
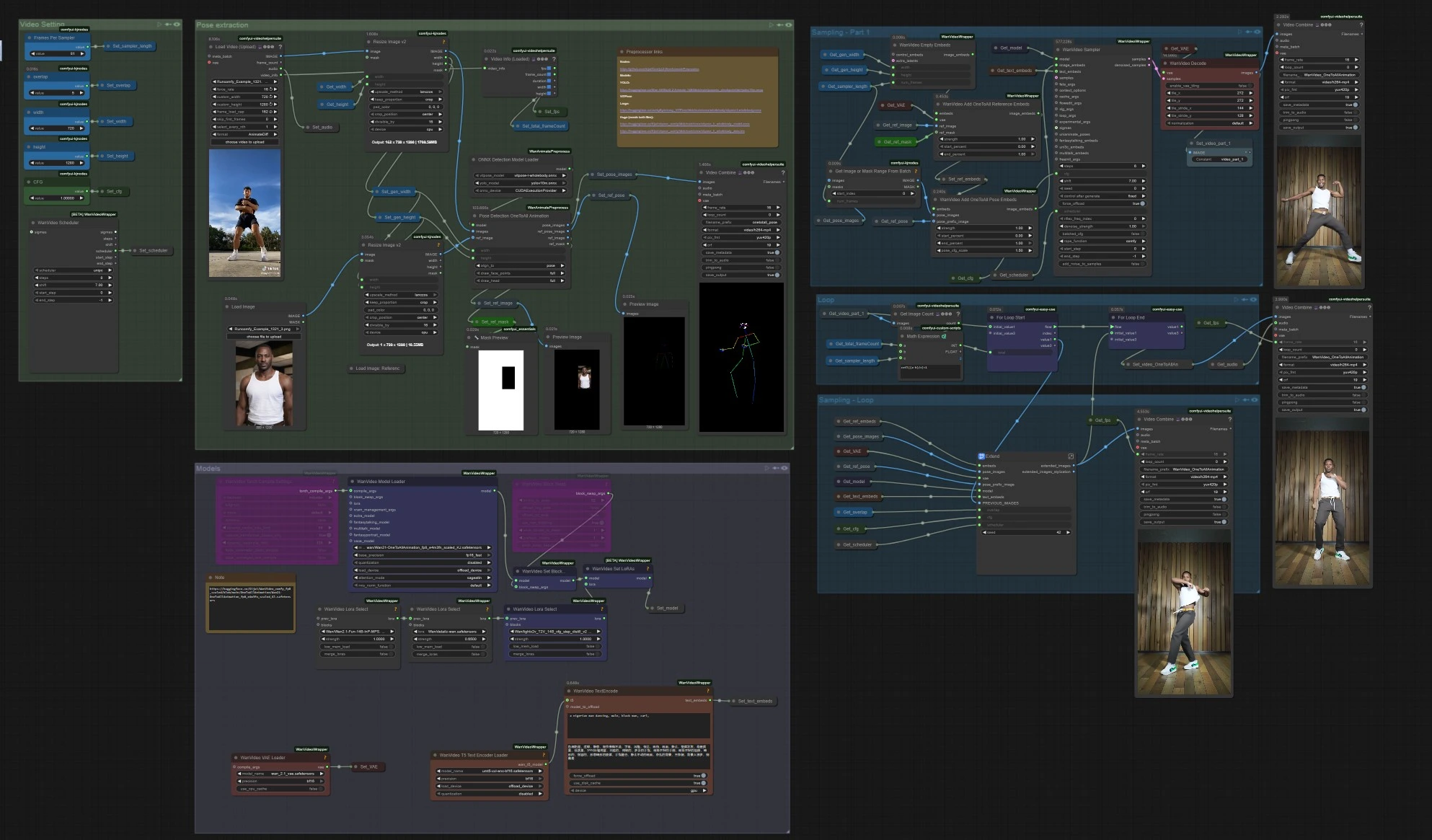
One to All Animation:在 ComfyUI 中製作長篇、姿勢對齊的角色視頻#
此 One to All Animation 工作流程將短參考片段轉換為擴展的高保真視頻,同時保持整個序列中的動作、姿勢對齊和角色身份一致性。它以 Wan 2.1 視頻生成為基礎,配合全身姿勢指導和滑動窗口擴展器,非常適合需要單一外觀跟隨複雜動作的舞蹈、表演捕捉和敘事鏡頭。
如果您是需要穩定的、姿勢驅動輸出且無抖動或身份漂移的創作者,One to All Animation 為您提供了一條清晰的路徑:從源視頻中提取姿勢,將其與參考圖像和遮罩融合,生成第一段,然後重複擴展該段,直到覆蓋全長。
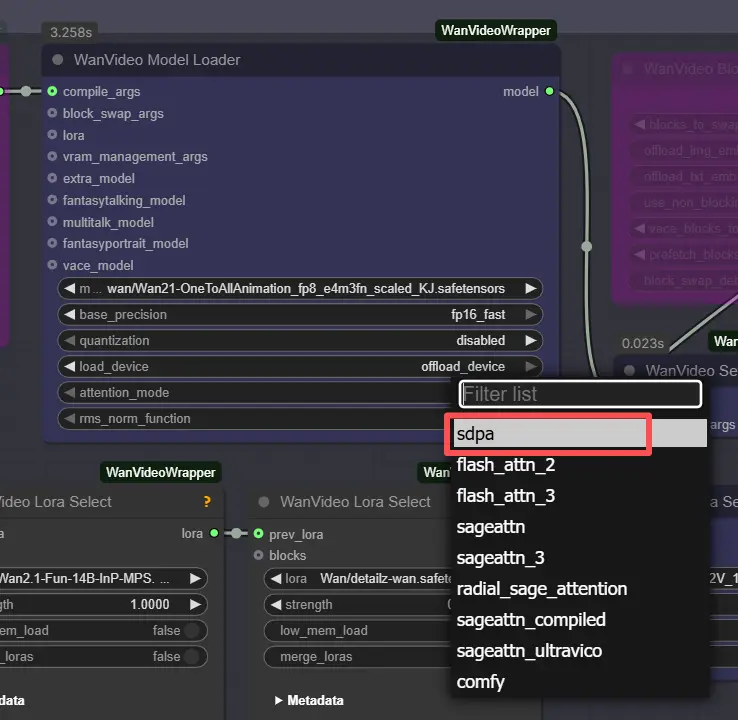
注意:在 2XL 或 3XL 機器上,請在 WanVideo Model Loader 節點中將 attention_mode 設置為 "sdpa"。默認的 segeattn 後端可能會在高端 GPU 上導致兼容性問題。
Comfyui One to All Animation 工作流程中的關鍵模型#
- Wan 2.1 OneToAllAnimation(視頻生成)。用於高質量動作和身份保留的主要擴散模型。示例權重:Wan21-OneToAllAnimation fp8 由 Kijai 調整。 Model card
- UMT5-XXL 文本編碼器。為 Wan 視頻生成編碼提示。 Model card
- ViTPose 全身(姿勢估計)。生成驅動姿勢保真度的密集骨架關鍵點。參見 ViTPose 論文和全身 ONNX 權重。 Paper • Weights
- YOLOv10m 檢測器(人員/區域檢測)。通過將估計器專注於主題來加速穩健的姿勢提取。 Paper • Weights
- 可選的 ViTPose-H 替代方案。用於挑戰性動作的高容量全身模型。 Weights 和 data file
- 可選的 LoRA 包,用於風格/控制。在此圖中使用的示例 LoRA 包括 Wan2.1-Fun-InP-MPS、detailz-wan 和 lightx2v T2V;它們在不重新訓練的情況下,細化紋理、細節或就地控制。
如何使用 Comfyui One to All Animation 工作流程#
整體流程
- 工作流程讀取您的參考動作視頻,提取全身姿勢,準備融合姿勢和角色參考的 One to All Animation 嵌入,生成初始片段,然後使用重疊反覆擴展該片段,直到覆蓋整個時長。最後,合併音頻並導出完整視頻。
姿勢提取
- 在
VHS_LoadVideo(#454) 中加載您的運動來源。使用ImageResizeKJv2(#131) 調整幀大小以匹配生成的縱橫比,以便穩定取樣。 OnnxDetectionModelLoader(#128) 加載 YOLOv10m 和 ViTPose 全身;PoseDetectionOneToAllAnimation(#141) 然後輸出每幀姿勢圖、參考姿勢圖像和乾淨的參考遮罩。- 使用
PreviewImage(#145) 快速檢查姿勢是否跟蹤主題。清晰、高對比度的鏡頭,並且運動模糊最小,會產生最佳的 One to All Animation 結果。
模型
WanVideoModelLoader(#22) 加載 Wan 2.1 OneToAllAnimation 權重;WanVideoVAELoader(#38) 提供配對的 VAE。如果需要,可通過WanVideoLoraSelect(#452, #451, #56) 堆疊風格/控制 LoRA,並使用WanVideoSetLoRAs(#80) 應用它們。- 文本提示由
WanVideoTextEncode(#16) 編碼。寫一個簡潔、身份集中的正面提示和一個強大的清理負面提示,以保持角色模型。
視頻設置
- 寬度和高度在 “Video Setting” 組中設置,並傳播到姿勢提取和生成,以便所有內容保持對齊。
注意:⚠️ 分辨率限制:此工作流程 固定為 720×1280 (720p)。使用其他分辨率將導致 尺寸不匹配錯誤,除非手動重新配置工作流程。
WanVideoScheduler(#231) 和CFG控制選擇噪聲計劃和提示強度。較高的 CFG 更加遵循提示;較低的值略微鬆散地跟蹤姿勢,但可以減少工件。VHS_VideoInfoLoaded(#440) 讀取源片段的 fps 和幀數,循環使用這些信息來確定需要多少 One to All Animation 窗口。
取樣 – 第 1 部分
WanVideoEmptyEmbeds(#99) 為目標大小創建一個條件容器。WanVideoAddOneToAllReferenceEmbeds(#105) 注入您的參考圖像及其ref_mask以鎖定身份,並保留或忽略背景或服裝等區域。WanVideoAddOneToAllPoseEmbeds(#98) 附加提取的pose_images和pose_prefix_image,使第一個生成的片段從第一幀開始遵循源運動。WanVideoSampler(#27) 生成初始潛在片段,這些片段由WanVideoDecode(#28) 解碼,並可選擇性地預覽或保存為VHS_VideoCombine(#139)。這是要擴展的種子段。
循環
VHS_GetImageCount(#327) 和MathExpression|pysssss(#332) 根據總幀數和每次擴展的長度計算需要多少擴展通道。easy forLoopStart(#329) 使用初始片段作為起始上下文,開始擴展通道。
取樣 – 循環
Extend(#263) 是長篇 One to All Animation 的核心。它使用WanVideoAddOneToAllExtendEmbeds(在子圖中)重新計算條件,以保持先前潛在的連續性,然後採樣並解碼下一個窗口。ImageBatchExtendWithOverlap(在Extend中)使用overlap區域將每個新窗口混合到累積視頻中,平滑邊界並減少時間縫隙。easy forLoopEnd(#334) 附加每個擴展塊。結果通過Set_video_OneToAllAnimation(#386) 儲存以供導出。
導出
VHS_VideoCombine(#344) 寫入最終視頻,使用源 fps 和來自VHS_LoadVideo的可選音頻。如果您希望獲得無聲結果,請在此處省略或靜音音頻輸入。
Comfyui One to All Animation 工作流程中的關鍵節點#
PoseDetectionOneToAllAnimation (#141)
- 檢測主題並估計驅動姿勢指導的全身關鍵點。由 YOLOv10 和 ViTPose 支持,對快速運動和部分遮擋具有魯棒性。如果您的主題漂移或多人場景使檢測器混淆,請裁剪您的輸入或切換到上面鏈接的高容量 ViTPose-H 權重。
WanVideoAddOneToAllReferenceEmbeds (#105)
- 將參考圖像和
ref_mask融合到條件中,使身份、服裝或受保護區域在幀之間保持穩定。緊密的遮罩保留面部和頭髮;更廣泛的遮罩可以鎖定背景。當更改外觀時,交換參考並保持相同的運動。
WanVideoAddOneToAllPoseEmbeds (#98)
- 將姿勢圖和前綴姿勢綁定到 One to All Animation 嵌入中。對於更嚴格的編舞,增加姿勢影響;對於更自由的解釋,略微減少它。當您希望一致的紋理同時仍匹配運動時,與 LoRA 結合使用。
WanVideoSampler (#27)
- 將嵌入和文本轉換為初始潛在片段的主要視頻取樣器。
cfg控制提示的遵從性,scheduler在質量、速度和穩定性之間進行權衡。在此處和循環中使用相同的取樣器系列,以避免閃爍。
Extend (#263)
- 執行滑動窗口擴展的緊湊子圖,帶有重疊。
overlap設置是關鍵調節:更多的重疊在成本額外計算的情況下更平滑地混合過渡;較少的重疊更快,但可能暴露縫隙。此節點還重用先前的潛在以保持場景和角色在窗口之間的一致性。
VHS_VideoCombine (#344)
- 最終的混合和保存。從檢測到的 fps 設置
frame_rate,以保持運動時序忠實於您的來源。您可以在後期修剪或循環,但以原始節奏導出可以保留表演的感覺。
可選附加功能#
- 預處理器的安裝說明。姿勢提取節點來自社區附加組件。請參閱 repo 以獲取設置和 ONNX 放置。ComfyUI-WanAnimatePreprocess
- 對於困難的運動,偏好 ViTPose-H。當手/腳快速或部分遮擋時,切換到 ViTPose-H;從上述鏈接頁面下載模型及其數據文件。
- 長時間運行的調整。如果您遇到 VRAM 限制,請減少每次擴展窗口的長度或簡化 LoRA 堆疊。然後可以稍微增加重疊以保持過渡清晰。
- 強大的身份保留。使用高質量、正面朝向的參考,並繪製精確的
ref_mask來保護面部、頭髮或服裝。這對於長時間的 One to All Animation 序列至關重要。 - 清晰的鏡頭有幫助。高快門速度、穩定的光照和清晰的前景主題將顯著改善姿勢跟踪並減少 One to All Animation 輸出中的抖動。
- 視頻工具。導出器和輔助節點來自 Video Helper Suite。如果您希望對編解碼器或預覽進行額外控制,請查看項目的文檔。Video Helper Suite
致謝#
此工作流程實現並建立在以下作品和資源之上。我們感謝 Innovate Futures @ Benji 提供的 One to All Animation 工作流程教程和 ssj9596 提供的 One-to-All Animation 項目對其貢獻和維護。欲了解權威詳情,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- 文檔/發行說明:Patreon post
注意:所引用的模型、數據集和代碼的使用需遵循其作者和維護者提供的相應許可和條款。



