
LTX 2.3 雙角色唇同步 LoRA:從一張圖像和一個音軌生成雙角色唇同步影片#
此 ComfyUI 工作流程將單個靜態圖像和錄製的雙聲道對話轉換為連貫且身份穩定的影片,為螢幕上的兩個角色同步語音。基於 LTX‑2.3 影片骨幹和 LTX 2.3 雙角色唇同步 LoRA,將對話中的音素和時間映射到每個面孔,同時保持表情、目光和場景一致。
設計用於訪談、電影對話、帶影片主持人的播客和虛擬角色互動,工作流程將場景佈局的文本提示與音頻驅動的運動相結合。它包括快速外觀開發的圖像引導階段,兩階段 LTX 取樣以實現時間穩定性,以及潛在的升頻器以獲得清晰的結果。最終輸出是一個帶嵌入音頻的 MP4。
Comfyui LTX 2.3 雙角色唇同步 LoRA 工作流程中的關鍵模型#
- LTX‑2.3 影片生成模型。提供多模態擴散骨幹,根據文本、圖像和音頻合成時間一致的影片。 Lightricks/LTX-2.3
- LTX‑2.3 影片 VAE 和音頻 VAE。編碼和解碼模型使用的影片和音頻潛在變量以保持生成高效和同步。隨 LTX‑2.3 發布。 Lightricks/LTX-2.3
- LTX 空間潛在升頻器。通過在潛在空間中升頻來提高細節,從而在基礎通過後改善質感和邊緣。與 LTX 資產一起提供的變體。 Lightricks/LTX-2
- LTX 2.3 雙角色唇同步 LoRA。注入訓練以鼓勵每個說話者的嘴部運動和時間安排,適用於同一鏡頭中的兩張面孔,同時保留面部身份。
- Z‑Image Turbo 文本到圖像模型。快速生成高質量的參考靜態圖像,在影片合成前錨定身份、構圖和照明。 Comfy‑Org/z_image_turbo
此工作流程使用的相關節點包:ComfyUI‑KJNodes、ComfyUI‑VideoHelperSuite、rgthree‑comfy 和 ComfyUI‑PromptRelay。
如何使用 Comfyui LTX 2.3 雙角色唇同步 LoRA 工作流程#
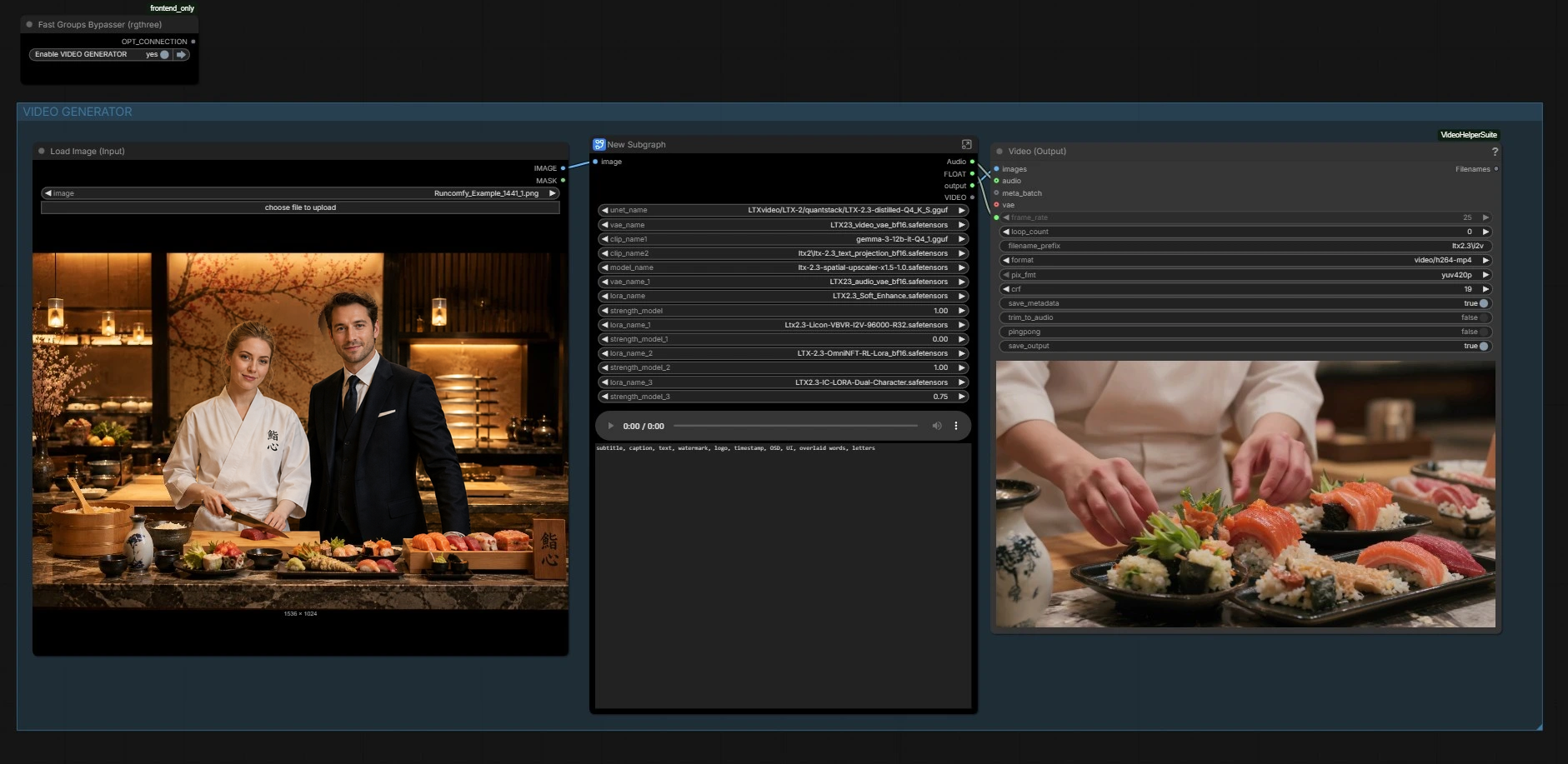
工作流程有兩個協調部分:圖像生成器創建主幀,影片生成器從音頻驅動運動和唇同步,同時保留外觀。使用以下組作為您的指南。
圖像生成器#
本節構建錨定靜態圖像。使用提示列表中的場景預設快速起草構圖,然後用兩個人物的角色描述來完善文本。緊湊的圖像擴散堆疊(“Z IMG TURBO”子圖)編碼您的提示並取樣乾淨的參考靜態圖像。圖像被解碼並保存以供檢查,然後向前傳遞以為影片提供身份和佈局。
此處您接觸的關鍵輸入:場景、服裝和兩個不同角色的描述性提示;除非故意追求該效果,否則避免使用與真實性相抗衡的鏡頭或渲染術語。
模型#
此處圖表加載 LTX‑2.3 骨幹、其影片和音頻 VAE、文本編碼器和潛在升頻器。它還應用 LTX 2.3 雙角色唇同步 LoRA,如果啟用,還有可選的風格或增強 LoRA。在此基礎模型的能力與 LoRA 的雙聲道唇同步行為結合在一起,以引導嘴部運動而不犧牲身份。除非您想更換權重或調整 LoRA 影響,否則不需要採取行動。
自訂音頻#
在此提供您的對話音軌。音頻文件被加載並編碼為音頻潛在變量,通過管道傳遞時間和音素提示。如果您不提供音頻,工作流程可以使用空音頻潛在變量生成運動,但 LTX 2.3 雙角色唇同步 LoRA 在真實對話中更能發揮其作用。使用清晰的雙聲道混音,並有明確的轉換以獲得最佳口部運動分離。
影片參數#
設置目標時長和幀率。這些值在取樣、調度、裁剪指南和最終渲染中被存儲和重用,以便嘴唇、眨眼和鏡頭時間保持一致。將您的影片長度與提供的音頻保持一致,以避免額外的前導或尾部。
潛在生成#
您選擇的靜態圖像被預處理並檢測其尺寸。工作流程創建一個具有正確長度的影片潛在變量,然後將靜態圖像插入到位,以便第一幀與您的設計匹配。應用全幀噪聲遮罩以控制背景的演變程度與面孔的變化。準備好的音頻潛在變量然後與影片潛在變量配對,以便兩種模式準備好進行調節。
顯著的節點:LTXVPreprocess 調整您的靜態圖像以適應 LTX,EmptyLTXVLatentVideo 建立時間軸,LTXVImgToVideoInplaceKJ (#5881) 通過從靜態圖像播種第一幀來鎖定身份。
調節#
文本提示被編碼並附加為正面和負面條件。使用全局提示框以自然語言描述場景和意圖;如果有幫助,可以包括簡短的鏡頭列表。一個專用的負面文本編碼器抑制幀上的字幕、水印和 UI,以保持面孔乾淨。裁剪指南助手分析潛在變量以將注意力集中在兩張面孔上,通過啟用 LTX 2.3 雙角色唇同步 LoRA 改善每個說話者的表情跟踪。
代表性組件:PromptRelayEncode (#5903) 將您的場景描述與潛在上下文合併,LTXVConditioning 附加幀率感知的指導以適應兩種模式。
第一次取樣#
第一個去噪通過生成時間一致的基礎影片,其中嘴部運動被阻塞。自動選擇輕量級調度器和取樣器對,參數從存儲的時間值路由。LTX2_NAG 輸出的模型變體為影片和音頻條件增加噪聲感知指導,以便在內容形成時保持語音時間。
核心取樣器路徑:SamplerCustom (#5891) 與 KSamplerSelect 和基本調度器;僅在您有特定取樣器偏好時進行調整。
第二階段升頻和精緻#
第二階段提高了清晰度和微表情。潛在升頻器增加了空間細節,音頻和影片潛在變量重新合併,精緻取樣器在保留既定運動的同時進行微調。之後,潛在變量被分離並解碼回圖像序列和音頻波形。
重要區塊:LTXVLatentUpsampler (#5927) 提供清晰度,SamplerCustomAdvanced (#5929) 用於精緻通過,然後是 VAEDecode 和 LTXVAudioVAEDecode 返回像素和音頻空間。
輸出#
最後,幀和音頻被打包成一個 MP4 以便播放和檢查。用於調節的幀速率在此處重用,以便視覺節奏和音素時間與模型在生成期間看到的一致。您還可以在圖形中檢查音頻預覽,如果您需要快速檢查。
輸出路徑:CreateVideo (#5931) 生成剪輯;提供輔助 VHS_VideoCombine (#5905) 路徑,用於帶有元數據控制的替代導出。
Comfyui LTX 2.3 雙角色唇同步 LoRA 工作流程中的關鍵節點#
LTXICLoRALoaderModelOnly(#5958) 將 LTX 2.3 雙角色唇同步 LoRA 加載到 LTX‑2.3 骨幹中。當您需要更緊的嘴部關節和說話者分離時,增加strength_model;當您希望基礎模型的運動和風格佔主導地位時降低它,特別是當您堆疊額外的風格 LoRA 時。PromptRelayEncode(#5903) 中央位置用於撰寫場景描述和可選的簡要鏡頭計劃。它將全局提示與模型上下文和當前潛在變量融合在一起,以便指導在整個時間軸上保持一致。保持語言清晰,並明確描述兩個角色,以幫助身份和角色分離。LTXVImgToVideoInplaceKJ(#5881) 直接從您生成或加載的靜態圖像播種影片潛在變量的第一幀。這鎖定了身份、服裝和照明,減少了隨時間的漂移。使用中等或中等寬的雙鏡頭,兩張面孔不受阻礙,以獲得最佳結果。LTXVAudioVAEEncode(#5851) 將提供的對話音軌轉換為模型可以用於音素時間的音頻潛在變量。提供乾淨的混音,沒有重度壓縮;確保開始時間與屏幕上的第一次演講對應,以避免偏移的嘴部運動。SamplerCustom(#5891) 和SamplerCustomAdvanced(#5929) 兩個互補的去噪階段。保持取樣器系列在階段之間一致,以維持運動連續性,並在您喜歡某個外觀後避免噪聲調度的劇烈變化。LTXVLatentUpsampler(#5927) 在精緻之前應用 LTX 潛在升頻器,以在不破壞既定運動的情況下增加清晰度。選擇適合目標分辨率和質感真實性的升頻器變體。
可選附加功能#
- 使用 24 kHz 的雙聲道 WAV,背景噪音最少;在行之間添加短暫的自然停頓,以幫助 LTX 2.3 雙角色唇同步 LoRA 分離轉換。
- 生成或提供一個靜態圖像,其中兩個主題都可見,面向攝像機,面部光線一致。
- 保留排除“字幕、標題、徽標、時間戳”的負面文本提示,以避免在取樣期間燒錄 UI 元素。
- 從短片開始驗證時間,然後在您喜歡的行為後延長時間或提高分辨率。
- 如果您添加風格 LoRA,將它們與 LTX 2.3 雙角色唇同步 LoRA 平衡,以便在場景保留您選擇的美學時,發音保持準確。
致謝#
此工作流程實現並建立在以下作品和資源之上。我們感謝“LTX 2.3 雙角色唇同步 LoRA 工作流程來源”的創作者提供的工作流程。有關權威的詳細信息,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- LTX 2.3 雙角色唇同步 LoRA 工作流程來源/LTX 2.3 雙角色唇同步 LoRA 工作流程來源
- 文檔 / 發布說明:YouTube 影片
注意:使用參考的模型、數據集和代碼需遵守其作者和維護者提供的相應許可和條款。