
幻想肖像:ComfyUI 中的表達豐富的肖像動畫#
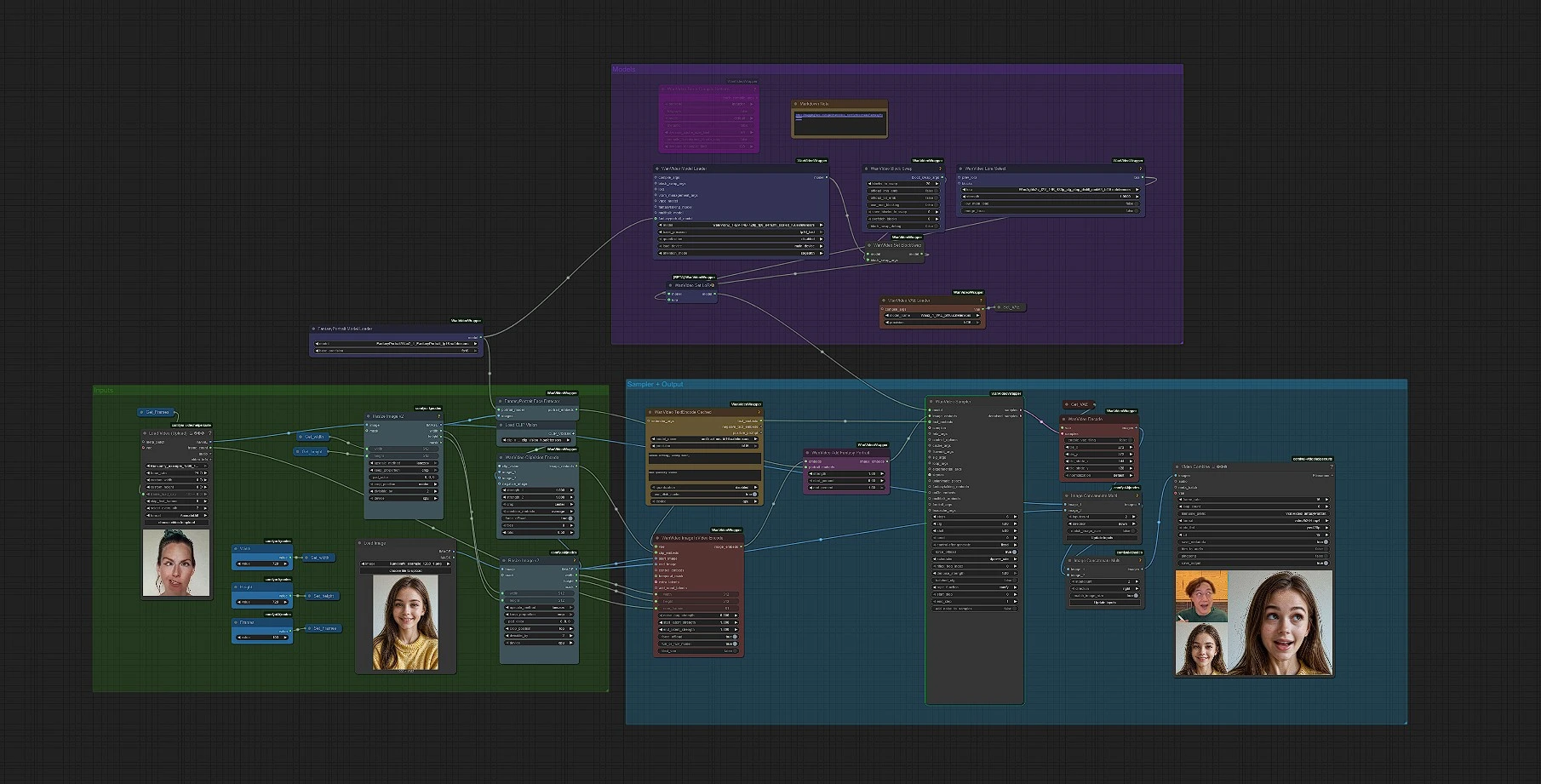
此工作流程將單張靜止圖像轉換為高保真幻想肖像動畫。它將 Fantasy-AMAP FantasyPortrait 模型與表達增強的擴散變壓器集成,並將其包裝在 Wan Video 2.1 圖像到視頻管道中,因此您可以以最少的設置生成身份保留、情感豐富的講話鏡頭。它專為想要從單張照片中獲得電影幻想肖像運動的創作者設計,並提供清晰的框架、時長和風格控制。
管道是完全自動化的:放入肖像,選擇您的分辨率和幀數,可選地添加提示和 LoRA,然後渲染為 MP4。在引擎蓋下,圖形檢測面部,編碼圖像和文本指導,將幻想肖像身份嵌入融合到 Wan 的 I2V 調節器中,採樣視頻,並在保存最終剪輯之前解碼幀。
ComfyUI 幻想肖像工作流程中的關鍵模型#
FantasyPortrait (Fantasy-AMAP)
核心身份和表達模塊。提供表達增強的嵌入,保留主體特徵,同時允許細微的面部運動。 GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
用於從肖像和文本/圖像條件中採樣動畫的視頻擴散骨幹。通過 Kijai 的模型包提供量化的、適合 Comfy 的權重。 Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL encoder
用於視頻採樣器中提示指導的高容量文本編碼器。 示例權重:umt5-xxl-enc-bf16.safetensors 在 Kijai/WanVideo_comfy
Wan 2.1 VAE
用於編碼/解碼潛在變量的視頻優化 VAE。 示例權重:Wan2_1_VAE_bf16.safetensors 在 Kijai/WanVideo_comfy
如何使用 ComfyUI 幻想肖像工作流程#
工作流程從左到右運行,從輸入到最終視頻。您主要需要在前面設置三件事:圖像、尺寸和持續時間。然後,如果您願意,可以使用短提示或 LoRA 進行微調。
1) 圖像輸入和大小調整#
將單個肖像加載到 LoadImage 中,然後進行調整大小以進行處理。兩個調整大小階段確保圖像與您選擇的寬度和高度匹配,同時保持構圖。使用Width、Height 和 Frames 控件定義輸出大小(默認為 720 × 720)和動畫長度。這使您的幻想肖像在整個管道中保持一致的框架。
2) 面部檢測和幻想肖像嵌入#
FantasyPortraitModelLoader 加載 FantasyPortrait 權重,FantasyPortraitFaceDetector 從您的圖像中提取身份和表達感知的肖像嵌入。核心思想是將主體的身份與他們的表達分開,因此最終動畫可以保留身份,同時允許表達豐富的運動。除非您更換模型,否則不需要在此處進行調整。
3) 圖像和文本條件#
對於圖像指導,CLIPVisionLoader 與 WanVideoClipVisionEncode 從肖像中生成強大的視覺特徵。對於文本指導,WanVideoTextEncodeCached 使用 UMT5-XXL 編碼器將您的正負提示轉換為視頻條件嵌入。像“自然工作室特寫,溫柔微笑”這樣的簡短提示通常足以獲得乾淨的幻想肖像外觀。
4) I2V 編碼與持續時間控制#
VHS_LoadVideo 用作方便的幀計數器。您可以保留占位符剪輯或加載具有您偏好持續時間的參考;其幀數會提供給 WanVideoImageToVideoEncode,將您的起始圖像加上圖像/文本嵌入轉換為 I2V 條件。如果您更喜歡固定長度,只需直接設置Frames,忽略參考加載器。
5) 幻想肖像融合#
WanVideoAddFantasyPortrait 將 I2V 條件與步驟 2 中的肖像嵌入合併。這就是最終幻想肖像動畫具有強烈身份保留和表達細節的原因。一旦您的圖像加載,則不需要額外的輸入。
6) LoRA 和模型設置#
WanVideoModelLoader 加載 Wan 2.1,然後 WanVideoLoraSelect 可選地應用來自 Kijai 包的輕量級 I2V LoRA,以在不重新訓練的情況下調整運動或美學。如果您想要稍微更具風格的幻想肖像,這是一個很好的實驗場所,同時保持身份不變。
7) 視頻採樣和解碼#
WanVideoSampler 使用融合的條件生成潛在幀。保持提示簡單,適度增加步驟以獲得更多細節,避免用長負面約束。WanVideoDecode 將潛在變量轉換回圖像,工作流程在 VHS_VideoCombine 寫入 MP4(默認 16 fps,yuv420p)之前連接預覽。為方便起見,設置了輸出文件名前綴。
ComfyUI 幻想肖像工作流程中的關鍵節點#
FantasyPortraitModelLoader (#138)#
加載 FantasyPortrait 權重。如果您正在測試較新的 Fantasy-AMAP 版本,請在此處交換。不需要調整,但請保持與您的 Wan 模型和 VAE 一致的精度。
FantasyPortraitFaceDetector (#142)#
從調整大小的圖像中提取肖像嵌入。來自光線充足、正面朝向且遮擋最小的照片可以獲得良好效果。如果運動看起來不對,請驗證輸入裁剪並嘗試更乾淨的源圖像。
WanVideoImageToVideoEncode (#151)#
從 CLIP 圖像特徵、您的起始圖像和持續時間構建 Wan 的 I2V 條件。調整寬度、高度和num_frames以控制渲染覆蓋面和長度。較長的序列需要更多的 VRAM 和時間。
WanVideoAddFantasyPortrait (#150)#
將幻想肖像身份/表達融合到 I2V 調節器中。使用此功能可以在允許細微表達變化的同時保持主體在幀之間的可識別性。通常不需要調整參數。
WanVideoSampler (#149)#
生成視頻潛在變量。如果您想要更清晰的細節,請適度增加步驟。如果運動漂移,請減少提示複雜性或嘗試不同的 LoRA。保持指導連貫而不是冗長。
WanVideoTextEncodeCached (#155)#
使用 UMT5-XXL 編碼正/負提示。使用簡短的描述性短語。過於強烈的負面提示(例如,重度“質量差”疊加)可能會抑制表達。
提示#
- 從方形 720 × 720 和 4 到 6 秒開始進行快速迭代,然後根據需要擴展。
- 使用乾淨的前光肖像,眼睛可見。避免重度遮擋、太陽鏡或極端角度。
- 保持幻想肖像提示簡潔。描述照明和氛圍,而不是身份。
- 如果您想要不同的運動感受而不失去身份,請嘗試 Kijai 包中的溫和 LoRA。
致謝#
此工作流程利用 Fantasy-AMAP 團隊的 幻想肖像 模型,將 Expression-Augmented Diffusion Transformers 集成到 ComfyUI 中,形成一個全自動、高質量的肖像動畫管道。 特別感謝 kijai 創建並集成 Wan Video Wrapper node,使在圖像到視頻框架中無縫運行肖像動畫成為可能。 我們還感謝更廣泛的 ComfyUI 社區對開放創意工具的持續貢獻。
鏈接: