
EchoMimic 是一款生成逼真的音頻驅動肖像動畫的工具。它利用深度學習技術分析輸入音頻,並生成與語音的情感和語音內容緊密匹配的面部表情、唇部運動和頭部動作。
EchoMimic V2 由螞蟻集團支付寶終端技術部的研究團隊開發,包括孟然、張星宇、李玉明和馬晨光。詳細信息請訪問 antgroup/echomimic_v2。ComfyUI_EchoMimic 節點由 smthemex/ComfyUI_EchoMimic 開發。所有的榮譽歸功於他們的重要貢獻。
EchoMimic V1 和 V2#
- EchoMimic V1:具有可定制標記控制的真實音頻驅動肖像動畫
- EchoMimic V2:簡化、富於表情和半身人類動畫
主要區別在於 EchoMimic V2 旨在實現引人注目的半身人類動畫,同時簡化了與 EchoMimic V1 相比不必要的控制條件。EchoMimic V2 使用了一種新穎的音頻-姿勢動態協調策略來增強面部表情和身體動作。
EchoMimic V2 的優勢和劣勢#
優勢:
- EchoMimic V2 生成高度逼真且富於表情的音頻驅動的肖像動畫
- EchoMimic V2 將動畫擴展到上半身,而不僅僅是頭部區域
- EchoMimic V2 在保持動畫質量的同時,減少了與 EchoMimic V1 相比的條件複雜性
- EchoMimic V2 無縫整合頭像數據以增強面部表情
劣勢:
- EchoMimic V2 需要與肖像匹配的音頻源以獲得最佳效果
- EchoMimic V2 目前缺乏姿勢同步代碼,使用默認姿勢文件
- 使用 EchoMimic V2 生成更長時間的高質量動畫可能需要大量計算資源
- EchoMimic V2 在裁剪肖像圖像而非全身照片上效果最佳
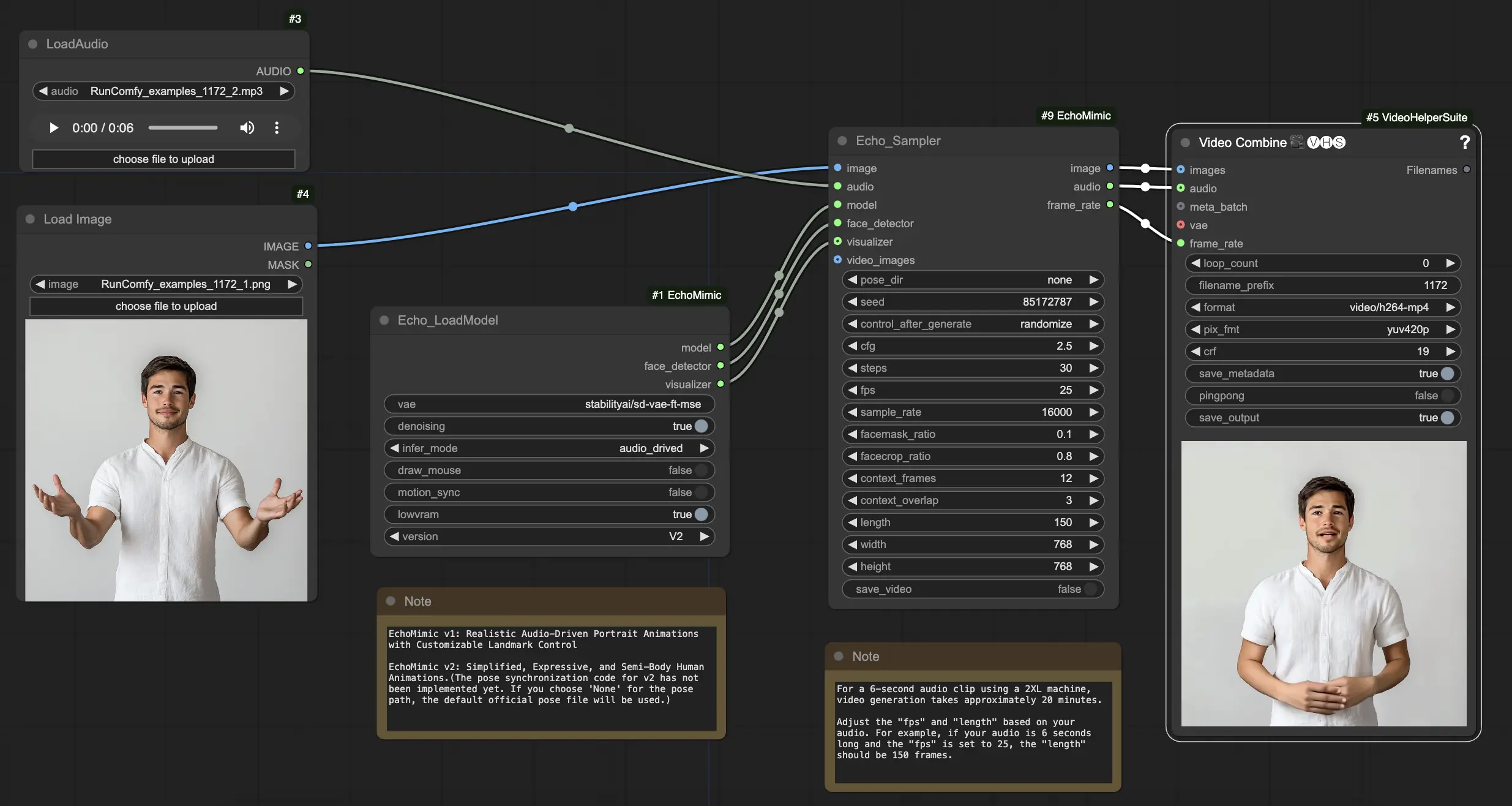
如何使用 ComfyUI EchoMimic 工作流#
在 "Echo_LoadModel" 節點中,您可以選擇 EchoMimic v1 和 EchoMimic v2:
- EchoMimic v1:此版本專注於生成真實的音頻驅動肖像動畫,能夠自定義標記控制。非常適合創建與輸入音頻緊密匹配的逼真面部動畫。
- EchoMimic v2:此版本旨在簡化動畫過程,同時提供富於表情和半身人類動畫。它將動畫擴展到面部區域之外,包括上半身運動。但請注意,v2 的姿勢同步功能尚未在 ComfyUI 工作流的當前版本中實現。如果您選擇 "None" 作為姿勢路徑,則將使用默認的官方姿勢文件。
以下是使用提供的 ComfyUI 工作流的分步指南:
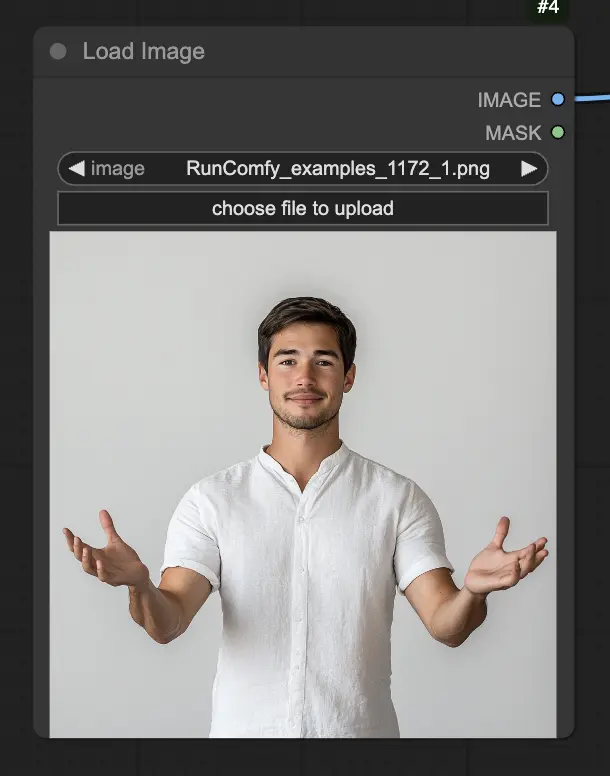
步驟 1. 使用 LoadImage 節點加載您的肖像圖像。這應該是主題頭部和肩膀的特寫鏡頭。
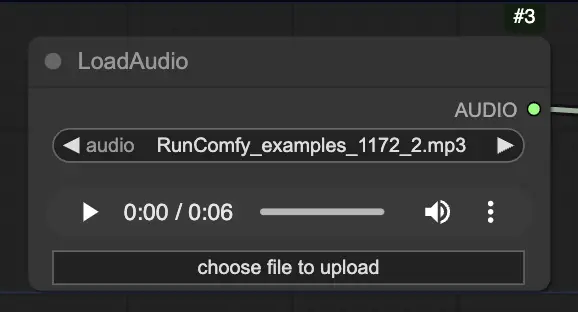
步驟 2. 使用 LoadAudio 節點加載您的音頻文件。音頻中的語音應該與肖像主題的身份匹配。
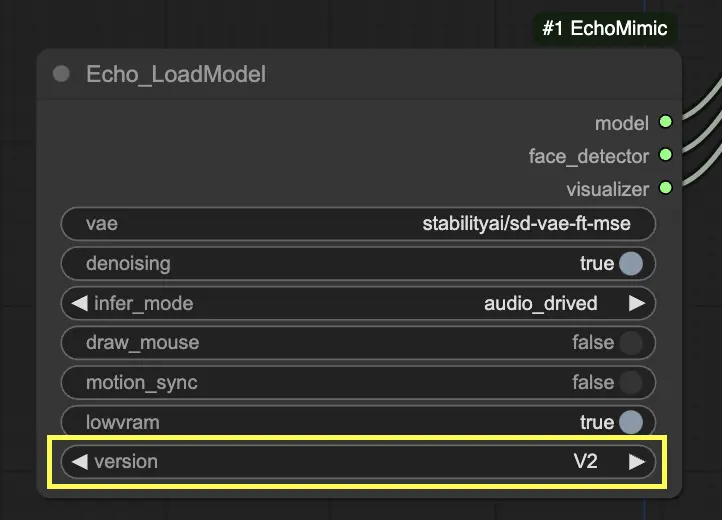
步驟 3. 使用 Echo_LoadModel 節點加載 EchoMimic 模型。關鍵設置:
- 選擇版本(V1 或 V2)。
- 選擇推理模式,例如音頻驅動模式。
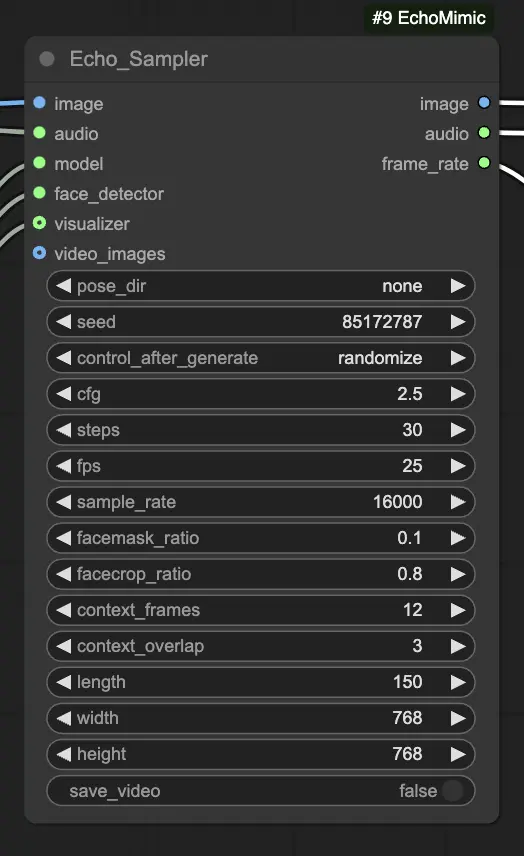
步驟 4. 將圖像、音頻和加載的模型連接到 Echo_Sampler 節點。關鍵設置:
- pose_dir:用於姿勢驅動動畫模式的姿勢序列文件的目錄路徑。如果設置為 "none",則不使用姿勢序列。
- seed:生成一致結果的隨機種子。應為 0 到 MAX_SEED 之間的整數。
- cfg:無分類器指導尺度,控制音頻條件的強度。較高的值會導致更明顯的音頻驅動運動。默認值為 2.5,範圍從 0.0 到 10.0。
- steps:生成每幀的擴散步數。較高的值會生成更平滑的動畫,但生成時間較長。默認為 30,範圍從 1 到 100。
- fps:輸出視頻的幀率(每秒幀數)。默認為 25,範圍從 5 到 100。
- sample_rate:輸入音頻的採樣率,以 Hz 為單位。默認為 16000,範圍從 8000 到 48000,以 1000 為增量。
- facemask_ratio:面罩區域到完整圖像區域的比例。它控制面部周圍動畫的區域大小。默認為 0.1,範圍從 0.0 到 1.0。
- facecrop_ratio:面部裁剪區域到完整圖像區域的比例。它確定圖像中面部區域的佔比。默認為 0.8,範圍從 0.0 到 1.0。
- context_frames:生成每幀時使用的過去和未來幀的數量。默認為 12,範圍從 0 到 50。
- context_overlap:相鄰上下文窗口之間的重疊幀數。默認為 3,範圍從 0 到 10。
- length:輸出視頻的幀數。應根據輸入音頻的時長和 fps 設置。例如,如果您的音頻長度為 6 秒,fps 設置為 25,則長度應為 150 幀。長度範圍為 50 到 5000 幀。
- width:輸出視頻幀的寬度,以像素為單位。默認為 512,範圍從 128 到 1024,以 64 為增量。
- height:輸出視頻幀的高度,以像素為單位。默認為 512,範圍從 128 到 1024,以 64 為增量。
請注意,視頻生成可能需要一些時間。例如,使用 RunComfy 上的 2XL 機器從 6 秒音頻片段創建視頻大約需要 20 分鐘。
