
LTX-2 ControlNet:在 ComfyUI 中結構引導、音頻同步的視頻生成#
LTX-2 ControlNet 是一個控制驅動的 ComfyUI 工作流程,用於 ComfyUI-LTXVideo 擴展,讓您可以通過深度、邊緣和姿勢引導來引導 LTX-2 視頻生成,同時保持音頻和視覺同步。它運行在統一的音視覺潛在空間中,因此語音、音效和運動一起生成並從第一幀保持對齊到最後一幀。
專為文本到視頻、圖像到視頻和視頻到視頻而設計,該工作流程增加了基於 IC LoRA 的 ControlNet 調節以實現精確的佈局和運動控制、場景連續性的首幀初始化以及具有潛在升級的兩階段管道,以在不消耗大量 VRAM 的情況下獲得清晰的結果。LTX-2 ControlNet 完全開放,快速迭代,並面向生產,適合需要可重複、高質量輸出的創作者。
Comfyui LTX-2 ControlNet 工作流程中的關鍵模型#
- LTX-2 19B (dev FP8 和蒸餾)。用於在單一潛在空間中取樣視頻和音頻的核心音視覺生成模型。 Model family
- Gemma 3 12B IT 文本編碼器。通過 LTX-2 使用的打包編碼器提供對提示和否定的強大語言理解。 Encoder file
- LTX-2 空間升級器 x2。用於第二階段細化空間細節的潛在升級模型。 Upscaler
- LTX-2 音頻 VAE。專業的音頻解碼器-編碼器,保持生成的聲音與幀對齊。包含在 LTX-2 檢查點中。 Checkpoints
- IC LoRA 控制系列用於 LTX-2。增加 ControlNet 風格的調節:
- 深度控制 LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- 邊緣控制 LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- 姿勢控制 LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- 蒸餾 LoRA 用於質量/效率權衡: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1。深度控制路徑中使用的深度估計器。 Model
- SD VAE FT MSE (Stability AI)。用於深度預計算和平鋪解碼的圖像 VAE。 VAE
- ComfyUI-LTXVideo 擴展。提供 LTX-2 取樣器、AV 潛在空間、音頻 VAE 和在整個過程中使用的引導節點。 Repository
如何使用 Comfyui LTX-2 ControlNet 工作流程#
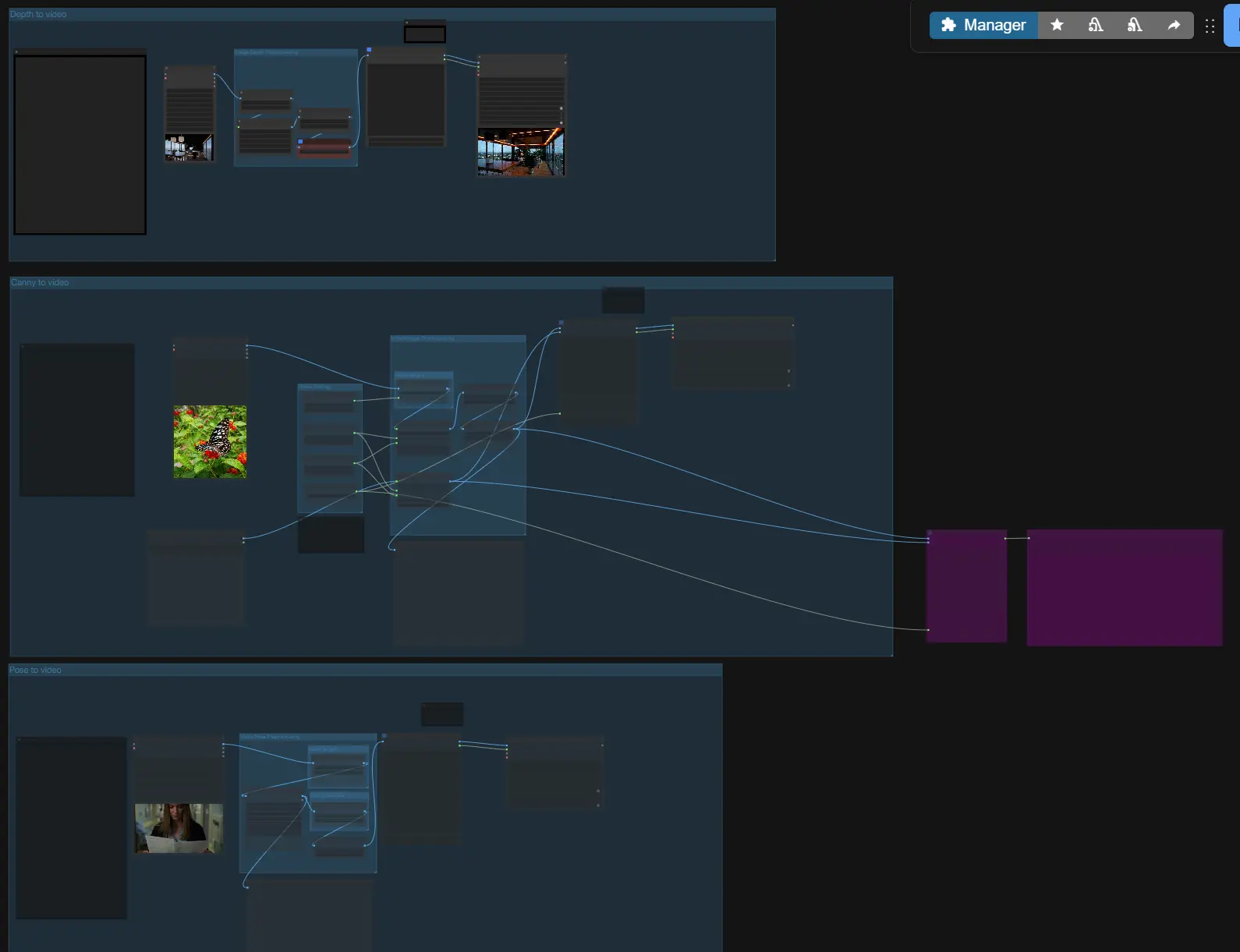
在高層次上,LTX-2 ControlNet 接受您的提示和可選的參考,構建一個具有 ControlNet 風格引導的音視覺潛在空間,進行第一次取樣,然後升級潛在空間以獲得清晰的視頻和同步音頻。選擇三種引導路徑之一(深度、邊緣、姿勢)或獨立使用它們,然後設置長度和尺寸後導出。
- 圖像/視頻預處理
- 如果您正在進行圖像到視頻或視頻到視頻,請使用加載器引入您的參考媒體。
VHS_LoadVideo(#196, #197, #198) 分割幀進行分析,而LoadImage(#189) 處理靜態圖像。該組提供方便的縮放,以便下游引導看到一致的幀大小。 - 可以將“第一幀”圖像傳遞以進行場景初始化;您將在生成組中稍後啟用它。
- 如果您正在進行圖像到視頻或視頻到視頻,請使用加載器引入您的參考媒體。
- 圖像深度預處理
- 對於深度引導,“Image to Depth Map (Lotus)” 子圖使用 Lotus Depth 將您的輸入轉換為標準化的深度圖。這準備了一個單幀或多幀深度表示,LTX-2 可以遵循。
- 該路徑包括可選的調整大小和強度控制,以便引導編碼廣泛的結構而不過度擬合到小的人工痕跡。
- 視頻姿勢預處理
- 對於姿勢引導,
DWPreprocessor(#158) 從輸入視頻中檢測全身關鍵點並縮放它們以進行穩定的調節。這產生了一個強調骨架和四肢方向的清晰姿勢圖像序列。 - 預覽節點幫助您快速驗證檢測和縱橫比在生成前是否正確。
- 對於姿勢引導,
- 邊緣到視頻
- 此控制路徑使用
Canny(#169) 提取邊緣,然後使用控制圖像序列構建一個 AV 潛在空間。當您想要保留輪廓、主要輪廓或參考的字體邊緣時使用它。 - 可用的第一幀圖像輸入可用於一致的初始化;僅在您希望開頭幀匹配特定靜止圖像時啟用它。
- 此控制路徑使用
- 深度到視頻
- 此路徑將 Lotus 深度圖作為控制圖像。深度控制非常適合強制攝像機幾何、大規模佈局和主體距離,讓生成器選擇紋理和照明。
- 您可以提供第一幀以鎖定初始構圖,然後讓運動在深度提示的指導下演變。
- 姿勢到視頻
- 姿勢路徑使用預處理器的關鍵點渲染,指導身體方向和運動時間。它對於角色阻擋、手臂提升時間和步伐循環特別有效。
- 與其他模式一樣,您可以將提示時間與可選的第一幀調節結合以保持連續性。
- 視頻設置和長度
- 在“視頻設置”和“視頻長度”組中設置工作寬度、高度和幀數。工作流程自動調整無效值到 LTX-2 的潛在網格和步幅的最近兼容尺寸,以便您可以安全地迭代。
- 保持目標幀率在節點之間一致;調節節點和最終合成尊重它以獲得流暢的音視覺同步。
- 生成、升級和導出
- 在取樣期間,
LTXVAddGuide將您的正/負調節與選定的控制圖像整合,然後SamplerCustomAdvanced從LTXVScheduler執行視頻和音頻潛在空間的計劃。選擇的第一幀在啟用時通過LTXVImgToVideoInplace注入。 - 第二階段運行
LTXVLatentUpsampler使用 x2 潛在升級器細化細節。最終解碼使用平鋪的VAEDecodeTiled用於幀,LTXVAudioVAEDecode用於音頻,然後使用VHS_VideoCombine或CreateVideo根據選擇的分支寫入視頻。
- 在取樣期間,
Comfyui LTX-2 ControlNet 工作流程中的關鍵節點#
LTXVAddGuide(#132)- 將文本調節和 IC LoRA 控制合併到 AV 潛在空間中,作為 LTX-2 ControlNet 引導的核心。僅調整少數重要控制:選擇與您的路徑(深度、邊緣或姿勢)匹配的控制 LoRA,並在可用時,調整
image_strength以調整模型如何緊密遵循引導。參考實現和節點行為由 LTXVideo 擴展提供。 Docs/Code
- 將文本調節和 IC LoRA 控制合併到 AV 潛在空間中,作為 LTX-2 ControlNet 引導的核心。僅調整少數重要控制:選擇與您的路徑(深度、邊緣或姿勢)匹配的控制 LoRA,並在可用時,調整
LTXVImgToVideoInplace(#149, #155)- 將第一幀圖像注入 AV 潛在空間以進行一致的場景初始化。使用
strength平衡對第一幀的忠實度與自由發展;保持較低以獲得更多運動,較高以獲得更緊密的錨點。當您希望純粹由文本或控制驅動的開頭時,繞過它。 Docs/Code
- 將第一幀圖像注入 AV 潛在空間以進行一致的場景初始化。使用
LTXVScheduler(#95)- 驅動統一潛在空間的去噪軌跡,以便音頻和視頻一起收斂。增加步驟以應對複雜場景和細節;縮短以進行草稿和快速迭代。計劃設置與引導強度互動,因此當引導很強時避免極端值。 Docs/Code
LTXVLatentUpsampler(#112)- 使用 LTX-2 x2 空間升級器執行第二階段潛在升級,以最小的 VRAM 增長提高清晰度。在第一次通過後使用它,而不是增加基礎分辨率,以保持迭代響應。 Upscaler model
DWPreprocessor(#158)- 為姿勢控制路徑生成清晰的人體姿勢關鍵點。使用預覽驗證檢測;如果手或小肢體嘈雜,請在預處理之前將輸入縮放到中等最大尺寸。由 ControlNet 輔助套件提供。 Repo
VHS_VideoCombine/CreateVideo(#195, #106)- 使用選擇的幀率和像素格式將解碼的幀和音頻合成為 MP4。僅在確認您的音頻解碼在預覽中看起來對齊後使用這些。由 Video Helper Suite 提供。 Repo
可選附加功能#
- LTX-2 ControlNet 的提示
- 描述時間上的動作,而不僅僅是靜態屬性。
- 包含所需的聲音提示或對話,以便音頻在節拍上生成。
- 使用簡潔的否定提示來抑制您反復看到的人工痕跡。
- 尺寸和長度
- 使用形式為 32k + 1 的寬度/高度圖像尺寸;如果您錯過,圖形會自動更正,但精確的值會加快迭代。
- 幀數形式為 8k + 1 通常是調度最穩定的。
- 第一幀一致性
- 僅在您需要鎖定的開場構圖時啟用第一幀;將其與適中的
image_strength配對以避免過度約束。
- 僅在您需要鎖定的開場構圖時啟用第一幀;將其與適中的
- VRAM 和吞吐量
- 工作流程在 LTXVideo 補丁中包含序列並行和 torch 編譯選項,用於多 GPU 或內存受限的設置。在長片時保持它們開啟,調試節點行為時關閉。 Extension
致謝#
此工作流程實現並建立在以下工作和資源的基礎上。我們感謝 Lightricks 提供的 ComfyUI-LTXVideo 的貢獻和維護。有關權威的詳細信息,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- ComfyUI-LTXVideo GitHub 存儲庫: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
注意:使用引用的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。