
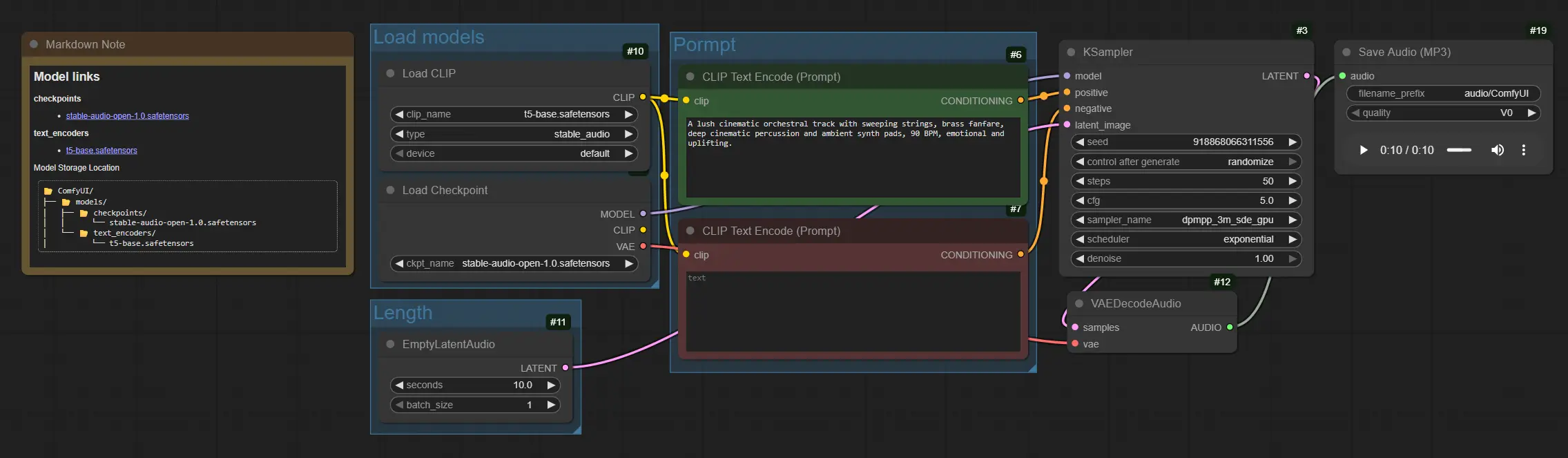
Stable Audio Open 1.0 文本到音樂工作流程#
此工作流程使用 Stable Audio Open 1.0 將純文本轉換為原創音樂和音景。它專為想要在 ComfyUI 中快速、可控音頻生成的作曲家、音效設計師和創作者而設計。您撰寫提示,設置目標持續時間,圖形將渲染一個反映您的風格、情緒、節奏和配器的 MP3。
在內部,工作流程使用基於 T5 的文本編碼器對您的文本進行編碼,在潛在音頻空間中運行 Stable Audio 的擴散過程,然後解碼為波形並保存結果。通過明確的提示指導和簡單的長度控制,Stable Audio 生成對於電影、環境或實驗曲目變得可預測且可重複。
Comfyui Stable Audio 工作流程中的關鍵模型#
- Stable Audio Open 1.0。Stability AI 的開放權重潛在擴散模型,用於文本到音樂和音效設計。它將文本意圖映射到音頻潛在空間,支持各種音樂風格和結構。Repository • Weights
- T5-Base 文本編碼器。此處使用的通用文本模型,用於嵌入提示以調節 Stable Audio 生成。清晰、描述性的輸入導致更一致的音樂。Model card
如何使用 Comfyui Stable Audio 工作流程#
圖形從模型加載到提示調節,然後是採樣、解碼和保存。組織好組,以便您可以一次設置模型,調整長度,撰寫提示,並渲染。
加載模型#
此組初始化核心資產。CheckpointLoaderSimple (#4) 加載 Stable Audio Open 1.0 檢查點,其中包括擴散模型及其音頻 VAE。CLIPLoader (#10) 加載用於調節的基於 T5 的文本編碼器。一旦加載,這些模型將為 Stable Audio 生成提供支柱,並在後續運行中保持駐留。
長度#
此組定義您的音頻將持續多長時間。EmptyLatentAudio (#11) 創建一個具有您選擇的持續時間的空白潛在音軌,以便採樣器知道要生成多少幀。較長的片段消耗更多的時間和內存,因此從謹慎開始,然後擴展。通過增加批次維度,您還可以通過探索想法來產生多個變體。
提示#
此組將文本轉換為擴散過程的指導信號。使用 CLIPTextEncode (#6) 撰寫帶有樂器、流派、情緒、節奏和製作提示的正面提示,例如:“繁茂的電影管弦樂團,掃掠的弦樂和銅管樂器,深沉的打擊樂,環境音墊,90 BPM,振奮。” 使用 CLIPTextEncode (#7) 撰寫負面提示以抑制如“刺耳噪音、剪輯、失真”等工件。它們共同將 Stable Audio 引導至您想要的紋理和結構。
生成和導出#
KSampler (#3) 執行擴散步驟,將空白潛在音頻轉換為由您的文本編碼指導的音樂潛在音頻。VAEDecodeAudio (#12) 將潛在音頻轉換回波形。最後,SaveAudioMP3 (#19) 寫入一個 MP3 文件,以便您可以查看或直接將其放入時間線。對於迭代工作,調整文件名前綴以保持採集有序。
Comfyui Stable Audio 工作流程中的關鍵節點#
CLIPTextEncode(#6) 此節點將您的正面提示編碼為 Stable Audio 遵循的調節。優先考慮清晰的樂器列表、流派、情緒、節奏或 BPM 和製作術語,如“溫暖”、“低保真”、“電影”或“環境”。微妙的措辭變化可以顯著改變作品。請參閱 ComfyUI 核心節點以了解一般行為。ComfyUICLIPTextEncode(#7) 負面提示有助於避免不需要的音色或混音問題。添加描述要移除的術語,例如“刺耳、金屬般的響鈴、故障彈出、廣播嘶嘶聲”。保持簡潔通常會產生更乾淨的 Stable Audio 渲染。ComfyUIEmptyLatentAudio(#11) 控制剪輯長度(以秒為單位),並可選擇批次數以生成多個變體。增加秒數以獲得更長的作品,注意計算隨長度而擴展。使用批次生成,從單個提示中試聽多個 Stable Audio 採集。ComfyUIKSampler(#3) 驅動音頻潛在音頻的擴散過程。最具影響力的控制是steps、sampler、cfg和seed。提高steps以獲得更精細的細節,調整cfg以平衡提示依從性和創造性,並設置固定的seed以重現採集或變化以尋找新想法。請參閱 ComfyUI 的採樣器說明以獲得一般指導。ComfyUISaveAudioMP3(#19) 將最終波形導出為 MP3。使用filename_prefix來標記版本並保持迭代整潔。當比較提示或種子時,並排保存多個採集,使 Stable Audio 選擇更快。ComfyUI
可選額外功能#
- 像會議簡報一樣撰寫提示:樂器、流派、情緒、節奏或 BPM,以及混音形容詞。
- 使用簡短、專注的負面提示來減少嘶嘶聲、刺耳或不需要的樂器。
- 在迭代文本時鎖定
seed,然後更改seed以探索新的 Stable Audio 變體。 - 從較短的持續時間開始調整風格,然後在聲音合適後延長。
- 為每個概念保持一致的文件名前綴,以便稍後可以 A/B 比較 Stable Audio 採集。
深入閱讀的資源:Stable Audio 模型詳細信息和示例此處,ComfyUI 核心和節點行為此處,以及 T5-Base 模型卡此處。
致謝#
此工作流程實現並建立在以下作品和資源之上。我們誠摯地感謝 Stability AI 提供的 Stable Audio Open,comfyanonymous (ComfyUI) 提供的 ComfyUI 節點和工作流程參考,以及 Comfy-Org 和 ComfyUI-Wiki 提供的 Stable Audio Open 1.0 檢查點和 T5-Base 文本編碼器的貢獻和維護。有關權威詳細信息,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- Comfy-Org/Stable Audio Open 1.0 工作流程
- GitHub: Stability-AI/stable-audio-open
注意:使用引用的模型、數據集和代碼需遵循其作者和維護者提供的相關許可和條款。