
Hunyuan Video 是一個開源的基礎模型,通過提供最先進的文字轉視頻生成能力,挑戰了封閉源系統的主導地位。基於大規模數據策劃、自適應架構設計和優化基礎設施的創新,Hunyuan Video 樹立了視覺質量的新標準。
雖然 Hunyuan Video 主要專注於文字轉視頻生成,Hunyuan IP2V 工作流程通過同一模型將圖像和文字提示轉換為動態視頻,擴展了這一能力。這種方法使用戶能夠使用視覺參考來引導內容創作,提供了一種替代方法來進行 AI 驅動的內容生產。
通過將圖像與提示結合,Hunyuan IP2V 在保留輸入關鍵特徵的同時生成運動,使其成為 AI 動畫、概念可視化和藝術敘事的有用工具。無論是製作動態場景、風格化動作,還是將靜態視覺擴展到動畫序列,Hunyuan Video 的框架都能提供高效的途徑以獲得高質量的結果。
如何使用 Hunyuan Video - IP2V 工作流程?#
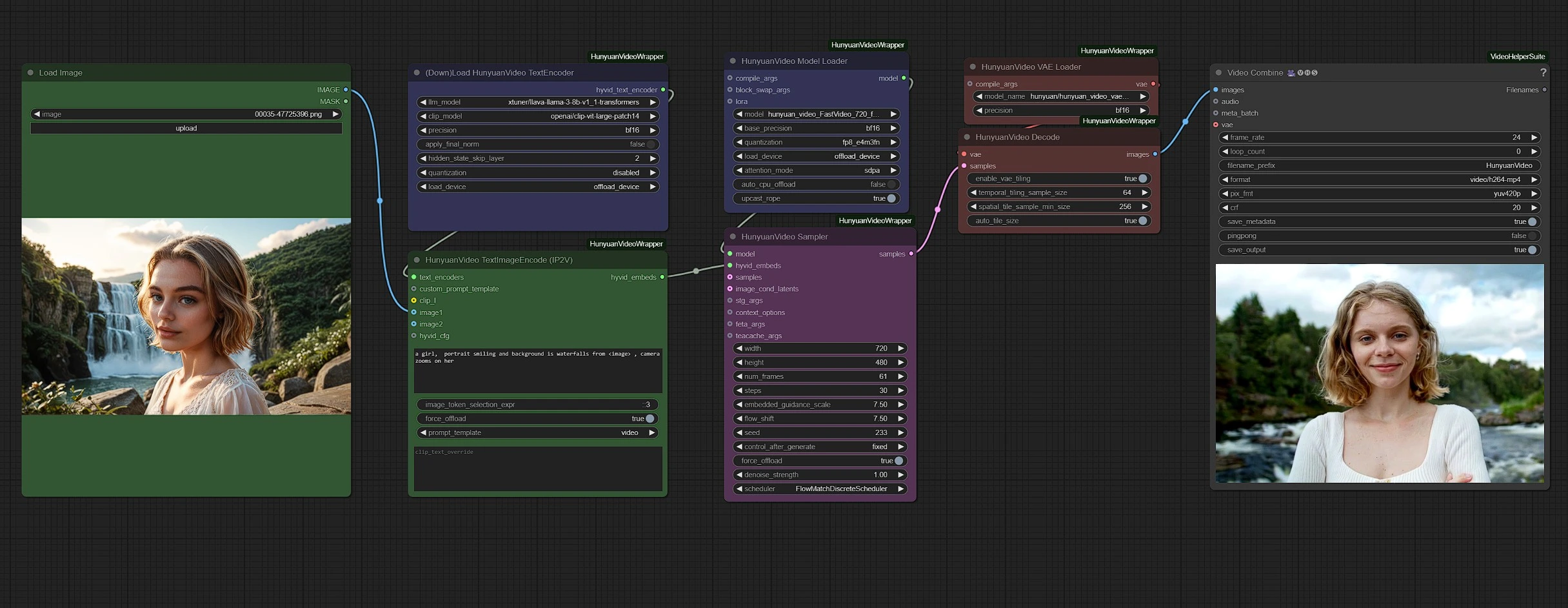
組別以顏色區分以提高清晰度:
- 綠色 - 輸入
- 紫色 - 模型
- 粉紅色 - Hunyuan Sampler
- 紅色 - VAE + 解碼
- 灰色 - 輸出
在綠色節點中上傳您的輸入(圖像和文字),並在粉紅色取樣器節點中調整視頻設置,如持續時間和分辨率。
輸入 1 - 圖像#
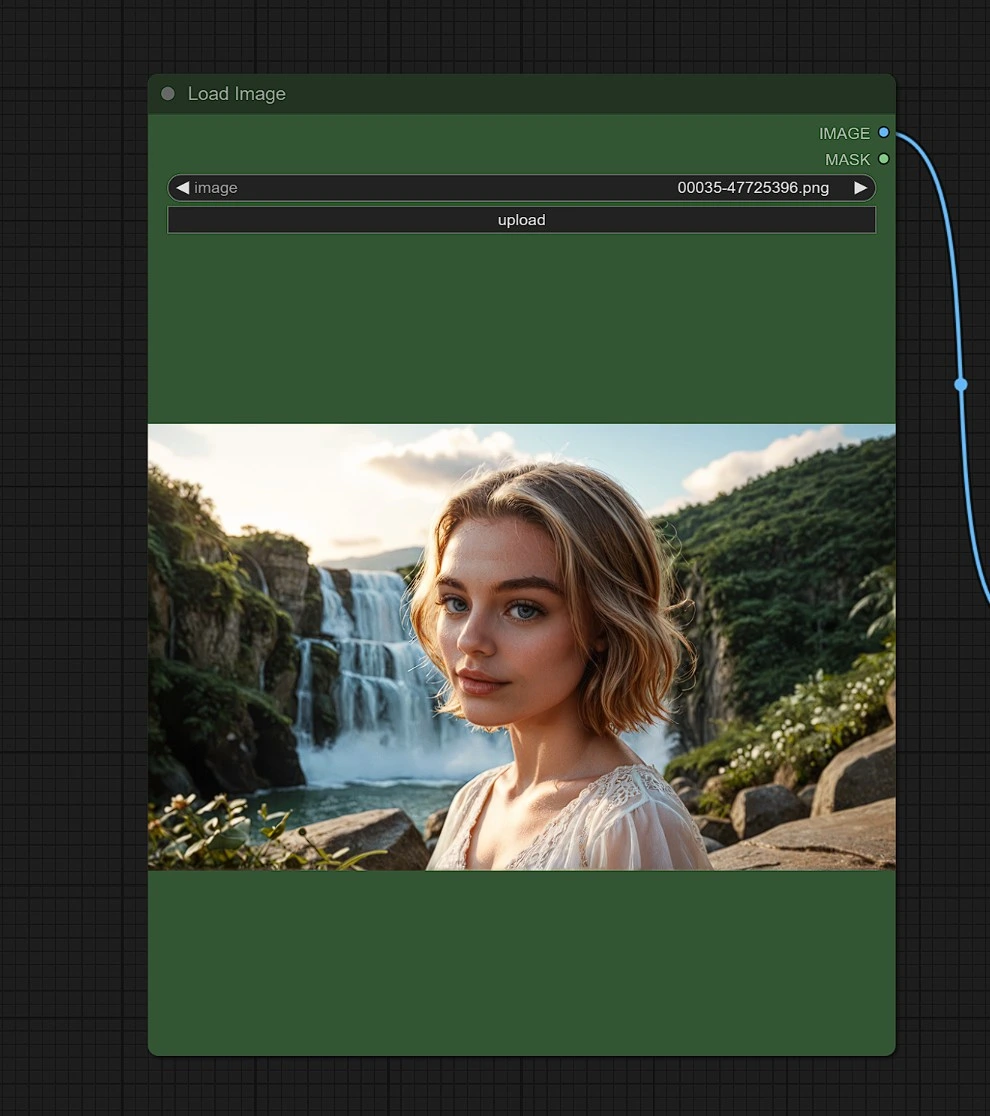
上傳一張圖像作為您尋求類似結果的地方、人物或物體的參考。
輸入 2 - 文字#
在第一個文本框中輸入您的提示,並使用關鍵字 "<image>" 包含圖像。
例如,如果您的輸入是 "empty street" 並且您想添加一名女性,則提示將是:"A portrait of a woman, background is <image>."
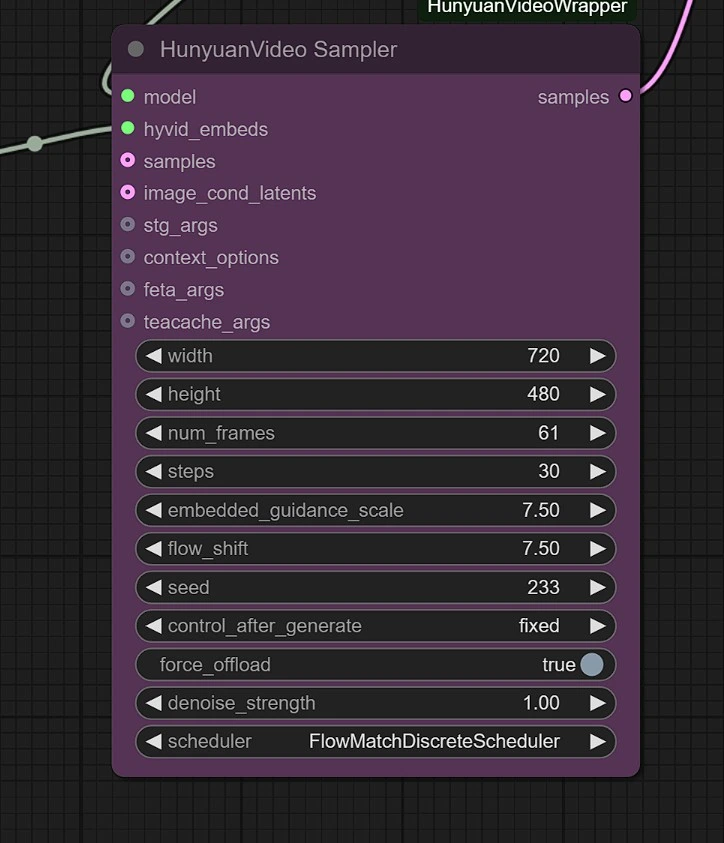
Sampler#
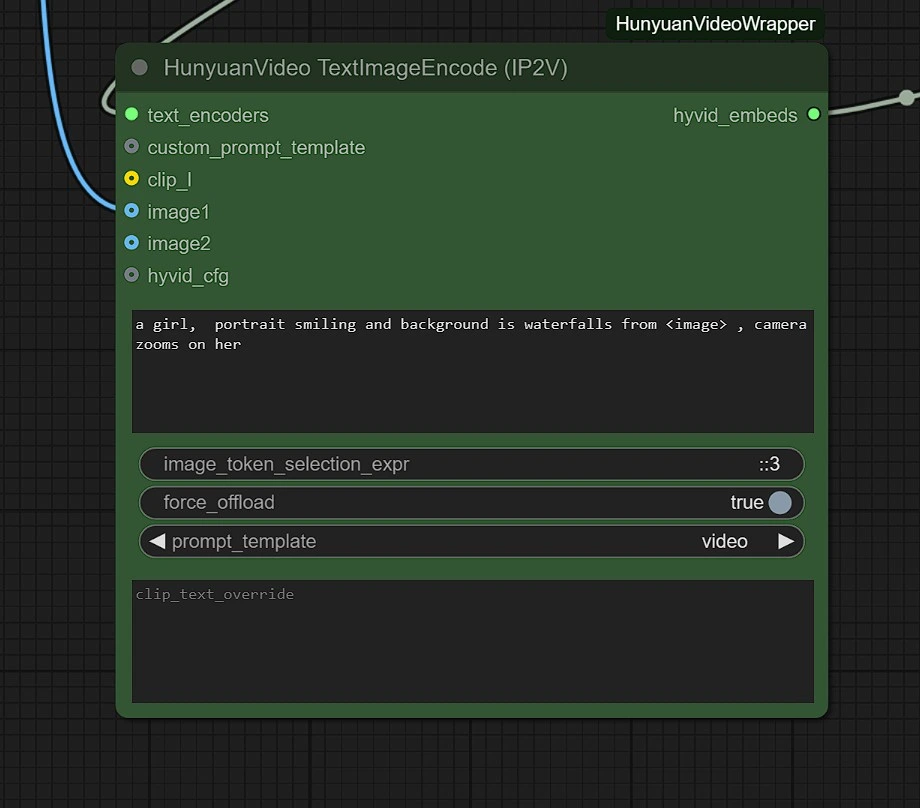
您可以調整以下設置:
- 圖像分辨率 - 最大為 1280px 720px,需要更多 VRAM。
- 幀數 - 這設置了幀數(24 幀 = 1 秒)。
模型#
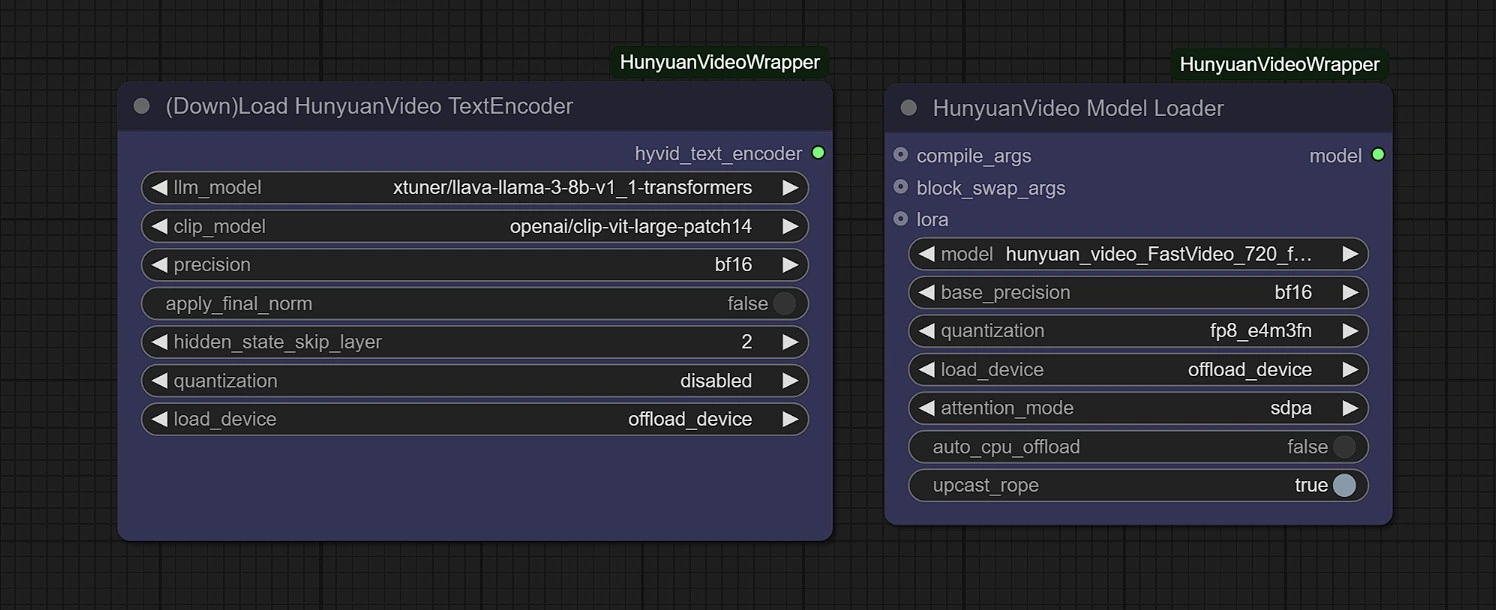
在此組中,模型將在首次運行時自動下載。請允許 3-5 分鐘以完成下載到您的臨時存儲中。
鏈接:
- Diffusion: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > models > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > models > vae
輸出#
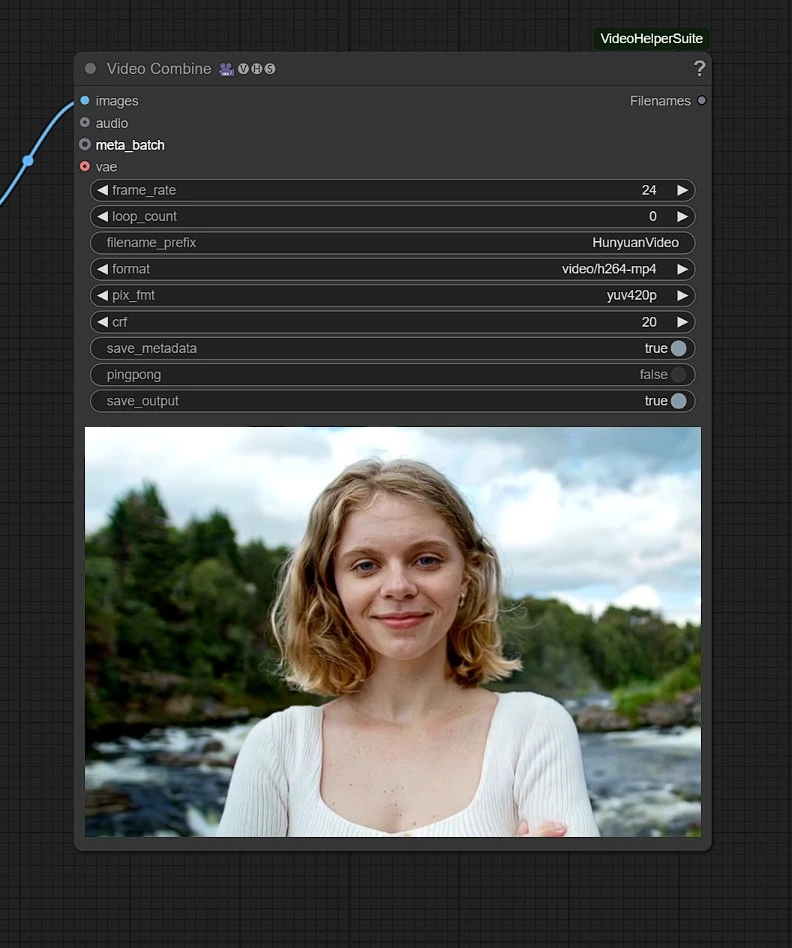
渲染的視頻將保存在 Comfyui 的輸出文件夾中。
使用 Hunyuan IP2V 工作流程,您不再僅限於基於文字的視頻生成,現在您可以賦予您的圖像以運動和風格。無論是AI 影片製作、數字藝術還是創意敘事,此工作流程都讓您能夠比以往更控制地塑造您的願景。