
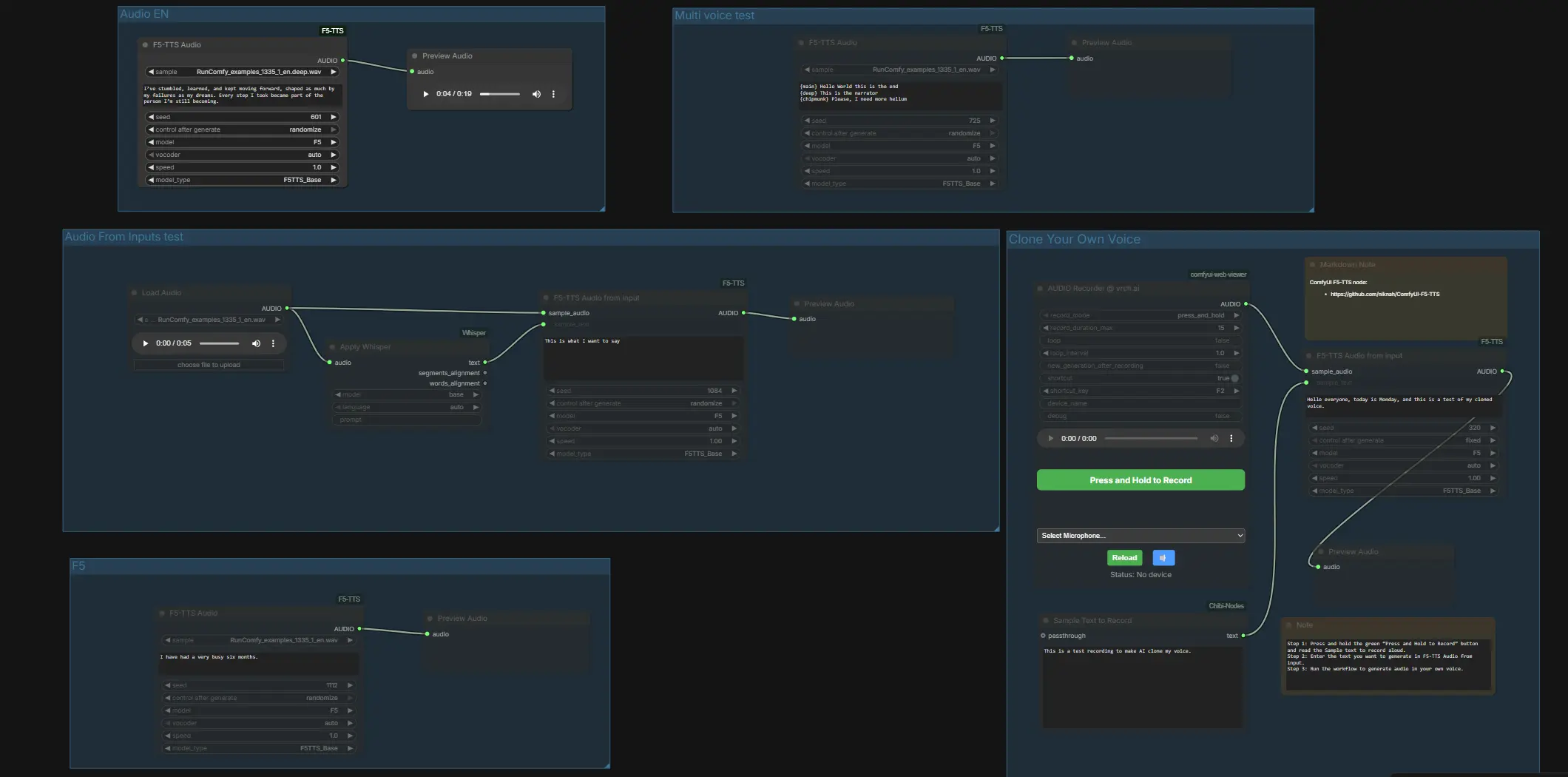
ComfyUI F5 TTS:一個工作流程中的零樣本文字轉語音和語音克隆#
這個 ComfyUI F5 TTS 工作流程讓您可以從文字生成自然語音,並直接在 ComfyUI 內克隆聲音。它由 ComfyUI-F5-TTS 自訂節點提供動力,並包括一個完整的參考克隆路徑:提供一個短的 WAV 和匹配的文字記錄來條件化模型,然後合成遵循參考說話者音色和風格的新台詞。圖表還附帶多個模型變體、語言和聲碼器的即用測試,因此您可以快速比較輸出並決定最適合旁白、配音、角色對話或產品演示的選擇。
一切都被安排成清晰的組別,因此您可以以兩種方式使用 ComfyUI F5 TTS:快速,一鍵式的英語、法語、德語和日語 TTS,或通過內建錄音機或配對文件進行語音克隆。包括一個緊湊的 Whisper 轉錄路徑,以幫助您在已有乾淨錄音時獲得準確的樣本文字記錄。
ComfyUI F5 TTS 工作流程中的關鍵模型#
- Fish Audio F5-TTS。零樣本 TTS 從短參考中學習說話者的特徵,並在多個語言中產生高質量的語音。請參閱項目以獲取模型詳情和訓練背景。GitHub
- OpenAI Whisper。語音識別在此用於自動轉錄您的參考片段,以確保樣本文字精確匹配,從而提高克隆質量。GitHub
- BigVGAN。一個高保真神經聲碼器,可作為更清晰銳利輸出的解碼選項。GitHub
- Vocos。一個快速、輕量的神經聲碼器替代方案,專注於速度和低延遲。GitHub
- ComfyUI-F5-TTS 自訂節點。ComfyUI 集成將 F5-TTS 和兼容後端接入用於整個圖表的節點。GitHub
如何使用 ComfyUI F5 TTS 工作流程#
從高層次來看,工作流程提供了獨立的組別進行快速模型比較和專用的克隆通道。首先試聽預配置的組別以確認您偏好的聲音和聲碼器,然後移至使用自己的樣本進行克隆。下面的每個小節都解釋了該組別的功能和重要的輸入。
Audio From Inputs 測試#
此通道演示參考轉錄加條件化。LoadAudio (#4) 引入一個 WAV,Apply Whisper (#13) 轉錄它,並且 F5TTSAudioInputs (#26) 使用樣本音頻和 Whisper 文字來條件化語音以供預覽。提供乾淨的口語樣本,讓 Whisper 填寫文字記錄端口,以便配對精確匹配。如果您想直接提供文件,請在 ComfyUI/input 中放置配對的 .wav 和 .txt,然後重新啟動 ComfyUI,以便圖表能夠看到它們。
Multi voice 測試#
此組別在一條線中使用單個合成節點顯示風格切換。F5TTSAudio (#17) 讀取標有段落的腳本,因此您可以在一次通過中試聽多個角色風格或重音變化。這是一種快速了解 ComfyUI F5 TTS 如何處理對比音色或旁白與角色節奏的好方法。
Audio EN#
使用 F5TTSAudio (#15) 進行簡單的英語 TTS。輸入您的腳本並預覽以評估默認 F5 預設的基線發音和節奏。此通道非常適合在您決定克隆或多聲音混合之前快速迭代。
F5v1#
此路徑運行 F5TTSAudio (#33) 節點對抗 F5 v1 變體,以便您可以與主 F5 預設比較音調和韻律。使用與 EN 通道相同的文字,以便輕鬆判斷差異。選擇長期項目默認模型時很有幫助。
Audio FR#
此通道面向法語合成,使用 F5TTSAudio (#27) 配置法語預設。提供法語腳本並預覽輸出以檢查鼻音元音和連音處理。與 EN 通道來回切換以比較清晰度和速度。
Audio DE bigvgan#
此處 F5TTSAudio (#30) 使用德語預設和 BigVGAN 聲碼器進行更明亮、更清晰的解碼。當您需要更多存在感或錄音室般的光澤時,使用此通道。如果您更喜歡柔和的渲染,請與 Vocos 通道比較。
Audio JP#
此路徑使用 F5TTSAudio (#25) 配置日語預設。粘貼日語腳本以評估音調重音和音節時間。這是一個適合動漫風格閱讀或面向日本觀眾的產品線的良好起點。
E2 測試#
此組別使用 E2 兼容預設和 Vocos 聲碼器來測試替代後端。使用它來比較延遲和音色特徵與您的 F5 運行。
克隆您自己的聲音#
在 ComfyUI 中直接錄製、配對和克隆。按下 VrchAudioRecorderNode (#43) 中的麥克風並閱讀“Sample Text to Record”框中的提示 Textbox (#42)。錄音機將您的 WAV 路由到 F5TTSAudioInputs (#44),並將您說的準確文字一起條件化模型的音色和風格,然後在 PreviewAudio (#45) 中預覽。為獲得最佳效果,請在安靜的房間中說話,並確保參考文字與您所說的完全一致;然後輸入您希望克隆語音說的新台詞並運行圖表。
ComfyUI F5 TTS 工作流程中的關鍵節點#
F5TTSAudio (#15)#
在 EN、FR、DE、JP、F5v1 和 E2 組中使用的核心單次通過 TTS 節點。提供您的腳本並選擇適合您語言和表達的模型預設和聲碼器。如果您想要可重現的拍攝,請保持種子固定;如果您想要多樣性,則在運行間隨機化。實現由 ComfyUI-F5-TTS 擴展提供。GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
克隆進入點,使用參考 WAV 和其匹配的文字記錄來構建說話者表示,然後在該聲音中合成新台詞。使用乾淨的樣本,保持一致的響度,並確保文字記錄精確,以最大化相似性並減少失真。此處切換模型預設或聲碼器,以獲得更明亮或更中性的解碼。GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
參考樣本的自動轉錄。選擇一個平衡速度和準確性的 Whisper 大小,以適應您的硬件和語言,然後將其輸出文字提供給克隆節點,以確保音頻和文字完美對齊。這防止了樣本文字與實際所說內容不同時可能發生的條件化錯誤。GitHub
VrchAudioRecorderNode (#43)#
一個圖內錄音機,捕捉短的口語提示以進行克隆,無需外部工具。按住錄製,釋放停止,立即聽到 ComfyUI F5 TTS 在您自己的聲音中的效果。將麥克風保持在近距離,並減少環境噪音以獲得最乾淨的效果。
可選補充#
- 使用 5 到 15 秒的乾淨語音作為參考,無音樂或效果。
- 確保樣本文字記錄與錄音完全匹配;即使是小的差異也會降低克隆保真度。
- 在同一條線上比較 Vocos 和 BigVGAN,以決定速度和細節。
- 需要一致的重拍時保持固定種子;探索風格時隨機化。
- 對於多語項目,首先試聽 EN、FR、DE 和 JP 通道,然後在對發音和節奏滿意後最終確定克隆。
感謝#
此工作流程實現並基於以下作品和資源構建。我們感謝 niknah 提供的 ComfyUI-F5-TTS 節點、niknah 提供的 F5TTS-test-all.json 示例工作流程,以及 r/StableDiffusion 社區提供的“在 ComfyUI 中使用 F5-TTS 進行語音克隆”指南的貢獻和維護。欲了解權威詳情,請參考以下鏈接的原始文檔和存儲庫。
資源#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Example Workflow: F5TTS-test-all.json)
- r/StableDiffusion/Community Guide (Voice Cloning with F5-TTS in ComfyUI)
注意:使用參考的模型、數據集和代碼受其作者和維護者提供的相應許可和條款的約束。
