
Hunyuan視頻是一個由騰訊開發的開源AI模型,使您能夠輕鬆生成令人驚嘆且動態的視覺效果。Hunyuan模型運用先進的架構和訓練技術來理解並生成高質量、運動多樣性和穩定性的內容。
關於Hunyuan Video to Video工作流程#
ComfyUI中的這個Hunyuan工作流程利用Hunyuan模型通過將輸入的文本提示與現有的駕駛視頻結合來創建新的視覺內容。利用Hunyuan模型的能力,您可以生成令人印象深刻的視頻翻譯,這些翻譯無縫融合了駕駛視頻中的運動和關鍵元素,同時使輸出與您所需的文本提示保持一致。
如何使用Hunyuan Video to Video工作流程#
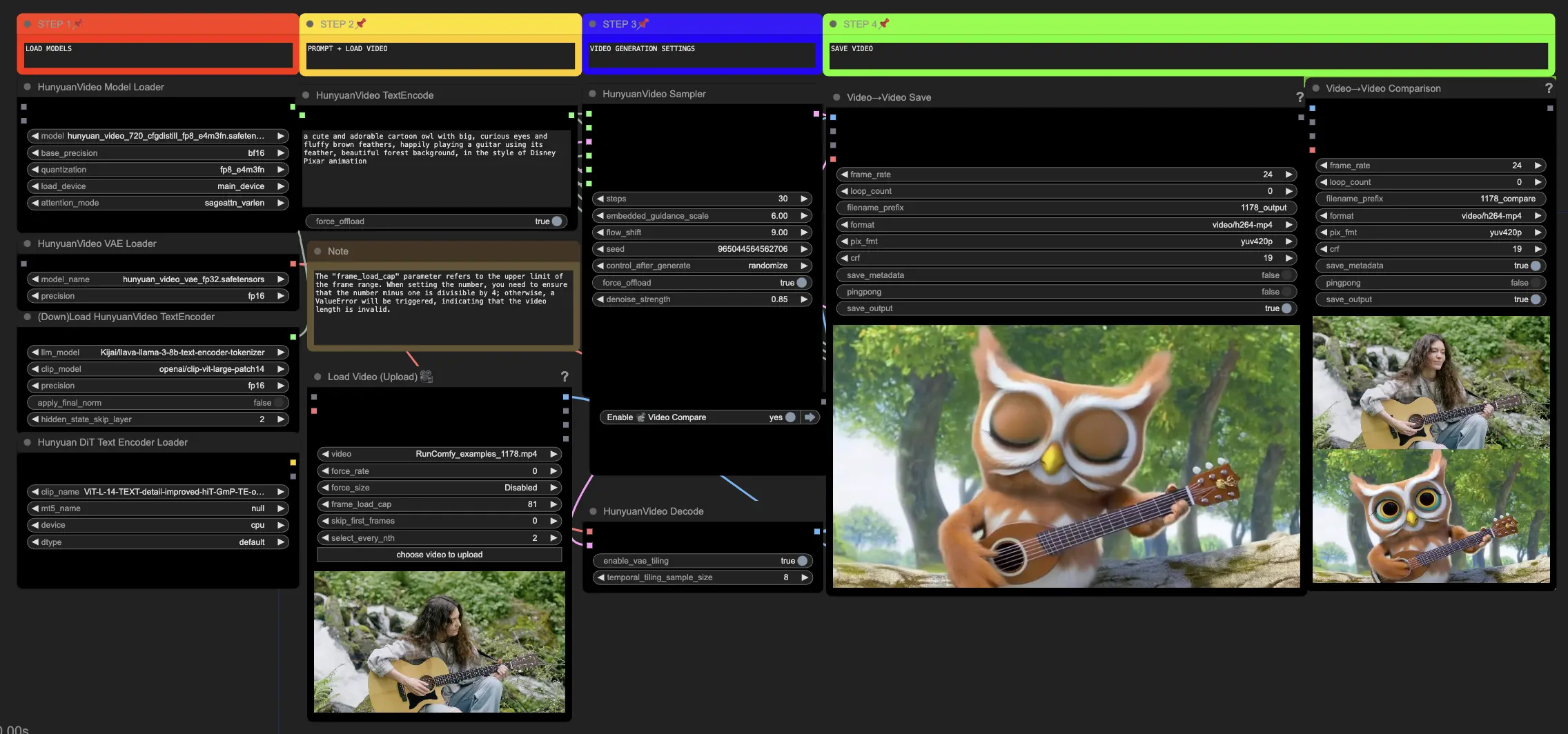
🟥 步驟1:加載Hunyuan模型
- 在HyVideoModelLoader節點中選擇"hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors"文件來加載Hunyuan模型。這是主要的轉換器模型。
- HunyuanVideo VAE模型將自動下載到HunyuanVideoVAELoader節點中。它用於編碼/解碼視頻幀。
- 在DownloadAndLoadHyVideoTextEncoder節點中加載文本編碼器。工作流程默認使用"Kijai/llava-llama-3-8b-text-encoder-tokenizer" LLM編碼器和"openai/clip-vit-large-patch14" CLIP編碼器,這些將自動下載。您也可以使用與以前的模型一起使用過的其他CLIP或T5編碼器。
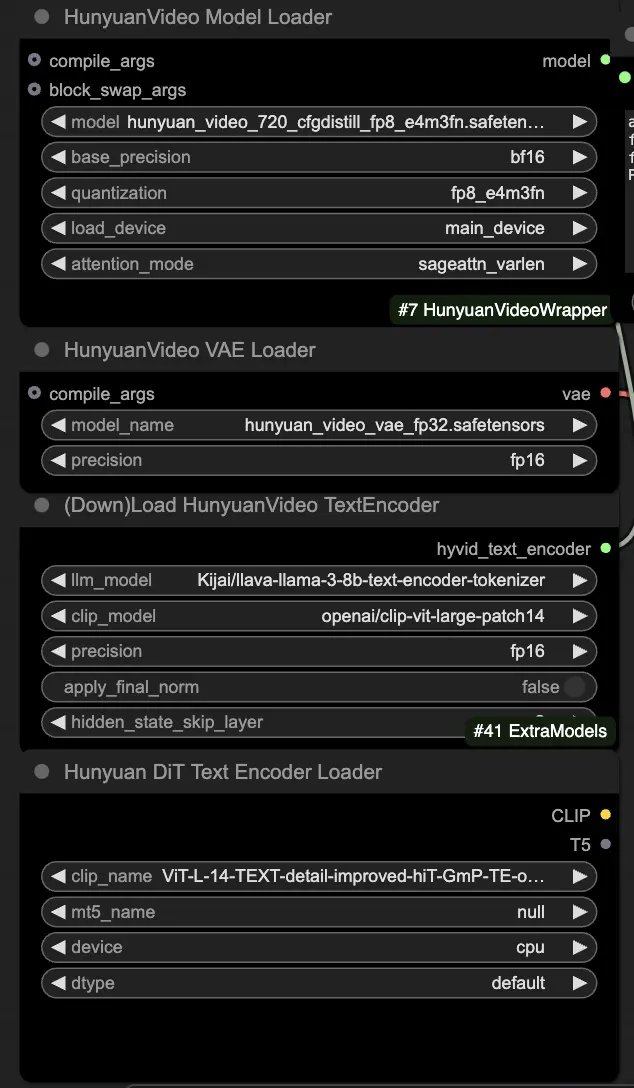
🟨 步驟2:輸入提示並加載駕駛視頻
- 在HyVideoTextEncode節點中輸入描述您希望生成的視覺效果的文本提示。
- 在VHS_LoadVideo節點中加載您想用作運動參考的駕駛視頻。
- frame_load_cap:要生成的幀數。設置數字時,您需要確保數字減去1後可以被4整除,否則會引發ValueError,表示視頻長度無效。
- skip_first_frames:調整此參數以控制視頻的哪一部分被使用。
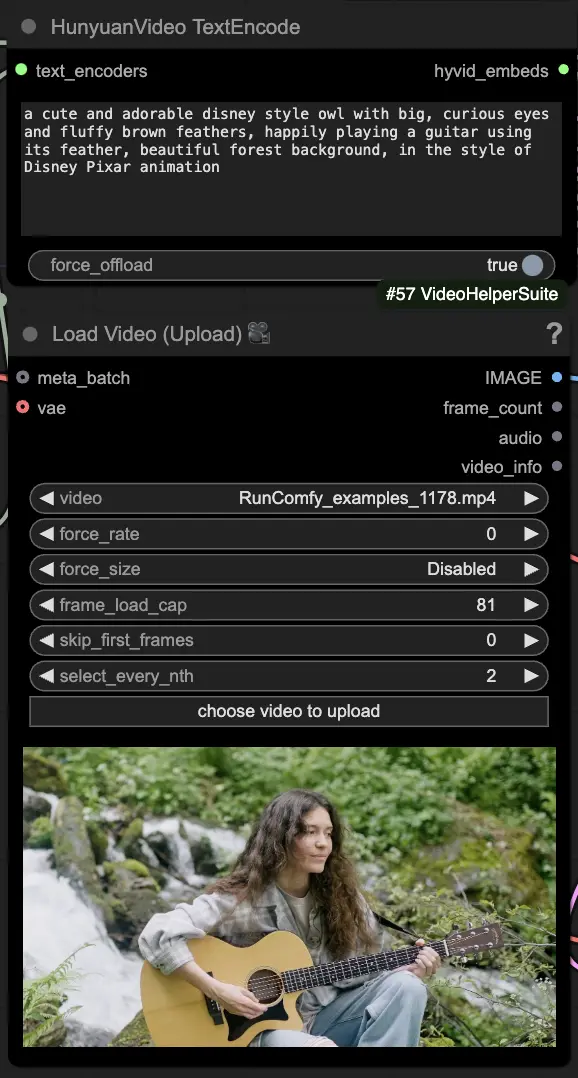
🟦 步驟3:Hunyuan生成設置
- 在HyVideoSampler節點中配置視頻生成超參數:
- Steps:每幀的擴散步驟數,越高意味著質量越好但生成速度越慢。默認為30。
- Embedded_guidance_scale:對提示的遵循程度,值越高越接近提示。
- Denoise_strength:控制使用初始駕駛視頻的強度。較低的值(例如0.6)使輸出看起來更像初始。
- 在"Fast Groups Bypasser"節點中選擇插件和切換開關以啟用/禁用額外功能,如比較視頻。
🟩 步驟4:生成Hunyuan視頻
- VideoCombine節點將默認生成並保存兩個輸出:
- 翻譯視頻結果
- 顯示駕駛視頻和生成結果的比較視頻
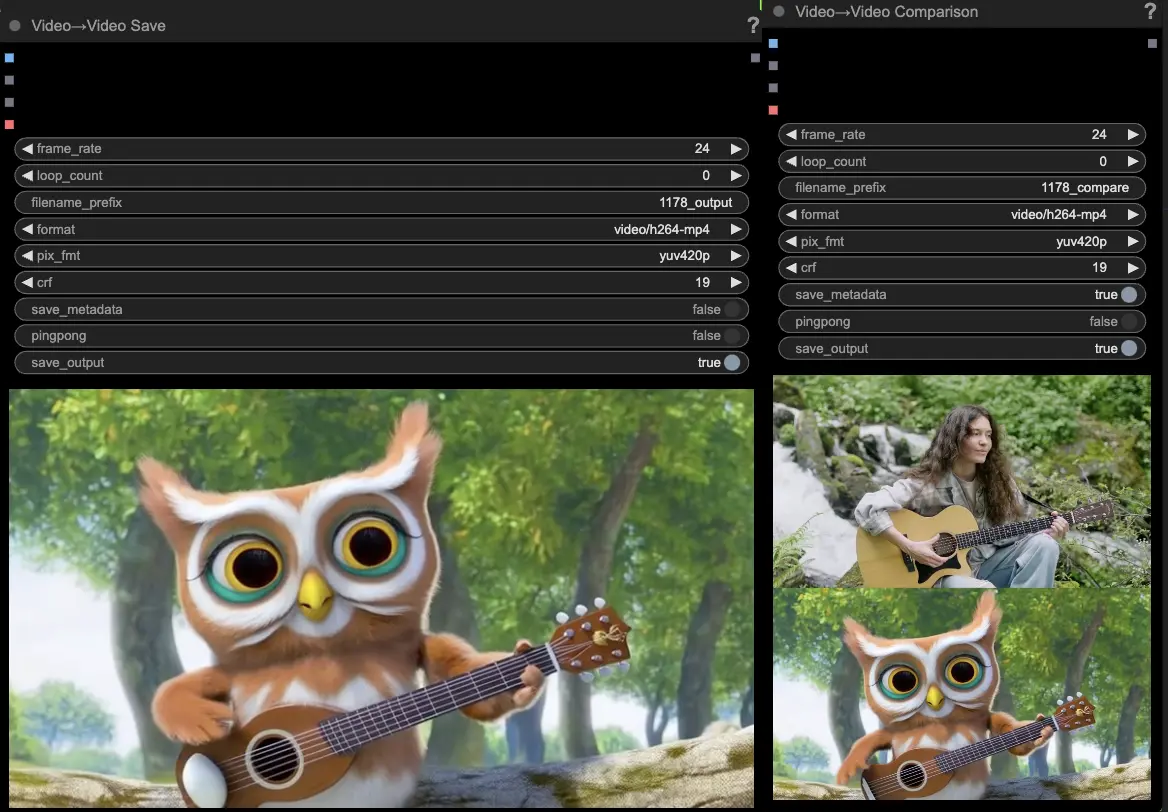
調整提示和生成設置允許在使用Hunyuan模型的現有視頻運動驅動下創建新視頻時擁有令人印象深刻的靈活性。盡情探索這個Hunyuan工作流程的創意可能性吧!
此Hunyuan工作流程由Black Mixture設計。請訪問Black Mixture的YouTube頻道以獲取更多信息。特別感謝Kijai提供的Hunyuan wrappers節點和工作流程示例。