
Pose Control LipSync 與 Wan2.2 S2V:音頻驅動,姿勢控制的圖像轉視頻,用於表情豐富的化身#
使用 Wan2.2 S2V 的 Pose Control LipSync 將單一圖像、音頻剪輯和姿勢參考視頻轉化為同步的說話表演。你的參考圖像中的角色會跟隨參考視頻的身體運動,而口型動作則與音頻匹配。這個 ComfyUI 工作流程非常適合用於化身、故事場景、預告片、解說視頻和音樂視頻,讓你對姿勢、表情和語音時間點進行緊密控制。
基於 Wan 2.2 S2V 14B 模型家族,該工作流程融合了文本提示、清晰的聲音特徵和姿勢圖來生成具有穩定身份的電影運動。設計簡單易用,同時給予創作者對外觀、節奏和構圖的精細控制。
Comfyui Pose Control LipSync 與 Wan2.2 S2V 工作流程中的關鍵模型#
- Wan2.2‑S2V‑14B。核心的語音到視頻生成器,將靜態圖像和音頻轉化為視頻,並可選擇進行姿勢調節以指導運動。請參見官方存儲庫和模型卡以了解功能和使用說明:Wan‑Video/Wan2.2 和 Wan‑AI/Wan2.2‑S2V‑14B。
- Wan VAE。Wan 自動編碼器以高保真度編碼和解碼視頻潛在變量,並用於 Wan 2.x 管道。參考實現:Diffusers 中的 Wan 管道 documentation。
- Google UMT5‑XXL 文本編碼器。提供強大的多語言文本條件,用於 Wan 管道中的高級場景意圖和風格控制。模型卡:google/umt5‑xxl。
- Facebook Wav2Vec2‑Large。提取驅動口型同步和微表情的強大語音特徵。模型卡:facebook/wav2vec2‑large‑960h。
- DWPose 與 YOLOX 檢測器。從參考視頻生成人體姿勢關鍵點和姿勢圖以指導全身運動。存儲庫:IDEA‑Research/DWPose 和 Megvii‑BaseDetection/YOLOX。
- LightX2V LoRA 用於 Wan。輕量級的 LoRA 用於加速低步驟的圖像到視頻風格去噪,同時保持運動質量;Wan 2.2 支持其去噪器中的 LoRAs。請參閱 Wan Diffusers 關於 LoRA 使用的指導 Wan pipelines。
如何使用 Comfyui Pose Control LipSync 與 Wan2.2 S2V 工作流程#
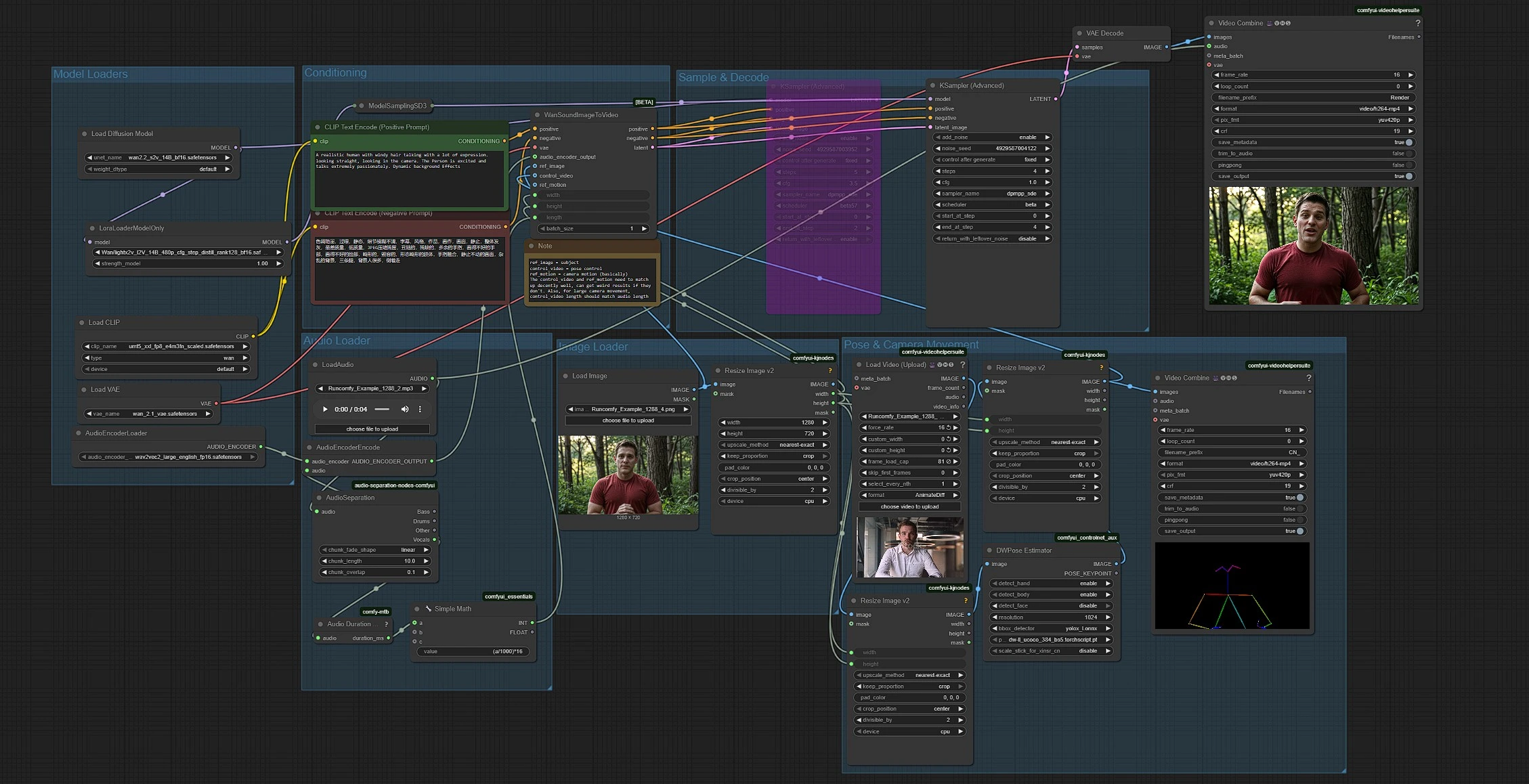
該工作流程結合了五個部分:模型加載、音頻準備、圖像和姿勢輸入、條件設置和生成。組按從左到右的流程運行,音頻長度自動設置剪輯時長為 16 fps。
模型加載器#
該組加載 Wan 2.2 S2V 模型、其 VAE、UMT5‑XXL 文本編碼器和 LightX2V LoRA。基本變壓器在 UNETLoader (#37) 中初始化,並使用 LoraLoaderModelOnly (#61) 適應以更快的低步驟採樣。Wan VAE 由 VAELoader (#39) 提供。文本編碼器由 CLIPLoader (#38) 提供,該編碼器加載 Wan 參考的 UMT5‑XXL 權重。除非你交換模型文件,否則很少需要觸碰此組。
音頻加載器#
使用 LoadAudio (#58) 放入音頻文件。AudioSeparation (#85) 隔離聲音主幹,以便口型跟隨清晰的語音或歌唱,而不是背景樂器。Audio Duration (mtb) (#70) 測量剪輯,SimpleMath+ (#71) 將時長轉換為 16 fps 的幀數,讓視頻長度與音頻匹配。AudioEncoderEncode (#56) 提供 Wav2Vec2‑Large 編碼器,以便 Wan 能夠將音素映射到嘴型,以實現準確的口型同步。
圖像加載器#
LoadImage (#52) 提供攜帶身份、服裝和攝影機設置的主題靜態圖像。ImageResizeKJv2 (#69) 從圖像中讀取尺寸,以便管道在所有後續階段一致地導出目標寬度和高度。使用清晰、正面朝向的圖像,嘴巴無阻擋,以獲得最忠實的口型動作。
姿勢與攝像機運動#
VHS_LoadVideo (#80) 導入你的姿勢參考視頻。ImageResizeKJv2 (#83) 調整幀以適應目標尺寸,DWPreprocessor (#78) 利用 YOLOX 檢測和 DWPose 關鍵點將它們轉化為姿勢圖。最終的 ImageResizeKJv2 (#81) 在它們作為控制視頻向前傳遞之前,將姿勢幀對齊到生成分辨率。你可以通過路由到 VHS_VideoCombine (#95) 預覽姿勢輸出,這有助於確認參考構圖和時間安排是否適合你的主題。
條件設置#
在 CLIP Text Encode (Positive Prompt) (#6) 中寫入風格和場景意圖,使用 CLIP Text Encode (Negative Prompt) (#7) 來避免不需要的工件。提示引導高級美學和背景運動,而音頻驅動口型動作,姿勢參考控制身體動態。保持提示簡潔,並與你的目標攝影機角度和情緒一致。
採樣與解碼#
WanSoundImageToVideo (#55) 將文本、音頻特徵、參考圖像和姿勢控制視頻融合,然後準備潛在序列。KSamplerAdvanced (#64) 執行適合 LightX2V 風格加速的低步驟去噪,VAEDecode (#8) 重建幀。VHS_VideoCombine (#62) 將幀組合成 MP4,並附加你的原始音頻,讓輸出準備好進行審核或編輯。
Comfyui Pose Control LipSync 與 Wan2.2 S2V 工作流程中的關鍵節點#
WanSoundImageToVideo (#55)#
工作流程的核心,利用你的提示、聲音、主題圖像和姿勢控制視頻來調節 Wan2.2‑S2V。調整重要的參數:設置 width、height 和 length 以匹配你的主題圖像和音頻長度,並插入預處理的姿勢視頻以進行運動控制。除非你計劃注入單獨的攝影機軌跡,否則保持 ref_motion 為空。該模型的語音到視頻行為在 Wan‑AI/Wan2.2‑S2V‑14B 和 Wan‑Video/Wan2.2 中進行描述。
DWPreprocessor (#78)#
使用 YOLOX 進行檢測和 DWPose 生成全身關鍵點的姿勢圖。強烈的姿勢提示有助於 Wan 跟隨四肢和軀幹,而音頻控制嘴型和表情。如果你的參考有大量的攝影機運動,請使用一個與預期表演的觀點和時間一致的姿勢視頻。DWPose 及其變體在 IDEA‑Research/DWPose 中有記錄。
KSamplerAdvanced (#64)#
執行潛在序列的去噪處理。加載 LightX2V LoRA 時,你可以保持步驟較低以快速預覽,同時保持運動連貫性;當追求最大細節時,增加步驟。調度選擇影響運動的平滑度與清晰度,應與 LoRA 使用一起進行調整,如 Wan 在 Diffusers documentation 中所述。
VHS_LoadVideo (#80)#
導入並擦除你的姿勢參考。使用其節點內的幀選擇工具選擇與你的音頻段相匹配的確切片段。保持構圖和主題大小與參考圖像一致將穩定運動轉移。該節點屬於 VideoHelperSuite:ComfyUI‑VideoHelperSuite。
VHS_VideoCombine (#62)#
將生成的幀和你的音頻組合成 MP4,並保存工作流程元數據。將輸出幀率設置為 16 fps,以匹配此工作流程中從音頻時長計算的幀數。根據你的資產管理需求禁用或啟用元數據保存。請參見 VideoHelperSuite 文檔 ComfyUI‑VideoHelperSuite。
AudioSeparation (#85)#
隔離聲音,以便 Wav2Vec2 特徵驅動嘴型,而不受樂器或特效的干擾。如果你的輸入已經是清晰的語音,你可以跳過分離。為了獲得最佳效果,保持音頻水平一致並最小化混響。
可選附加項#
- 為了獲得最佳的口型同步,優先選擇清晰的語音或無伴奏合唱。Wav2Vec2 在 16 kHz 下工作;大多數管道會自動重採樣,但提供 16 kHz 文件會有所幫助。
- 使用光線充足、正面朝向的主題圖像,露出牙齒和嘴唇。遮擋會降低準確性。
- 將姿勢參考的構圖和運動與你的主題匹配。當姿勢視頻的長度與音頻段匹配時,較大的攝影機運動效果最佳。
- 從 480p 開始快速迭代;移至 720p 獲得最終質量。Wan 2.2 支持 S2V 中的這兩種分辨率。
- 保持提示簡短,並與你的圖像和姿勢參考中的攝影機設置一致,以避免衝突。
- 如果你試驗 LoRAs,確保它們與 Wan 2.2 去噪器兼容。請參閱 Wan Diffusers docs 中的 LoRA 說明。
這個 Pose Control LipSync 與 Wan2.2 S2V 工作流程讓你能夠快速從音頻和靜態圖像生成一個可控、合拍的表演,看起來協調且表情豐富。
致謝#
此工作流程實現並基於以下作品和資源。我們對 Pose Control LipSync 與 Wan2.2 S2VDemo 的 @ArtOfficialLabs 的貢獻和維護表示感謝。欲了解權威細節,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- YouTube/Pose Control LipSync 與 Wan2.2 S2VDemo
- Docs / Release Notes from @ArtOfficialLabs: Pose Control LipSync 與 Wan2.2 S2VDemo
注意:使用引用的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。