
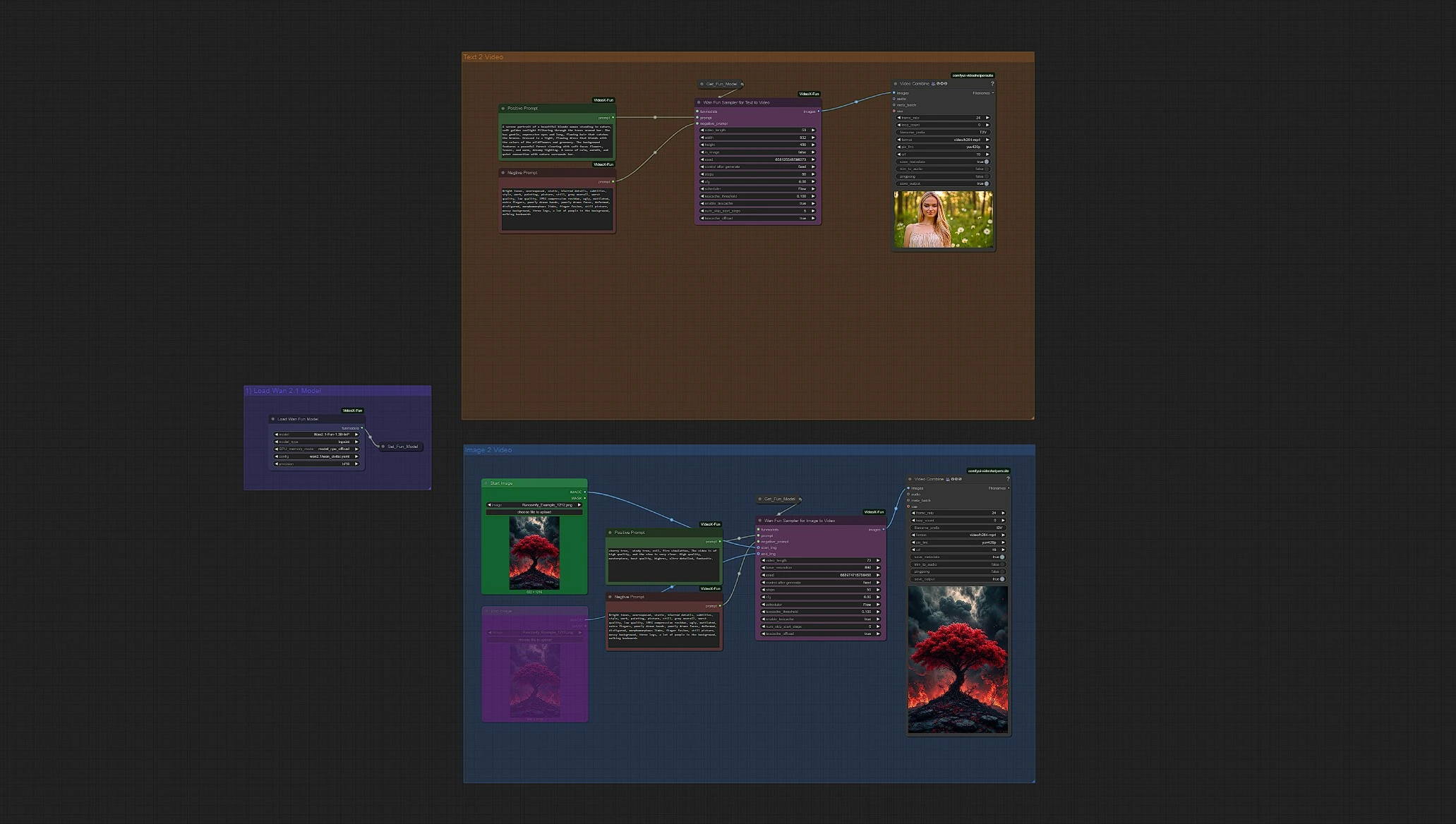
Wan 2.1 Fun | 图像到视频和文本到视频的AI生成#
Wan 2.1 Fun 图像到视频和文本到视频 提供了一个高度多样化的AI视频生成工作流程,将静态视觉和纯粹的想象力变为现实。由Wan 2.1 Fun模型系列驱动,此工作流程允许用户将单个图像动画化为完整视频或直接从文本提示生成整个运动序列,无需初始素材。
无论您是从几句话中创作超现实的梦境,还是将概念艺术作品转化为生动的瞬间,此Wan 2.1 Fun设置使生产连贯、风格化的视频输出变得简单。支持平滑过渡、灵活的时长设置和多语言提示,Wan 2.1 Fun非常适合故事讲述者、数字艺术家和希望以最小开销推动视觉边界的创作者。
为什么使用Wan 2.1 Fun 图像到视频 + 文本到视频?#
Wan 2.1 Fun 图像到视频和文本到视频 工作流程提供了一种简单而富有表现力的方式,从图像或简单的文本提示生成高质量视频:
- 使用自动过渡和效果将单个图像转化为运动
- 通过智能帧预测直接从文本提示生成视频
- 包含InP(开始/结束帧预测),用于控制视觉叙事
- 与1.3B和14B模型变体兼容,以实现可扩展的质量和速度
- 非常适合创意构思、故事讲述、动画场景和电影序列
无论您是从零开始可视化场景,还是为静止图像制作动画,此Wan 2.1 Fun工作流程使用Wan 2.1 Fun模型提供快速、便捷且视觉上令人印象深刻的结果。
如何使用Wan 2.1 Fun 图像到视频 + 文本到视频?#
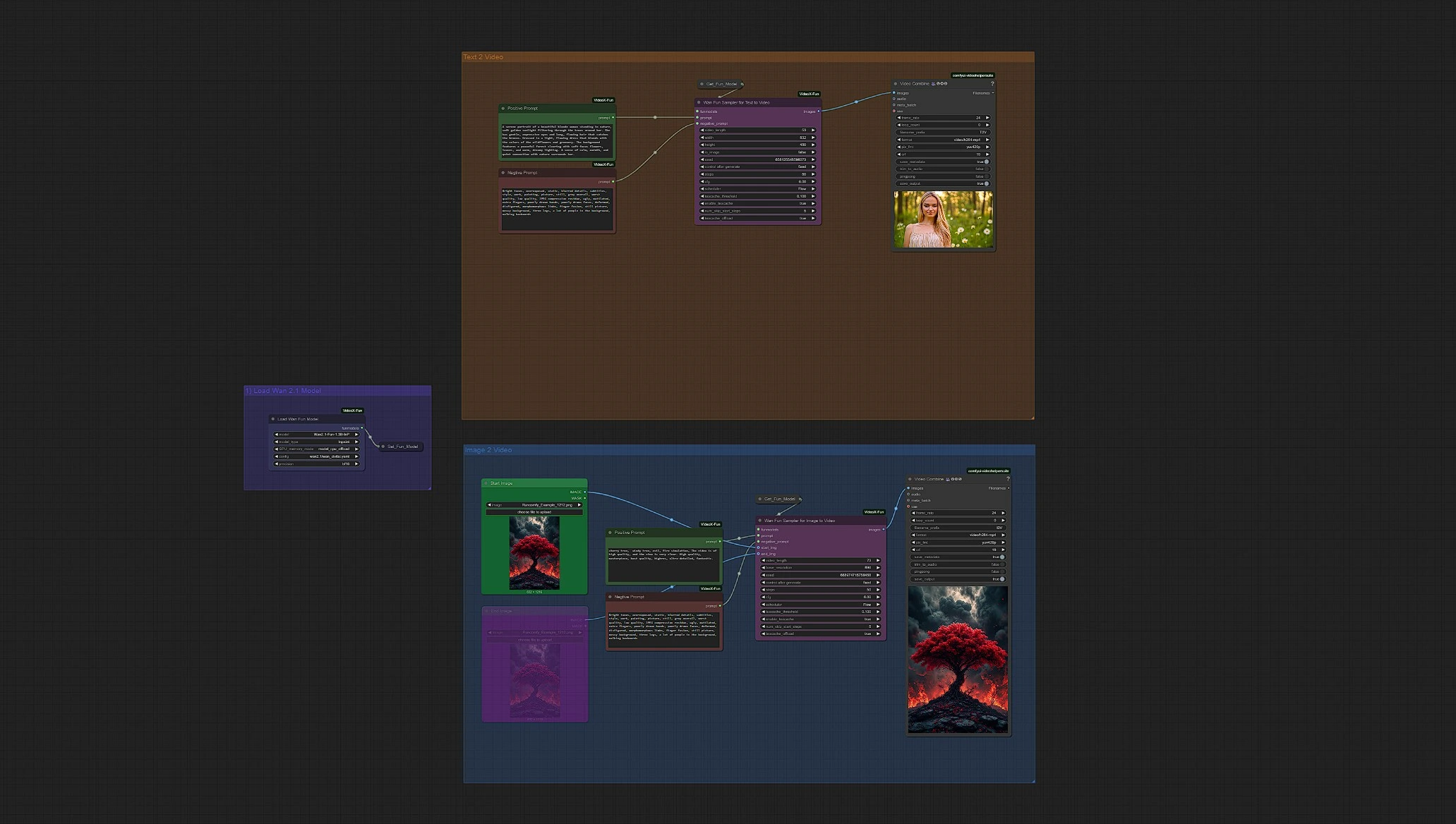
Wan 2.1 Fun 图像到视频 + 文本到视频概述#
Load WanFun Model: 加载合适的Wan 2.1 Fun模型变体(1.3B或14B)Enter Prompts or Upload Image: 支持使用各自的组输入文本提示和图像Set Inference Settings: 调整帧数、时长、分辨率和运动选项Wan Fun Sampler: 使用WanFun进行开始/结束预测和时间一致性Save Video: 采样后自动渲染并保存输出视频
快速开始步骤:#
- 在Load Model Group中选择您的
Wan 2.1 Fun模型 - 输入正面和负面提示以指导生成
- 选择您的输入模式:
- 上传图像到图像到视频组
- 或仅依赖文本提示到文本到视频组
- 在
Wan Fun Sampler节点中调整设置(帧数、分辨率、运动选项) - 点击
Queue Prompt按钮运行工作流程 - 从视频保存节点的
Outputs文件夹中查看并下载您的最终Wan 2.1 Fun视频
1 - 加载WanFun模型#
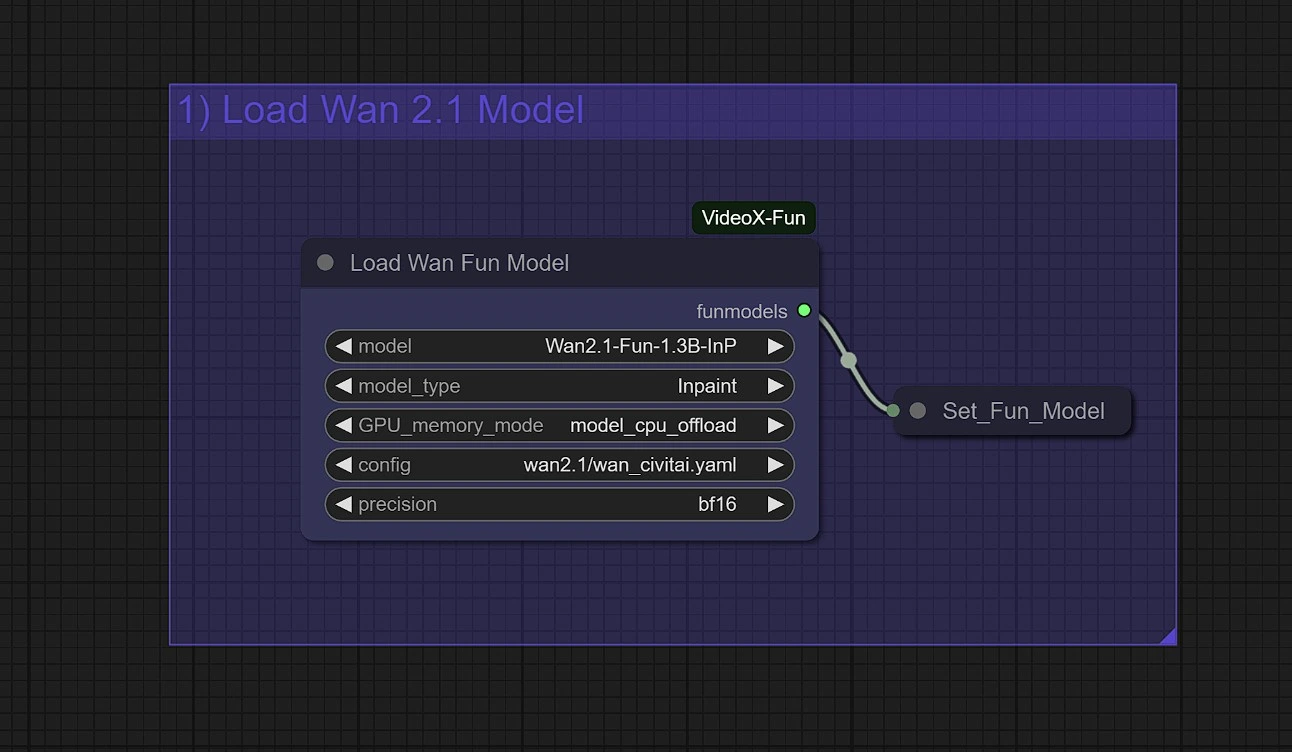
为您的任务选择合适的模型变体:
Wan2.1-Fun-Control (1.3B / 14B): 用于具有深度、Canny、OpenPose和轨迹控制的指导视频生成Wan2.1-Fun-InP (1.3B / 14B): 用于具有开始和结束帧预测的文本到视频
Wan 2.1 Fun的内存提示:
- 使用
model_cpu_offload以更快地生成1.3B Wan 2.1 Fun - 使用
sequential_cpu_offload减少14B Wan 2.1 Fun的GPU内存使用
2 - 输入提示#
在您选择的合适组中,图像到视频组或文本到视频组,输入您的正面和负面提示。
- 正面提示:
- 驱动视频的运动、细节和深度
- 使用描述性和艺术性语言可以增强您最终的Wan 2.1 Fun输出
- 负面提示:
- 使用较长的负面提示,例如"模糊、变异、变形、失真、黑暗和坚固、漫画。"可以增加Wan 2.1 Fun的稳定性
- 添加如"安静、坚固"等词语可以增加Wan 2.1 Fun视频的动态性
3 - 使用Wan 2.1 Fun的图像到视频组#
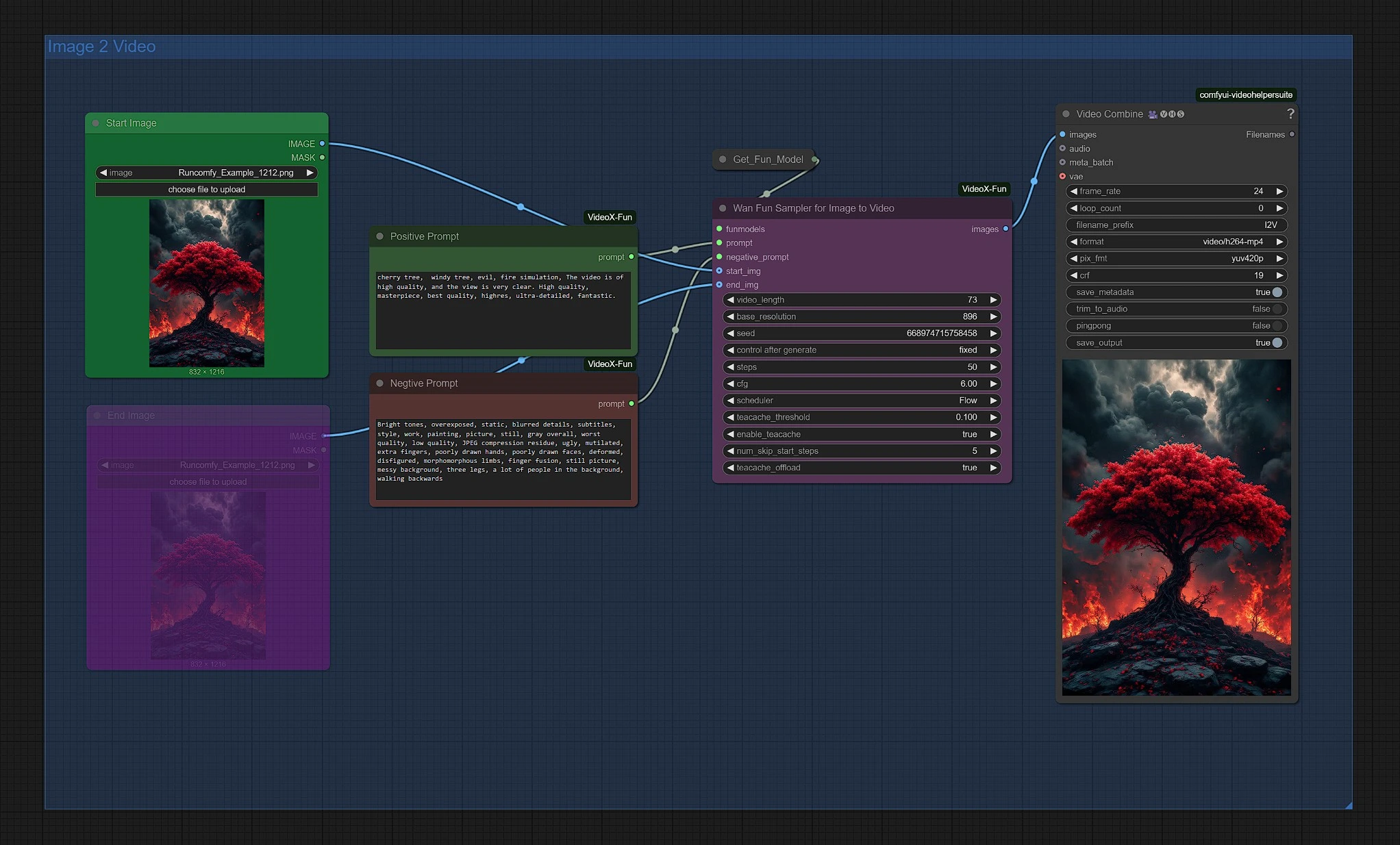
上传您的起始图像以启动Wan 2.1 Fun生成。您可以在Wan Fun Sampler节点中调整分辨率和时长。
[可选] 取消静音结束图像节点;此图像将作为最终图像,之间的图像通过Wan 2.1 sampler渲染。
您的最终Wan 2.1 Fun视频位于视频保存节点的Outputs文件夹中。
4 - 使用Wan 2.1 Fun的文本到视频组#
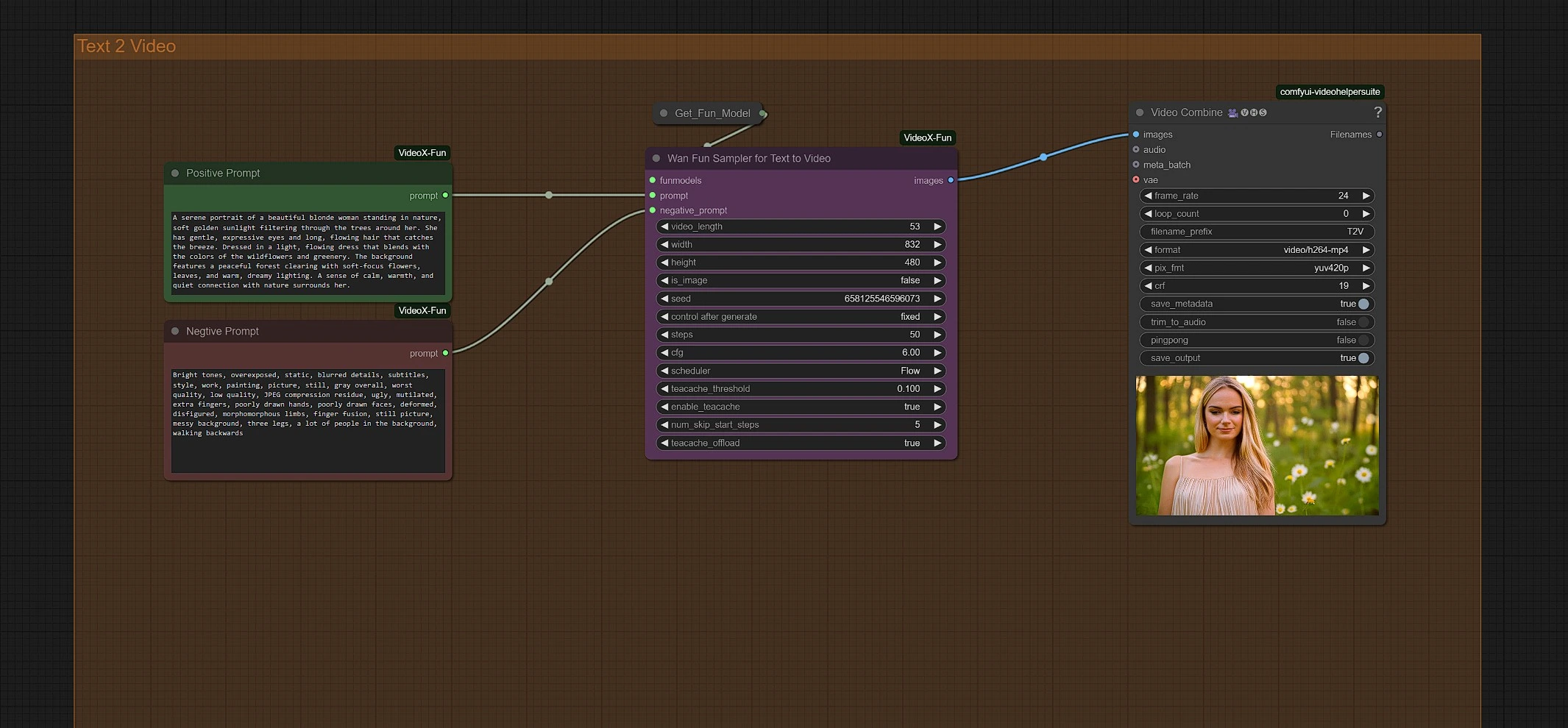
输入您的提示以启动生成。您可以在Wan Fun Sampler节点中调整分辨率和时长。
您的最终Wan 2.1 Fun视频位于视频保存节点的Outputs文件夹中。
致谢#
Wan 2.1 Fun 图像到视频和文本到视频 工作流程由bubbliiiing和hkunzhe开发,他们在Wan 2.1 Fun模型系列上的工作使基于提示的视频生成更加可访问和灵活。他们的贡献使用户能够使用Wan 2.1 Fun将静态图像和纯文本转化为动态、风格化的视频,设置最小而创造自由最大。我们深深感谢他们在AI视频生成领域的创新和持续影响。