以保持時間一致性。可選地,WanVideoTextEncodeCached (#92) 添加 umT5 文本指導進行風格提示。WanVideoSamplerSettings (#119) 和 WanVideoSamplerFromSettings (#129) 在 Wan 2.1 模型上運行實際的去噪步驟,之後 WanVideoDecode (#28) 將潛在變量轉換回 RGB 幀。最終影片使用 VHS_VideoCombine (#141, #83) 保存。
Comfyui SteadyDancer 工作流程中的關鍵節點#
WanVideoAddSteadyDancerEmbeds (#71)#
此節點是圖形的 SteadyDancer 核心。它將圖像調節與姿勢潛在變量和 CLIP‑vision 線索融合,使第一幀鎖定身份,而運動自然展開。調整 pose_strength_spatial 以控制四肢如何緊密遵循檢測到的骨架,並調整 pose_strength_temporal 以調節隨時間的運動平滑度。使用 start_percent 和 end_percent 限制姿勢控制在序列中的應用位置,以獲得更自然的開場和結尾。
PoseAndFaceDetection (#89)#
在驅動影片上運行 YOLOv10 檢測和 ViTPose‑H 關鍵點估計。如果姿勢錯過小肢體或面部,則在上游增加輸入分辨率,或選擇遮擋較少和光線更清晰的鏡頭。當有多個人在場時,保持目標主體在畫面中最大,以便檢測器和姿勢頭保持穩定。
VHS_LoadVideo (#75)#
控制您使用運動源的哪一部分。增加幀數上限以獲得更長的輸出,或降低它以快速製作原型。force_rate 輸入將姿勢間隔與生成速率對齊,並在原始剪輯的 FPS 不尋常時有助於減少卡頓。
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
在保持縱橫比和分桶為可除大小的同時,將幀保持在選定的長邊限制內。將此處的縮放與生成畫布匹配,以便 SteadyDancer 無需大幅升級或裁剪。如果看到柔和的結果或邊緣工件,將長邊靠近模型的本機訓練縮放,以獲得更清晰的解碼。
WanVideoSamplerSettings (#119)#
為 Wan 2.1 取樣器定義去噪計劃。scheduler 和 steps 設置整體質量與速度,而 cfg 平衡圖像加提示的依從性與多樣性。seed 鎖定可重現性,當您想更緊貼參考圖像的外觀時,可以降低 denoise_strength。
WanVideoModelLoader (#22)#
加載 Wan 2.1 I2V SteadyDancer 檢查點,並處理精度、注意力實現和設備放置。保持這些配置以確保穩定性。高級用戶可以附加 I2V LoRA 來改變運動行為或在試驗時減輕計算成本。
可選附加功能#
- 選擇清晰、光線充足的參考圖像。正面或稍微傾斜的視角,使 SteadyDancer 更可靠地保持身份。
- 優先選擇單一突出主題且遮擋最小的運動剪輯。繁忙的背景或快速剪輯會降低姿勢穩定性。
- 如果手和腳抖動,可以稍微增加
WanVideoAddSteadyDancerEmbeds中的姿勢時間強度,或提高影片 FPS 以密集化姿勢。 - 對於較長的場景,分段處理並重疊上下文以拼接輸出。這樣可以保持合理的內存使用並維持時間連續性。
- 使用內建預覽馬賽克比較生成幀與起始幀和姿勢序列,調整設置時使用。
這個 SteadyDancer 工作流程為您提供了一個實用的端到端途徑,從一張靜止圖像到一個忠實的、由姿勢驅動的影片,從第一幀開始保持身份。
致謝#
此工作流程實施並基於以下作品和資源。我們感謝 MCG-NJU 的 SteadyDancer 的貢獻和維護。欲了解權威信息,請參閱下列鏈接的原始文檔和存儲庫。
資源#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款的約束。
