
Qwen Image 2512 LoRA 推断:管道对齐,训练匹配的 AI Toolkit 生成在 ComfyUI 中#
这个生产就绪的 RunComfy 工作流将一个 AI Toolkit 训练的 LoRA 应用于 Qwen Image 2512 在 ComfyUI 中,重点在于 训练匹配 行为。它集中于 RC Qwen Image 2512 (RCQwenImage2512) ——一个 RunComfy 构建的开源自定义节点 (source),运行一个 Qwen 本地推断管道(而不是通用采样器图形),并通过 lora_path 和 lora_scale 加载你的适配器。
为什么 Qwen Image 2512 LoRA 推断在 ComfyUI 中看起来不同#
Qwen Image 2512 的 AI Toolkit 预览是由特定于模型的管道生成的,包括 Qwen 的“真实 CFG”引导行为和该管道用于条件和采样的默认设置。如果您将同一个作业重建为标准的 ComfyUI 采样器图形,引导语义和 LoRA 补丁点可能会发生变化,因此“相同提示 + 相同种子 + 相同步骤”仍然可能产生不同的结果。在实践中,许多“我的 LoRA 不匹配训练”的报告是管道不匹配,而不是缺少一个参数。
RCQwenImage2512 通过将 Qwen Image 2512 管道包装在节点内并通过 lora_path 和 lora_scale 在该管道中应用 LoRA 来保持推断对齐。管道源:`src/pipelines/qwen_image.py`。
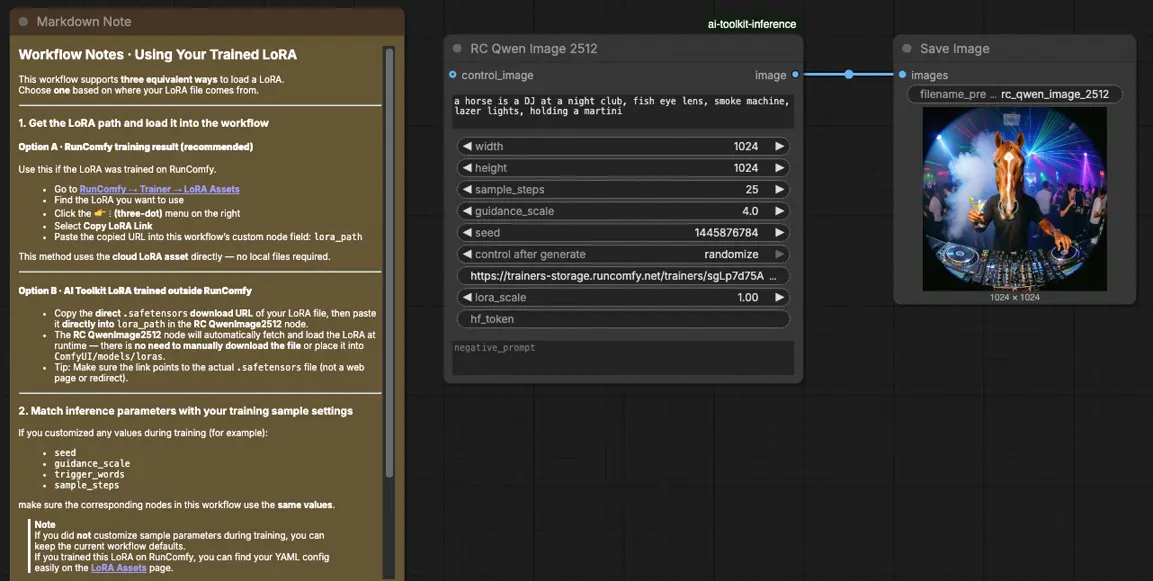
如何使用 Qwen Image 2512 LoRA 推断工作流#
步骤 1: 打开工作流#
在 ComfyUI 中启动云工作流。
步骤 2: 导入您的 LoRA (2 种选项)#
- 选项 A (RunComfy 训练结果): RunComfy → Trainer → LoRA Assets → 找到您的 LoRA → ⋮ → 复制 LoRA 链接

- 选项 B (AI Toolkit LoRA 在 RunComfy 之外训练): 复制您的 LoRA 的直接
.safetensors下载链接并将该 URL 粘贴到lora_path(无需下载到ComfyUI/models/loras)中
步骤 3: 配置 RCQwenImage2512 自定义节点以进行 Qwen Image 2512 LoRA 推断#
将您的 LoRA 链接粘贴到 RC Qwen Image 2512 (RCQwenImage2512) 的 lora_path 中。

然后设置剩余的节点参数(从匹配您在训练期间用于预览/样本生成的值开始):
prompt: 您的正面提示(包括您的 LoRA 所需的任何触发词)negative_prompt: 可选;如果您在预览中未使用负面提示,则保持为空width/height: 输出分辨率(建议为该管道系列的 32 的倍数)sample_steps: 推断步骤;在调整前镜像您的预览步骤计数(25 是常见的基线)guidance_scale: 引导强度(Qwen 使用“真实 CFG”刻度,因此首先重用您的预览值)seed: 锁定种子以验证对齐,将 control_after_generate 设置为 'fixed',然后为新样本改变它lora_scale: LoRA 强度;从您的预览值附近开始并小幅调整
这是一个文本到图像的工作流,因此您不需要提供输入图像。
训练对齐注意事项:如果您在训练期间自定义了采样,请打开您的 AI Toolkit 训练 YAML 并镜像 width、height、sample_steps、guidance_scale、seed 和 lora_scale。如果您在 RunComfy 上训练,请打开 Trainer → LoRA Assets → 配置并在您迭代之前将预览/样本值复制到 RCQwenImage2512 中。

步骤 4: 运行 Qwen Image 2512 LoRA 推断#
点击 Queue/Run。SaveImage 节点将生成的图像保存到您的标准 ComfyUI 输出文件夹中。
Qwen Image 2512 LoRA 推断的故障排除#
RunComfy 的 RC Qwen Image 2512 (RCQwenImage2512) 自定义节点旨在通过以下方式保持与 Qwen Image 2512 预览样式采样的推断 管道对齐:
- 在节点内执行一个 Qwen 本地推断管道(而不是通用采样器图形),并且
- 通过
lora_path+lora_scale在该管道内注入 LoRA(一致的补丁点)。
(1)Qwen-Image Loras 在 comfyui 中不起作用#
为什么会发生这种情况
用户报告称 AI Toolkit 训练的 Qwen-Image LoRA 可能无法在 ComfyUI 中应用,因为 LoRA 状态字典键前缀与 ComfyUI 侧加载器/推断路径期望的不匹配(因此适配器“静默”加载但实际上没有补丁 Qwen 变压器模块)。
如何修复(用户验证的选项)
- 使用 RCQwenImage2512 进行管道级 LoRA 注入: 仅通过 RCQwenImage2512 上的
lora_path+lora_scale加载适配器(在调试时避免在顶部堆叠额外的 LoRA 加载器节点)。这使 LoRA 补丁点与预览样式采样使用的 Qwen 管道保持一致。 - 如果必须使用非 RC 推断提供者/加载路径: 用户报告的解决方案是通过将 LoRA 键前缀的第一个段从
diffusion_model→transformer重命名 LoRA 键,以便权重映射到预期的 Qwen 变压器模块(查看问题以获取确切上下文以及为什么需要这样做)。
(2)使用 inference_lora_path 与 qwen image 时崩溃的补丁(允许使用 turbo lora 生成样本)#
为什么会发生这种情况
一些用户在尝试通过 AI Toolkit 的 inference_lora_path 流加载 Qwen 的推断 LoRA(包括 Qwen-Image-2512)时遇到崩溃。这不是“提示/CFG/种子”问题,而是推断加载路径问题。
如何修复(用户验证)
- 应用补丁/更新到包含问题中描述的补丁的版本。 问题作者报告该补丁修复了在加载 Qwen 的推断 LoRA 时的崩溃(查看问题以获取确切的更改和配置上下文)。
- 专门用于 ComfyUI 推断: 优先 RCQwenImage2512 并在 RC 节点内通过
lora_path/lora_scale加载适配器。这避免了依赖外部推断 LoRA 加载路径,并保持管道与预览样式采样一致。
(3)在 comfyui 中使用 sageattention 2 qwen-image 显示黑色图像由于 NaNs(即黑色图像)#
为什么会发生这种情况
用户报告称在 ComfyUI 中运行 Qwen Image 与 SageAttention 可以产生 NaNs,从而变成 黑色图像。这可能看起来像“我的 LoRA 坏了”,但实际上是注意力后端产生了无效值——管道执行在您可以有意义地评估 LoRA 行为之前失败。
如何修复(用户验证)
- 不要对 Qwen Image 使用
--use-sage-attention当它导致 NaNs/黑色输出时。 首先验证干净基线(非黑色输出),然后评估 LoRA 影响。 - 如果您需要 SageAttention 加速: 通过强制 CUDA 后端路径修复 Qwen 黑色输出。在实践中,这通常意味着使用工作流级补丁(例如,“Patch Sage Attention”节点)并选择一个 CUDA 后端变体,避免受影响的 GPU/架构的损坏 Triton 路径。
- 在您获得稳定的(非黑色)基线输出后,通过 RCQwenImage2512 运行 Qwen Image 2512 推断,以便在您匹配
width/height/sample_steps/guidance_scale/seed/lora_scale时管道和 LoRA 注入点保持预览对齐。
立即运行 Qwen Image 2512 LoRA 推断#
打开共享工作流,将您的 LoRA URL 粘贴到 lora_path 中,匹配您的预览采样值,然后运行 RCQwenImage2512 以在 ComfyUI 中进行训练匹配的 Qwen Image 2512 生成。
