
使用 Wan2.2 S2V 的姿势控制唇同步:音频驱动,姿势控制的图像到视频,用于富有表现力的头像#
使用 Wan2.2 S2V 的姿势控制唇同步将单个图像、音频剪辑和姿势参考视频转变为同步的说话表演。您的参考图像中的角色将跟随参考视频的身体运动,而唇部动作与音频匹配。此 ComfyUI 工作流非常适合需要对姿势、表情和语音时间进行严格控制的头像、故事场景、预告片、解释器和音乐视频。
基于 Wan 2.2 S2V 14B 模型家族,工作流融合了文本提示、干净的声乐特征和姿势地图,以生成具有稳定身份的电影级动作。它旨在操作简单,同时为创作者提供对外观、节奏和框架的精细控制。
ComfyUI 中 Wan2.2 S2V 工作流的关键模型#
- Wan2.2-S2V-14B。核心的语音到视频生成器,将静止图像加音频转化为视频,可选择姿势条件进行运动引导。请参阅官方存储库和模型卡以了解功能和使用说明:Wan-Video/Wan2.2 和 Wan-AI/Wan2.2-S2V-14B。
- Wan VAE。Wan 自动编码器以高保真度对视频潜在变量进行编码和解码,并在 Wan 2.x 管道中使用。参考实现:Wan 管道在 Diffusers 文档。
- Google UMT5-XXL 文本编码器。提供强大的多语言文本条件,用于高层次场景意图和风格控制在 Wan 管道中。模型卡:google/umt5-xxl。
- Facebook Wav2Vec2-Large。提取驱动唇同步和微表情的稳健语音特征。模型卡:facebook/wav2vec2-large-960h。
- DWPose 与 YOLOX 检测器。生成参考视频的人体姿势关键点和姿势地图,以引导全身运动。存储库:IDEA-Research/DWPose 和 Megvii-BaseDetection/YOLOX。
- LightX2V LoRA for Wan。一种轻量级的 LoRA,用于在保持运动质量的同时加速低步图像到视频风格去噪;Wan 2.2 支持其去噪器中的 LoRAs。请参阅 Wan Diffusers 中关于 LoRA 使用的指南:Wan 管道。
如何使用 ComfyUI 中的 Wan2.2 S2V 工作流的姿势控制唇同步#
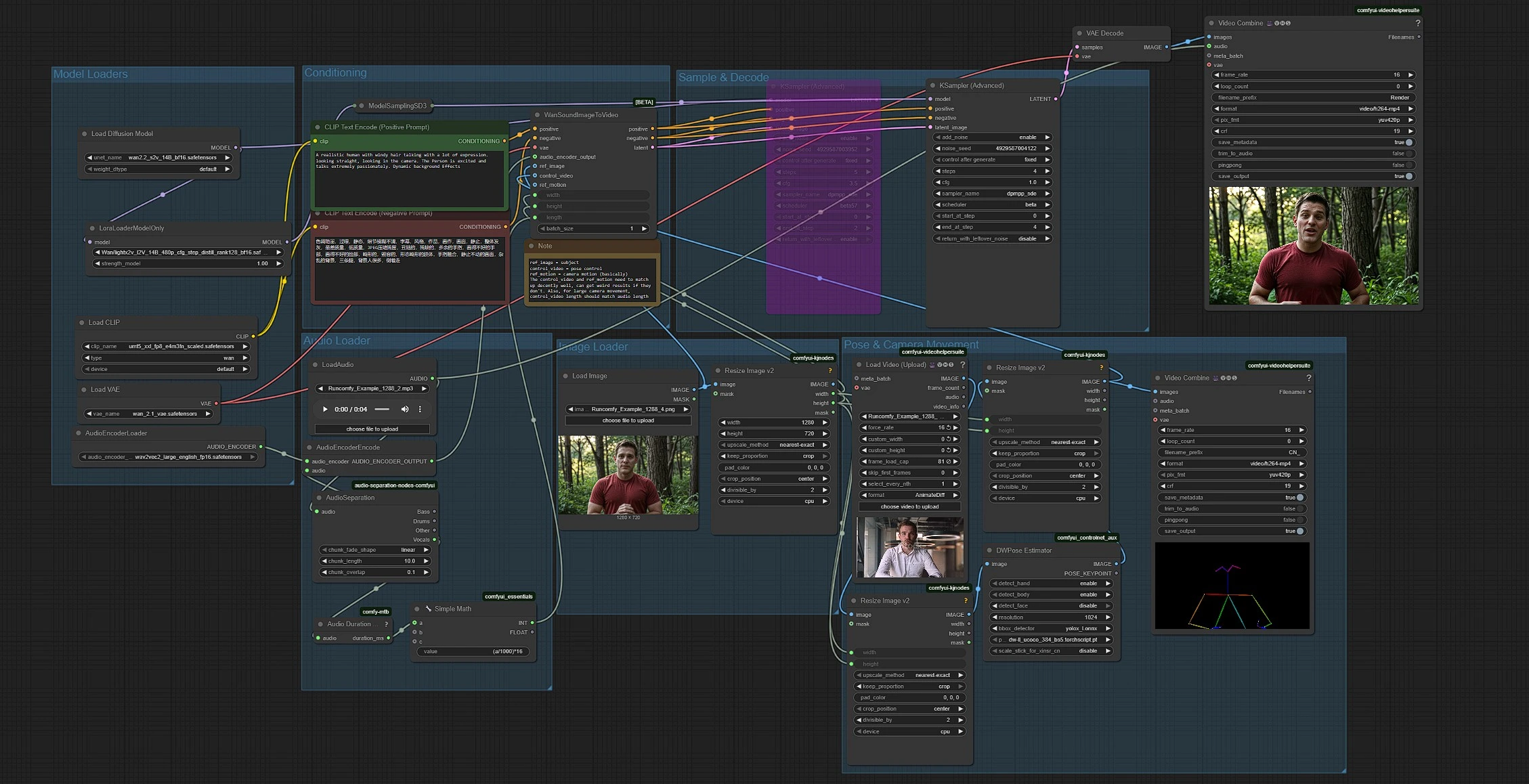
工作流结合了五个部分:模型加载、音频准备、图像和姿势输入、条件和生成。组以从左到右的流程运行,音频长度自动设置剪辑持续时间为 16 fps。
模型加载器#
此组加载 Wan 2.2 S2V 模型、其 VAE、UMT5-XXL 文本编码器和 LightX2V LoRA。基础变压器在 UNETLoader (#37) 中初始化,并通过 LoraLoaderModelOnly (#61) 进行调整,以加快低步采样速度。Wan VAE 由 VAELoader (#39) 提供。文本编码器由 CLIPLoader (#38) 提供,加载由 Wan 引用的 UMT5-XXL 权重。除非您更换模型文件,否则您几乎不需要接触此组。
音频加载器#
通过 LoadAudio (#58) 放入音频文件。AudioSeparation (#85) 隔离声乐主干,以便唇部跟随清晰的语音或歌唱而非背景乐器。Audio Duration (mtb) (#70) 测量剪辑并通过 SimpleMath+ (#71) 将持续时间转换为 16 fps 的帧计数,以便视频长度与音频匹配。AudioEncoderEncode (#56) 提供 Wav2Vec2-Large 编码器,以便 Wan 可以将音素映射到口型以实现准确的唇同步。
图像加载器#
LoadImage (#52) 提供携带身份、服装和相机设置的主题静态图像。ImageResizeKJv2 (#69) 从图像中读取尺寸,以便管道在所有后续阶段一致地得出目标宽度和高度。使用清晰、正面朝向且嘴部无遮挡的图像,以获得最忠实的唇部动作。
姿势和相机运动#
VHS_LoadVideo (#80) 导入您的姿势参考视频。ImageResizeKJv2 (#83) 将帧调整为目标大小,DWPreprocessor (#78) 使用 YOLOX 检测和 DWPose 关键点将其转换为姿势地图。最终的 ImageResizeKJv2 (#81) 将姿势帧与生成分辨率对齐,然后将其作为控制视频传递。您可以通过路由到 VHS_VideoCombine (#95) 预览姿势输出,以帮助确认参考框架和时间是否适合您的主题。
条件#
在 CLIP Text Encode (Positive Prompt) (#6) 中编写风格和场景意图,并使用 CLIP Text Encode (Negative Prompt) (#7) 来避免不需要的伪影。提示引导高层次的美学和背景运动,而音频驱动唇部动作,姿势参考管理身体动态。保持提示简洁,并与目标相机角度和情绪一致。
采样与解码#
WanSoundImageToVideo (#55) 融合文本、音频特征、参考图像和姿势控制视频,然后准备潜在序列。KSamplerAdvanced (#64) 执行适合 LightX2V 风格加速的低步去噪,VAEDecode (#8) 重构帧。VHS_VideoCombine (#62) 将帧组合成 MP4,并附加您的原始音频,使输出可以立即查看或编辑。
ComfyUI 中 Wan2.2 S2V 工作流的关键节点#
WanSoundImageToVideo (#55)#
工作流的核心,使用您的提示、声乐、主题图像和姿势控制视频对 Wan2.2-S2V 进行条件设置。只调整重要的:设置 width、height 和 length 以匹配您的主题图像和音频长度,并插入预处理的姿势视频以进行运动控制。除非您计划注入单独的相机轨道,否则将 ref_motion 留空。模型的语音到视频行为在 Wan-AI/Wan2.2-S2V-14B 和 Wan-Video/Wan2.2 中描述。
DWPreprocessor (#78)#
使用 YOLOX 进行检测和 DWPose 生成全身关键点的姿势地图。强大的姿势提示帮助 Wan 跟随四肢和躯干,而音频控制嘴唇和表情。如果您的参考有大量相机运动,请使用与预期表演对齐的视角和时间的姿势视频。DWPose 及其变体的文档在 IDEA-Research/DWPose 中。
KSamplerAdvanced (#64)#
执行潜在序列的去噪。加载 LightX2V LoRA 后,您可以保持步骤低以快速预览,同时保持运动一致性;在追求最大细节时增加步骤。调度器选择影响运动的平滑度与清晰度,应与 LoRA 使用一起调整,如 Wan 在 Diffusers 文档 中所述。
VHS_LoadVideo (#80)#
导入并擦拭您的姿势参考。使用其节点内的帧选择工具选择与您的音频片段匹配的确切片段。保持与参考图像一致的框架和主题大小将稳定运动传输。该节点是 VideoHelperSuite 的一部分:ComfyUI-VideoHelperSuite。
VHS_VideoCombine (#62)#
将生成的帧和您的音频组合成 MP4,并保存工作流元数据。将输出帧率设置为 16 fps,以匹配此工作流中从音频持续时间计算的帧数。根据您的资产管理需求禁用或启用元数据保存。请参阅 VideoHelperSuite 文档:ComfyUI-VideoHelperSuite。
AudioSeparation (#85)#
隔离声乐,以便 Wav2Vec2 特征在没有乐器或效果干扰的情况下驱动口型。如果您的输入已经是清晰的语音,您可以绕过分离。为获得最佳效果,请保持音频水平一致并尽量减少混响。
可选额外功能#
- 为获得最佳唇同步,优先选择清晰的语音或清唱声乐。Wav2Vec2 在 16 kHz 下工作;大多数管道会自动重新采样,但提供 16 kHz 文件有帮助。
- 使用光线充足、正面朝向且可见牙齿和嘴唇的主题图像。遮挡会降低准确性。
- 使姿势参考的框架和运动与您的主题匹配。当姿势视频长度与音频片段匹配时,大量相机移动效果最佳。
- 从 480p 开始快速迭代;为最终质量移至 720p。Wan 2.2 在 S2V 中支持这两种分辨率。
- 保持提示简短,并与图像和姿势参考中的相机设置一致,以避免冲突。
- 如果您尝试使用 LoRAs,请确保它们与 Wan 2.2 的去噪器兼容。请参阅 Wan Diffusers 文档 中的 LoRA 注释。
此使用 Wan2.2 S2V 的姿势控制唇同步工作流为您提供了一条从音频和静态图像到可控、合拍的表演的快速路径,看起来连贯且富有表现力。
致谢#
此工作流实现并基于以下作品和资源。我们感谢 @ArtOfficialLabs 的 Pose Control LipSync with Wan2.2 S2VDemo 的贡献和维护。有关权威细节,请参阅下方链接的原始文档和存储库。
资源#
- YouTube/Pose Control LipSync with Wan2.2 S2VDemo
- 来自 @ArtOfficialLabs 的文档 / 发布说明:Pose Control LipSync with Wan2.2 S2VDemo
注意:使用引用的模型、数据集和代码需遵循其作者和维护者提供的相应许可证和条款。