
LTX 2.3 双角色唇同步 LoRA:从一张图像和一个音轨生成双角色唇同步视频#
这个 ComfyUI 工作流将单幅静止图像和录制的双讲者对话转换为连贯的、身份稳定的视频,为屏幕上的两个角色同步语音。基于 LTX‑2.3 视频骨干和 LTX 2.3 双角色唇同步 LoRA 构建,它将您的对话中的音素和时序映射到每张面孔,同时在帧间保持表情、注视和场景一致性。
设计用于采访、电影对话、带视频主持人的播客和虚拟角色互动,该工作流将场景布局的文本提示与音频驱动的动作相结合。它包括图像引导阶段以快速开发外观、两阶段 LTX 采样以实现时间稳定性,以及潜在放大器以获得清晰的结果。最终输出是嵌入音频的 MP4。
Comfyui LTX 2.3 双角色唇同步 LoRA 工作流中的关键模型#
- LTX‑2.3 视频生成模型。提供多模态扩散骨干,合成基于文本、图像和音频条件的时间一致视频。Lightricks/LTX-2.3
- LTX‑2.3 视频 VAE 和音频 VAE。编码和解码模型使用的视频和音频潜在变量,以保持生成效率和同步。随 LTX‑2.3 版本一起发布。Lightricks/LTX-2.3
- LTX 空间潜在放大器。在基础通过后,通过在潜在空间中上采样来优化细节,以获得更清晰的纹理和边缘。LTX 资产旁有变体可用。Lightricks/LTX-2
- LTX 2.3 双角色唇同步 LoRA。注入训练,鼓励同一镜头中两张脸的每个讲者的嘴部运动和时序,同时保留面部身份。
- Z‑Image Turbo 文本到图像模型。快速生成高质量的参考静态图像,在视频合成前锚定身份、构图和照明。Comfy‑Org/z_image_turbo
此工作流使用的相关节点包:ComfyUI‑KJNodes、ComfyUI‑VideoHelperSuite、rgthree‑comfy 和 ComfyUI‑PromptRelay。
如何使用 Comfyui LTX 2.3 双角色唇同步 LoRA 工作流#
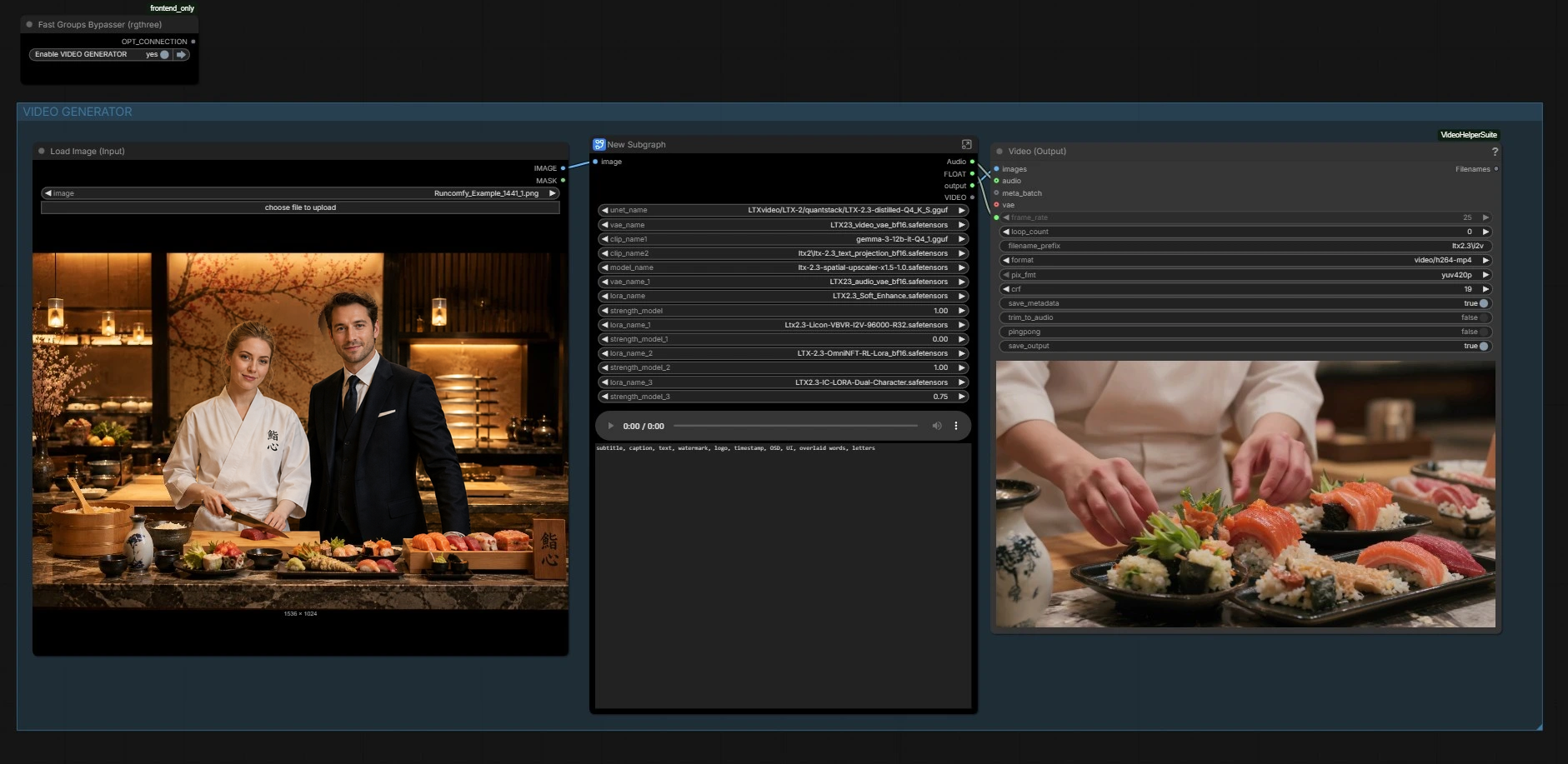
该工作流有两个协调的部分:一个图像生成器,用于创建主要帧,和一个视频生成器,从音频中驱动运动和唇同步,同时保留外观。使用以下组作为您的指南。
图像生成器#
此部分构建锚定静止图像。使用提示列表中的场景预设快速草拟构图,然后使用角色描述细化文本。一个紧凑的图像扩散堆栈(“Z IMG TURBO” 子图)对您的提示进行编码,并采样一个干净的参考静止图像。图像被解码并保存以供检查,然后向前传递以进行视频的身份和布局种子。
您在这里触摸的关键输入:场景、服装和两个不同角色的描述性提示;避免使用镜头或渲染术语,除非该外观是有意的。
模型#
在这里,图加载 LTX‑2.3 骨干,它的视频和音频 VAE,文本编码器和潜在放大器。它还应用了 LTX 2.3 双角色唇同步 LoRA,如果您启用了它们,还可以选择样式或增强 LoRA。如果您想交换权重或调整 LoRA 影响,则无需采取行动。
自定义音频#
在此处提供您的对话音轨。音频文件被加载并编码为音频潜在变量,通过管道传递时序和音素提示。如果您不提供音频,工作流可以使用空音频潜在变量生成运动,但 LTX 2.3 双角色唇同步 LoRA 设计为与真实对话一起使用。使用清晰的双讲者混音,清晰的轮流交替以获得最佳的嘴部运动分离。
视频参数#
设置目标持续时间和帧速率。这些值在采样、调度、剪裁指南和最终渲染过程中存储并重复使用,因此嘴唇、眨眼和镜头时序保持一致。保持视频长度与提供的音频一致,以避免多余的前奏或尾声。
潜在生成#
您选择的静止图像被预处理并检测其尺寸。工作流创建适当长度的视频潜在变量,然后将静止图像插入到位,以便第一个帧与您的设计匹配。应用全帧噪声遮罩以控制背景与面孔的演变程度。准备好的音频潜在变量然后与视频潜在变量配对,以便两个模态都准备好进行条件化。
值得注意的节点:LTXVPreprocess 为 LTX 缩放您的静止图像,EmptyLTXVLatentVideo 构建时间轴,LTXVImgToVideoInplaceKJ (#5881) 通过从静止图像中种子第一个帧来锁定身份。
条件化#
文本提示被编码并附加为正面和负面条件。使用全局提示框以自然语言描述舞台和意图;如果有帮助,您可以包括一个简短的镜头列表。专用的负面文本编码器抑制帧上的字幕、水印和 UI,以保持面孔的清洁。剪裁指南助手分析潜在变量,以将注意力集中在两个面孔上,提高 LTX 2.3 双角色唇同步 LoRA 活动时的每个讲者的表情跟踪。
代表性组件:PromptRelayEncode (#5903) 将您的场景描述与潜在上下文合并,LTXVConditioning 附加帧速率感知引导以适应两种模态。
第一次采样#
第一次去噪通过生成一个时间一致的基础视频,唇部运动被阻塞。轻量级调度器和采样器自动选择,参数从存储的时序值路由。LTX2_NAG 输出的模型变体为视频和音频条件添加噪声感知指导,以便在内容成形时保持语音时序锚定。
核心采样器路径:SamplerCustom (#5891) 配合 KSamplerSelect 和基本调度器;仅在您有特定采样器偏好时调整。
第二阶段放大和精细化#
第二阶段改善了锐度和微表情。潜在放大器增加了空间细节,音频和视频潜在变量重新结合,并且精细化采样器进行细微的修正,同时保留既定的运动。此后,潜在变量被分离并解码回图像序列和音频波形。
重要的模块:LTXVLatentUpsampler (#5927) 提供清晰度,SamplerCustomAdvanced (#5929) 用于精细化通过,随后使用 VAEDecode 和 LTXVAudioVAEDecode 返回到像素和音频空间。
输出#
最后,帧和音频被打包成一个 MP4 以供播放和审核。用于条件化的帧速率在此处重用,因此视觉节奏和音素时序与模型在生成期间看到的一致。如果需要快速检查,您还可以在中途预览音频。
输出路径:CreateVideo (#5931) 构建剪辑;提供辅助 VHS_VideoCombine (#5905) 路径,用于具有元数据控制的备用导出。
Comfyui LTX 2.3 双角色唇同步 LoRA 工作流中的关键节点#
LTXICLoRALoaderModelOnly(#5958) 将 LTX 2.3 双角色唇同步 LoRA 加载到 LTX‑2.3 骨干中。当您需要更紧的嘴部动作和讲者分离时增加strength_model;当您希望基础模型的运动和风格占主导地位时降低它,尤其是在您堆叠额外的风格 LoRA 时。PromptRelayEncode(#5903) 编写场景描述和(可选)简短镜头计划的中央位置。它将全局提示与模型上下文和当前潜在融合,以便跨时间线保持指导一致。保持语言清晰,并清晰地描述两个角色,以帮助身份和角色分离。LTXVImgToVideoInplaceKJ(#5881) 直接从您生成或加载的静止图像中种子视频潜在变量的第一帧。这样锁定身份、服装和照明,减少随时间的漂移。使用中或中宽的双镜头,两张脸都没有被遮挡,以获得最佳效果。LTXVAudioVAEEncode(#5851) 将提供的对话音轨转换为模型可用于音素时序的音频潜在变量。提供干净的混音,没有重压缩;确保开始时间与屏幕上的第一次讲话对应,以避免偏移唇部运动。SamplerCustom(#5891) 和SamplerCustomAdvanced(#5929) 两个互补的去噪阶段。保持采样器家族在阶段之间一致,以保持运动连续性,并避免在找到您喜欢的外观后对噪声调度进行剧烈更改。LTXVLatentUpsampler(#5927) 在精细化之前应用 LTX 潜在放大器,以增加清晰度而不破坏既定的运动。选择适合您的目标分辨率和纹理真实感的放大器变体。
可选附加功能#
- 使用 24 kHz 的双讲者 WAV,背景噪音最少;在台词之间添加短暂的自然停顿,以帮助 LTX 2.3 双角色唇同步 LoRA 分离轮流。
- 生成或提供一个静止图像,其中两个主体可见,面向摄像机,面部光线一致。
- 保留排除“字幕、标题、标志、时间戳”的负面文本提示,以避免采样期间出现烧录的 UI 元素。
- 从短片开始验证时序,然后在您喜欢的行为后延长持续时间或提高分辨率。
- 如果您添加风格 LoRA,请在 LTX 2.3 双角色唇同步 LoRA 中平衡它们,以便在保持 articulation 准确的同时,场景保留您选择的美学。
致谢#
此工作流实现并构建在以下作品和资源之上。我们对“LTX 2.3 双角色唇同步 LoRA 工作流源”的创建者表示感谢。有关权威详细信息,请参阅下面链接的原始文档和存储库。
资源#
- LTX 2.3 双角色唇同步 LoRA 工作流源/LTX 2.3 双角色唇同步 LoRA 工作流源
- 文档 / 发行说明:YouTube 视频
注意:引用模型、数据集和代码的使用受其作者和维护者提供的各自许可和条款的约束。