
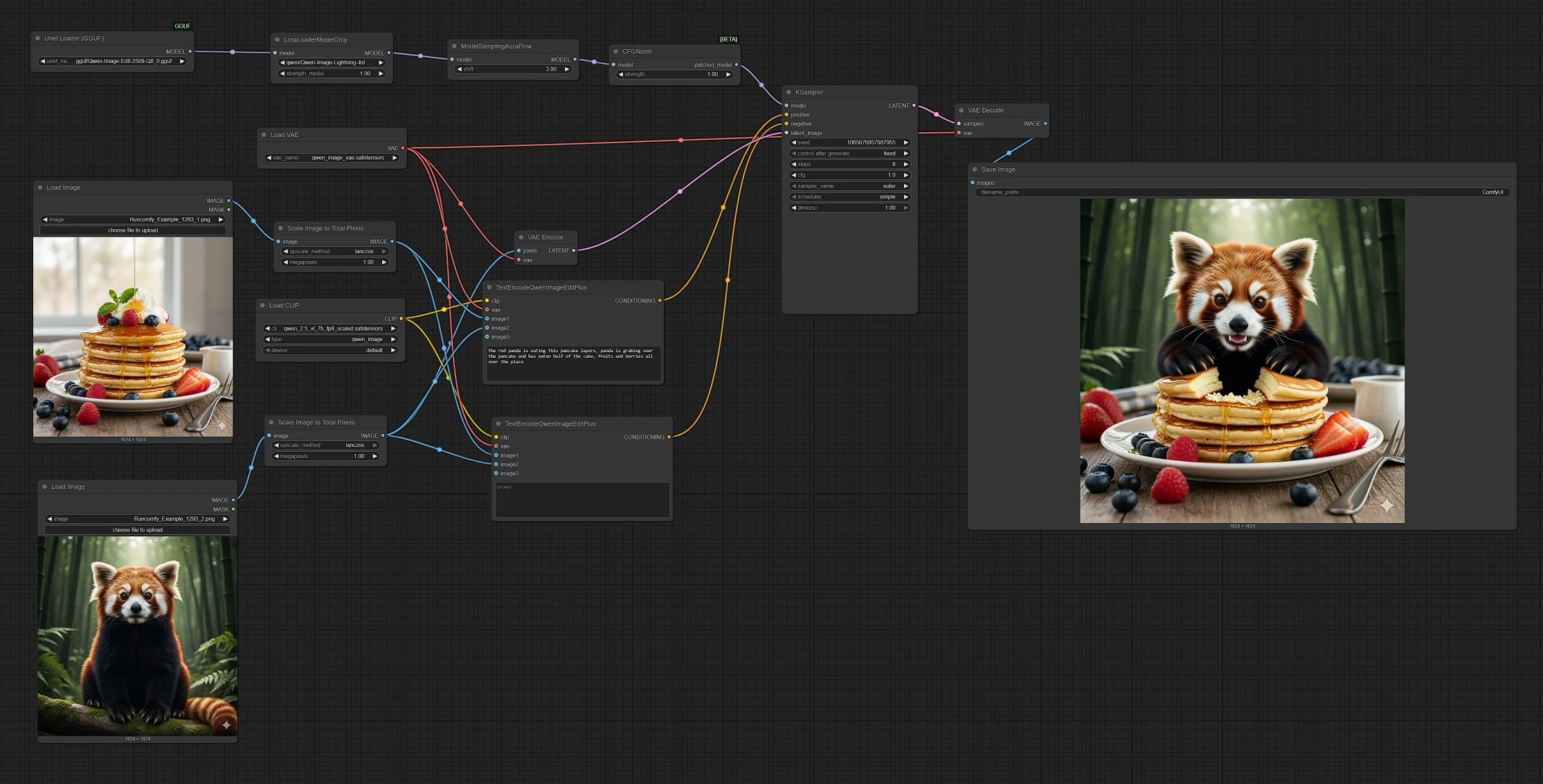






Qwen Image Edit 2509: 多图像、提示驱动的编辑和 ComfyUI 混合#
Qwen Image Edit 2509 是 ComfyUI 的多图像编辑工作流程,它在单一提示下融合 2–3 张输入图像,以创建精确的编辑和无缝的混合。它专为希望合成对象、重塑场景、替换元素或合并参考的创作者设计,同时保持直观和可预测的控制。
此 ComfyUI 图形将 Qwen 图像模型与具有编辑意识的文本编码器配对,以便您可以使用自然语言和一个或多个视觉参考来引导结果。开箱即用,Qwen Image Edit 2509 处理风格迁移、对象插入和场景混音,即使来源在外观或质量上有所不同,也能产生连贯的结果。
Comfyui Qwen Image Edit 2509 工作流程中的关键模型#
- Qwen Image Edit 2509 (Diffusion Model & GGUF, Q8_0)。主要的图像编辑检查点,以量化的形式加载,以减少 VRAM,同时保留编辑行为。它提供了在采样过程中解释文本和参考图像的扩散骨干。
- Qwen Image VAE。专为 Qwen Image 定制的 VAE,将基础画布编码为潜在空间,并将最终结果解码回像素。资产来源:Comfy-Org/Qwen-Image_ComfyUI。
- Qwen 2.5 VL 7B 文本编码器 (FP8 scaled)。为 ComfyUI 打包的视觉语言文本编码器,将您的提示加上参考图像转化为编辑条件。资产来源:Comfy-Org/Qwen-Image_ComfyUI。
- Qwen‑Image‑Lightning‑4steps‑V1.0 LoRA。一个可选的 LoRA,倾向于快速、高影响力的更新,适用于快速迭代或低步数。模型页面:lightx2v/Qwen-Image-Lightning。
如何使用 Comfyui Qwen Image Edit 2509 工作流程#
此工作流程遵循从输入到输出的明确路径:您加载 2–3 张图像,编写提示,图形编码文本和参考,采样在潜在基础上运行,结果被解码并保存。
阶段 1 — 加载并调整您的来源
- 使用
LoadImage(#103) 加载图像 1 和LoadImage(#109) 加载图像 2。图像 2 作为接收编辑的基础画布。 - 每个图像通过
ImageScaleToTotalPixels(#93 和 #108) 处理,以便两个参考共享一致的像素预算。这稳定了合成和风格迁移。 - 如果需要第三个参考,请将另一个
LoadImage插入编码节点上的image3输入。Qwen Image Edit 2509 接受最多三张图像以获得更丰富的指导。
阶段 2 — 编写提示并设定意图
- 正面编码器
TextEncodeQwenImageEditPlus(#104) 将您的文本提示与图像 1 和图像 2 结合起来,以描述您想要的结果。使用自然语言请求合并、替换或风格提示。 - 负面编码器
TextEncodeQwenImageEditPlus(#106) 让您远离不需要的细节。保持为空以保持中立,或添加抑制您不想要的伪影或风格的短语。 - 两个编码器使用 Qwen 文本编码器和 VAE,因此模型“看到”您的参考作为指令的一部分。
阶段 3 — 准备模型
UnetLoaderGGUF(#102) 以 GGUF 格式加载 Qwen Image Edit 2509 骨干,以实现高效推理。LoraLoaderModelOnly(#89) 应用 Qwen‑Image‑Lightning LoRA。增加其影响力以获得更有力的编辑,或减少以获得更保守的更新。- 然后准备好模型进行采样,配置为编辑稳定性。
阶段 4 — 引导生成
- 基础画布(图像 2)由
VAEEncode(#88) 编码,并提供给KSampler(#3) 作为起始潜在。这使得运行图像到图像而不是纯文本到图像。 KSampler(#3) 将正面和负面条件与潜在画布融合,产生编辑结果。锁定种子以确保可重复性,或更改以探索替代方案。- 指导和采样选择在保持对来源的忠实度与提示遵循之间取得平衡,使 Qwen Image Edit 2509 具备精确性和灵活性。
阶段 5 — 解码并保存
VAEDecode(#8) 将最终潜在转换为图像,SaveImage(#60) 将其写入您的输出文件夹。文件名反映运行情况,以便您可以轻松比较版本。
Comfyui Qwen Image Edit 2509 工作流程中的关键节点#
TextEncodeQwenImageEditPlus (#104)#
此节点通过 Qwen 编码器将您的提示与最多三个参考图像结合起来,创建正面编辑条件。使用它来指定应该出现什么,采用哪种风格,以及参考应该如何强烈影响结果。以明确的单句目标开始,然后根据需要添加风格描述符或相机提示。编码器的资产打包在 Comfy-Org/Qwen-Image_ComfyUI。
TextEncodeQwenImageEditPlus (#106)#
此节点形成负面条件,以防止不需要的特征。添加短语以阻止伪影、过度平滑或不匹配的风格。保持简洁以避免与正面意图冲突。它使用与正面路径相同的 Qwen 编码器和 VAE 堆栈。
UnetLoaderGGUF (#102)#
以 GGUF 格式加载 Qwen Image Edit 2509 检查点以进行 VRAM 友好的推理。较高的量化节省内存,但可能略微影响细节;如果有余地,请尝试较少激进的量化以最大化保真度。实现参考:city96/ComfyUI-GGUF。
LoraLoaderModelOnly (#89)#
在基础模型上应用 Qwen‑Image‑Lightning LoRA,以加速收敛并增强编辑。增加 strength_model 以强调此 LoRA 的效果,或降低以获得微妙的指导。模型页面:lightx2v/Qwen-Image-Lightning。核心节点参考:comfyanonymous/ComfyUI。
ImageScaleToTotalPixels (#93, #108)#
使用高质量重采样将每个输入调整到一致的总像素数。提高百万像素目标会在时间和内存的代价下产生更清晰的结果;降低它加快迭代。保持两个参考在相似的比例,以帮助 Qwen Image Edit 2509 干净地混合元素。核心节点参考:comfyanonymous/ComfyUI。
KSampler (#3)#
运行扩散步骤,根据您的条件转换潜在画布。调整步骤和采样器以平衡速度和保真度,并更改种子以从相同设置中探索多个组合。对于保留图像 2 结构的紧密编辑,保持步骤数适中,并依靠提示和参考进行控制。核心节点参考:comfyanonymous/ComfyUI。
可选附加功能#
- 将图像 2 视为画布,将图像 1 视为供体;在提示中描述哪些元素应该转移,哪些应该保留。
- 使用简洁的负面来抑制光晕、纹理漂移或过度风格化;长的负面列表可能与您的目标相冲突。
- 如果结果看起来过于保守,稍微增加 LoRA 强度或采样步骤;如果它们偏离基础太远,请减少它们。
- 在最终确定时提高百万像素目标,然后重用相同的种子以放大您喜欢的确切组合。
- 保持提示具体:主题、动作、设置和风格。Qwen Image Edit 2509 对明确的意图和几个强烈的描述符反应最好。
致谢#
此工作流程实施并构建在以下作品和资源之上。我们感谢 RobbaW 对 Qwen Image Edit 2509 工作流程的贡献和维护。如需权威细节,请参考以下链接的原始文档和存储库。
资源#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- 文档 / 发布说明: Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
注意:使用引用的模型、数据集和代码需遵循其作者和维护者提供的各自许可和条款。



