








ComfyUI 中用于结构引导图像生成的 Z 图像 ControlNet 工作流程#
此工作流程将 Z 图像 ControlNet 引入 ComfyUI,以便您可以通过参考图像的精确结构引导 Z-Image Turbo。它将三种引导模式(深度、Canny 边缘和人体姿态)捆绑在一个图中,并允许您在它们之间切换以匹配您的任务。结果是快速、高质量的文本或图像到图像生成,其中布局、姿态和构图在迭代时保持受控。
专为艺术家、概念设计师和布局策划者设计,该图支持双语提示和可选的 LoRA 风格。您将获得所选控制信号的清晰预览,以及自动比较带,以评估深度、Canny 或姿态与最终输出的对比。
Comfyui Z 图像 ControlNet 工作流程中的关键模型#
- Z-Image Turbo 扩散模型 6B 参数。主要生成器,可以快速从提示和控制信号生成逼真的图像。alibaba-pai/Z-Image-Turbo
- Z 图像 ControlNet 联合补丁。为 Z-Image Turbo 增加多条件控制,并在一个模型补丁中实现深度、边缘和姿态引导。alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2。在深度模式下用于结构引导的高密度深度图。LiheYoung/Depth-Anything-V2 on GitHub
- DWPose。估计用于姿态引导生成的人体关键点和身体姿态。IDEA-Research/DWPose
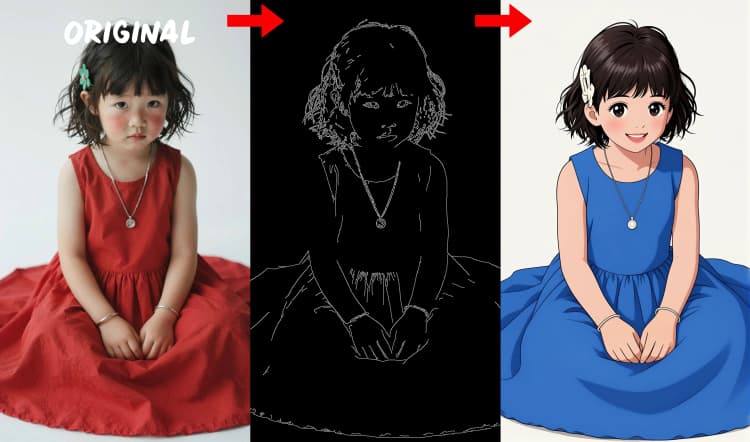
- Canny 边缘检测器。提取干净的线条艺术和边界用于布局驱动的控制。
- ComfyUI 的 ControlNet Aux 预处理器。为此图提供统一的深度、边缘和姿态包装器。comfyui_controlnet_aux
如何使用 Comfyui Z 图像 ControlNet 工作流程#
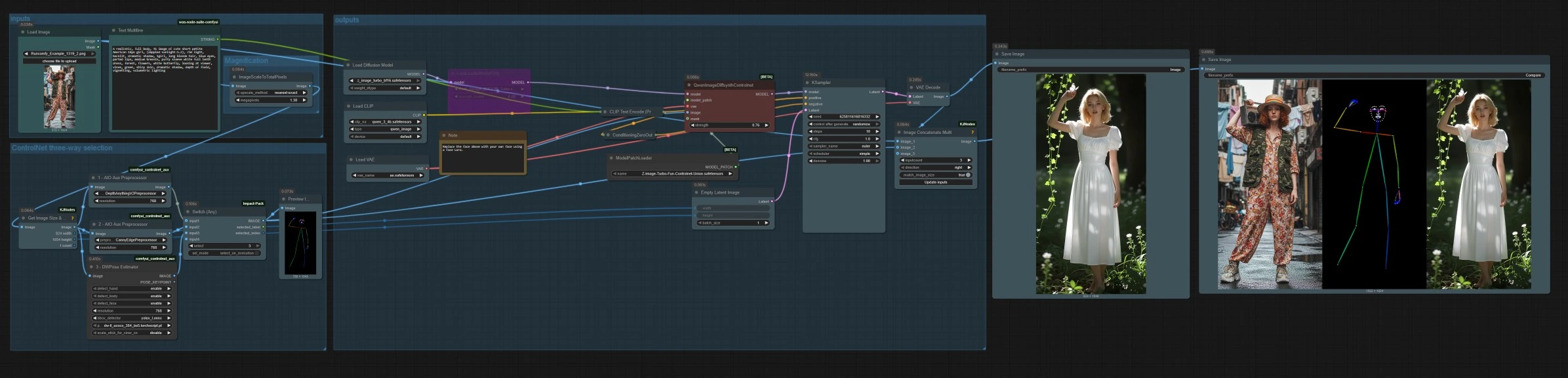
在高层次上,您加载或上传参考图像,选择一个控制模式(深度、Canny 或姿态),然后使用文本提示生成。图将参考图像缩放以实现高效采样,以匹配纵横比构建潜伏,并保存最终图像和并排比较带。
输入#
使用 LoadImage (#14) 选择参考图像。在 Text Multiline (#17) 中输入您的文本提示,Z-Image 栈支持双语提示。提示由 CLIPLoader (#2) 和 CLIPTextEncode (#4) 编码。如果您倾向于纯粹的结构驱动图像到图像,可以将提示保持最低,并依赖选定的控制信号。
ControlNet 三向选择#
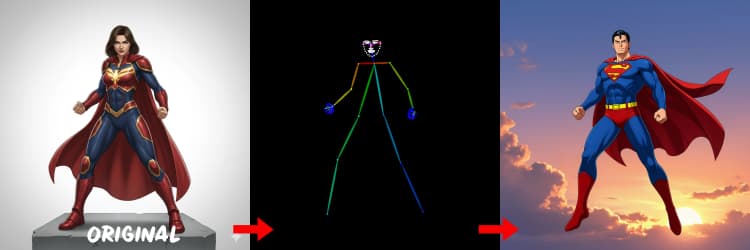
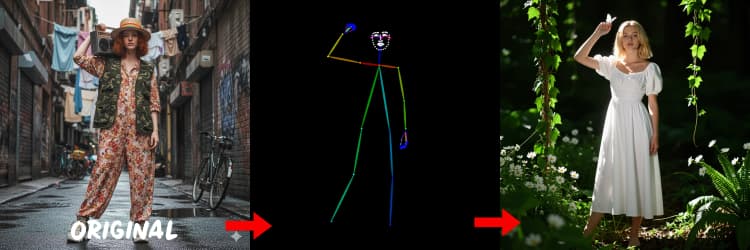
三个预处理器将您的参考转换为控制信号。AIO_Preprocessor (#45) 使用 Depth Anything v2 生成深度,AIO_Preprocessor (#46) 提取 Canny 边缘,DWPreprocessor (#56) 估计全身姿态。使用 ImpactSwitch (#58) 选择哪个信号驱动 Z 图像 ControlNet,并检查 PreviewImage (#43) 确认所选的控制图。选择深度以获取场景几何,Canny 用于清晰的布局或产品拍摄,姿态用于角色工作。
OpenPose 的提示: 1. 全身最佳: OpenPose 在您在提示中包含 "全身" 时效果最佳(约 70-90% 准确率)。 2. 避免特写: 在面部上准确率显著下降。相反,使用 Depth 或 Canny(低/中强度)用于特写。 3. 提示很重要: 提示对 ControlNet 影响很大。避免空提示以防止结果模糊。
放大#
ImageScaleToTotalPixels (#34) 将参考图像调整到实用的工作分辨率以平衡质量和速度。GetImageSizeAndCount (#35) 读取缩放后的大小并将宽度和高度向前传递。EmptyLatentImage (#6) 创建一个匹配您调整后输入纵横比的潜伏画布,以确保构图一致。
输出#
QwenImageDiffsynthControlnet (#39) 将基础模型与 Z 图像 ControlNet 联合补丁和所选控制图像融合,然后 KSampler (#7) 根据您的正负条件生成结果。VAEDecode (#8) 将潜伏转换为图像。工作流程保存两个输出,SaveImage (#31) 写入最终图像,SaveImage (#42) 通过 ImageConcatMulti (#38) 写入比较带,其中包含来源、控制图和结果以便快速质量检查。
Comfyui Z 图像 ControlNet 工作流程中的关键节点#
ImpactSwitch (#58)#
选择哪个控制图像驱动生成(深度、Canny 或姿态)。切换模式以比较每个约束如何影响构图和细节。在迭代布局时使用它以快速测试哪个引导最适合您的目标。
QwenImageDiffsynthControlnet (#39)#
连接基础模型、Z 图像 ControlNet 联合补丁、VAE 和所选控制信号。strength 参数决定模型遵循控制输入与提示的严格程度。为了严格的布局匹配,提高强度;为了更多的创意变化,降低它。
AIO_Preprocessor (#45)#
运行 Depth Anything v2 管道以创建高密度深度图。增加分辨率以获得更详细的结构,或减少以获得更快的预览。与建筑场景、产品拍摄和地形景观配对良好,几何很重要。
DWPreprocessor (#56)#
生成适合人物和角色的姿态图。当四肢可见且不被严重遮挡时效果最佳。如果手或腿缺失,请尝试更清晰的参考或不同帧以获得更完整的身体可见性。
LoraLoaderModelOnly (#54)#
为基础模型应用可选的 LoRA 以获取风格或身份提示。调整 strength_model 以轻柔或强烈地混合 LoRA。您可以换入面部 LoRA 以个性化主题或使用风格 LoRA 锁定特定外观。
KSampler (#7)#
使用您的提示和控制执行扩散采样。调整 seed 以获得可重复性,steps 以获得细化预算,cfg 以获得提示依从性,denoise 以决定输出与初始潜伏的偏离程度。对于图像到图像编辑,降低 denoise 以保持结构;较高的值允许更大的变化。
可选附加功能#
- 为了紧致构图,使用干净、光线均匀的参考进行深度模式,Canny 偏好强对比,姿态偏好全身镜头。
- 对源图像进行细微编辑时,保持 denoise 温和并提高 ControlNet 强度以获得忠实的结构。
- 当需要更多细节时,增加放大组中的目标像素,然后再次减少以快速草图。
- 使用比较输出快速进行深度与 Canny 与姿态的 A/B 测试,并选择最可靠的控制以适应您的主题。
- 使用您自己的面部或风格 LoRA 替换示例 LoRA,以在不重新训练的情况下加入身份或艺术指导。
致谢#
此工作流程实现并建立在以下作品和资源之上。我们感谢 Alibaba PAI 为 Z 图像 ControlNet 的贡献和维护。有关权威详细信息,请参阅下列链接的原始文档和存储库。
资源#
- Alibaba PAI/Z 图像 ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
注意:使用所引用的模型、数据集和代码须遵循其作者和维护者提供的各自许可和条款。

