
Janus-Pro 是一个前沿的自回归框架,统一了多模态理解和生成,解决了以往方法的关键限制。通过将视觉编码解耦为独立路径,同时保持单一的变压器架构,Janus-Pro 消除了感知与合成之间的冲突,提高了多模态 AI 的灵活性和性能。使用 Janus-Pro,用户可以在视觉理解和内容生成之间实现更精细的平衡,使 Janus-Pro 成为下一代 AI 解决方案的卓越选择。
Janus-Pro 设计的核心是其创新的双通道视觉编码策略,使 Janus-Pro 能够更有效地处理视觉输入而不牺牲生成能力。与传统的统一模型在理解和生成之间的平衡上挣扎不同,Janus-Pro 通过为这两项任务分配专用编码路径,同时利用单一强大的变压器进行处理,实现了优化。这种方法使 Janus-Pro 能够无缝适应多样的多模态任务,从图像合成到文本引导生成,强化了 Janus-Pro 超越现有 AI 框架的能力。
在统一的多模态模型中,一个主要的挑战是无需任务特定架构即可在广泛任务中保持高性能。Janus-Pro 通过其精简但高度适应的框架克服了这一点,超越了以往的统一模型,甚至匹配或超过了专门任务特定解决方案的性能。凭借其简单性、灵活性和卓越的有效性,Janus-Pro 代表了多模态 AI 的重大进步。Janus-Pro 正在为下一代统一模型树立新的基准,证明 Janus-Pro 是多模态 AI 技术的未来。
1.1 如何使用 Janus-Pro 工作流?#
您可以通过两种方式使用 Janus-Pro 工作流
- Janus-Pro 图像生成
- Janus-Pro 图像描述(OCR,字幕,描述...等)
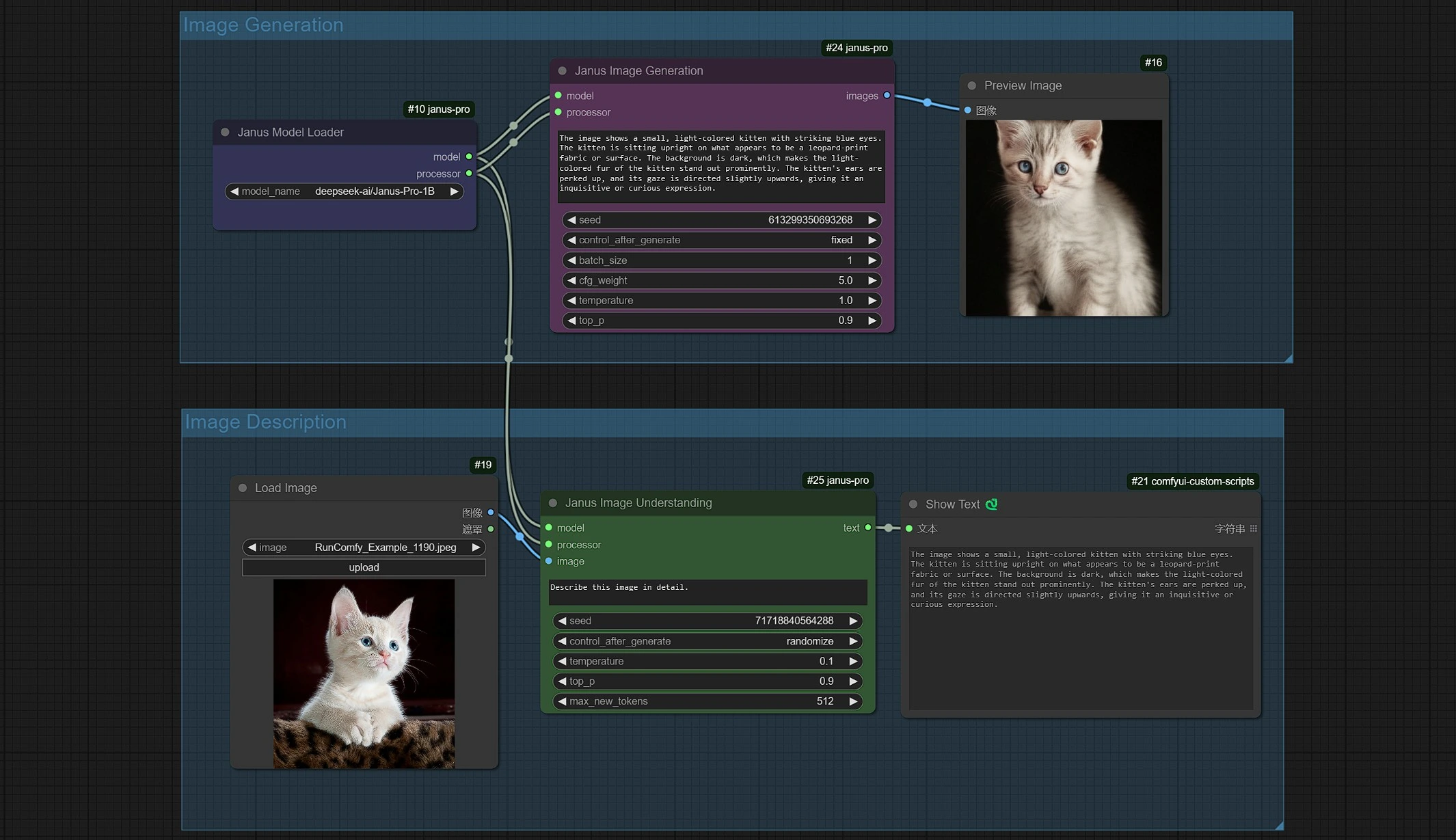
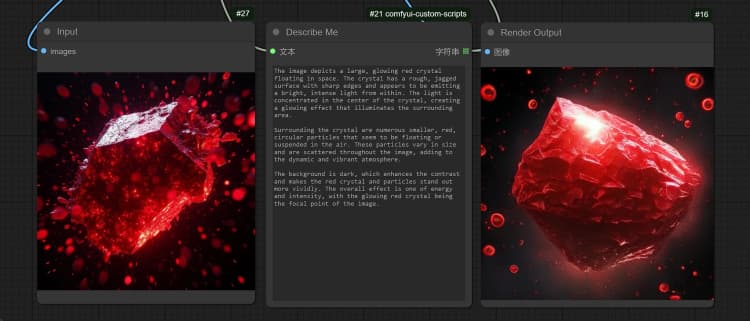
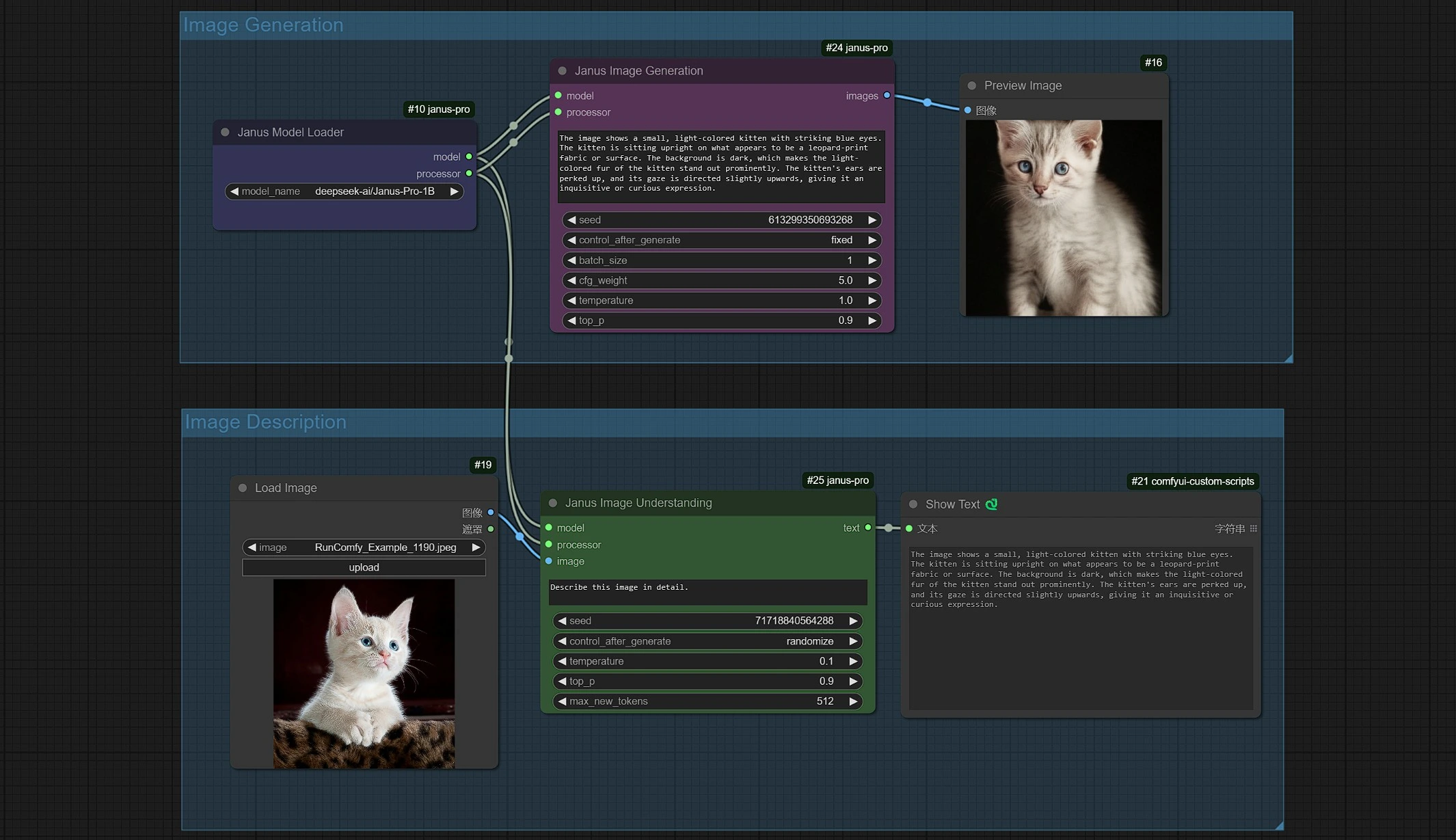
1.2 Janus-Pro 图像生成#
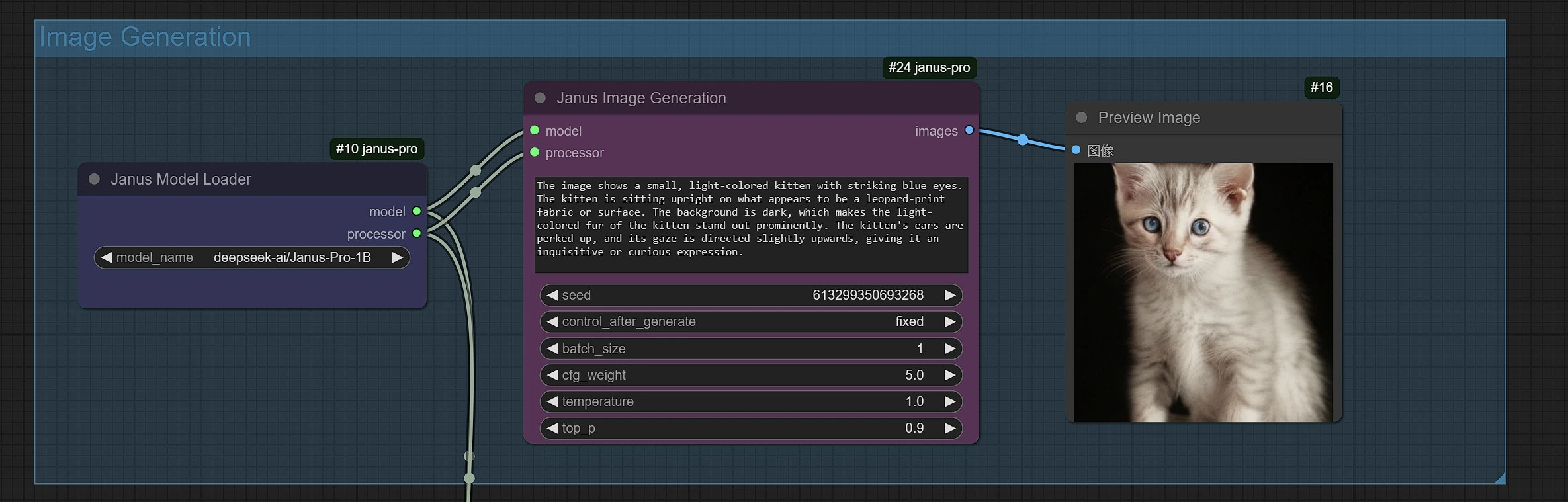
- Janus 图像生成采样器允许您输入提示。
- 您可以使用 Janus-Pro-1B 或 Janus-Pro-7B 模型。
- Janus-Pro 图像生成目前仅限于 1:1 方形(384*384 像素)比例。
首次运行时,Janus-Pro 模型将自动下载到您的云端 runcomfy 机器上。这可能需要 2-5 分钟的排队时间。 模型链接 -
- Janus-Pro-1B - https://huggingface.co/deepseek-ai/Janus-Pro-1B
- Janus-Pro-7B - https://huggingface.co/deepseek-ai/Janus-Pro-7B
模型将下载到:Comfyui/models/Janus-Pro
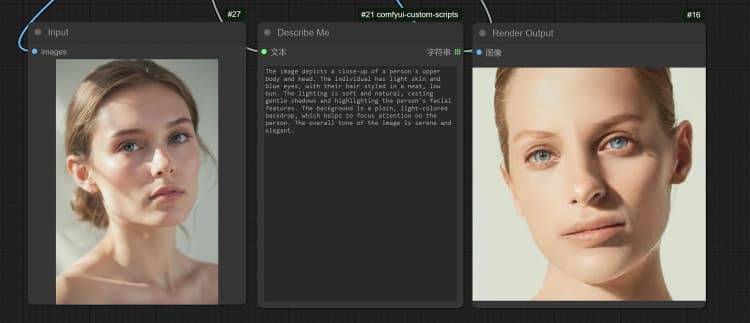
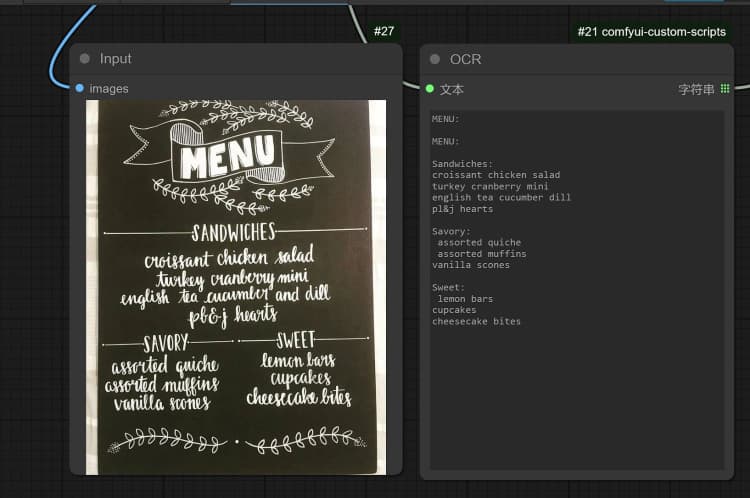
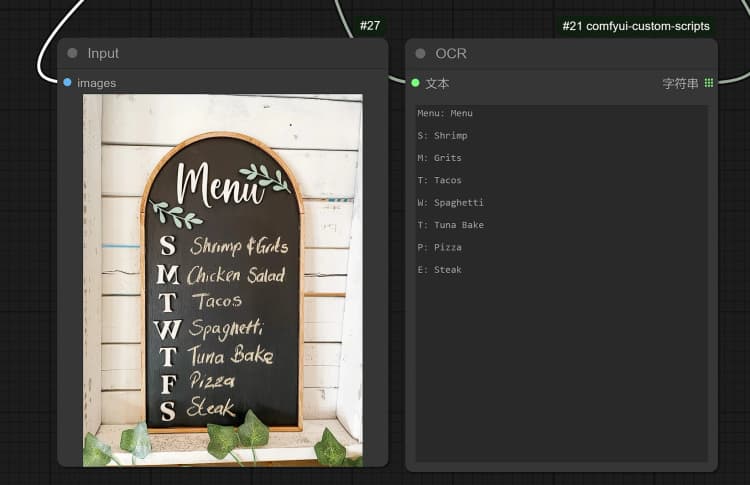
1.3 Janus-Pro 图像描述#
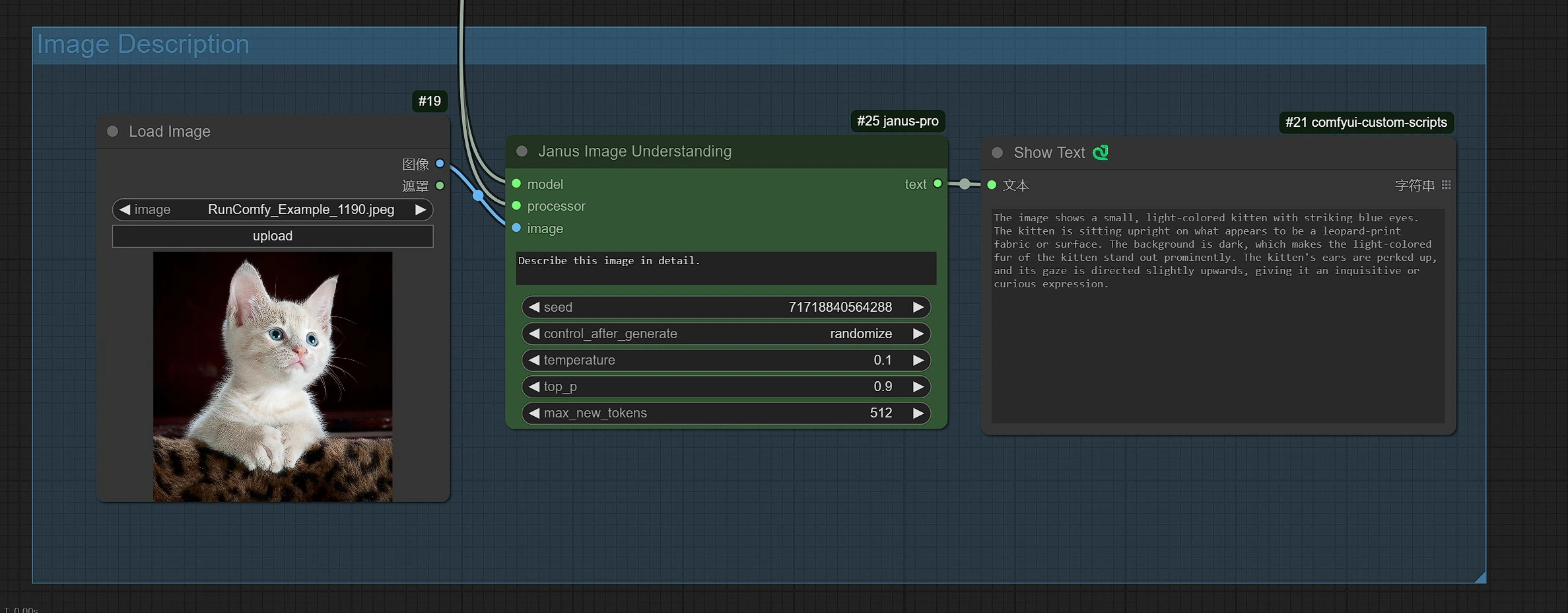
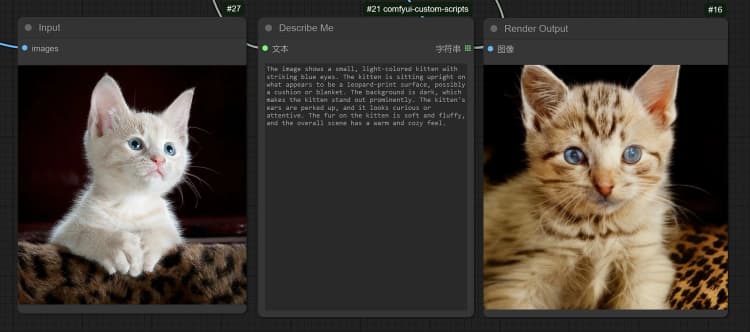
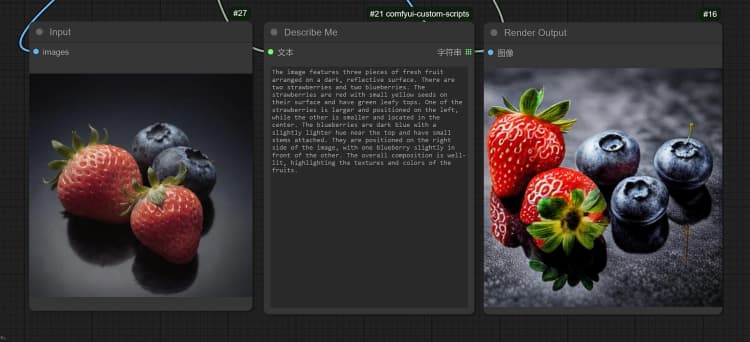
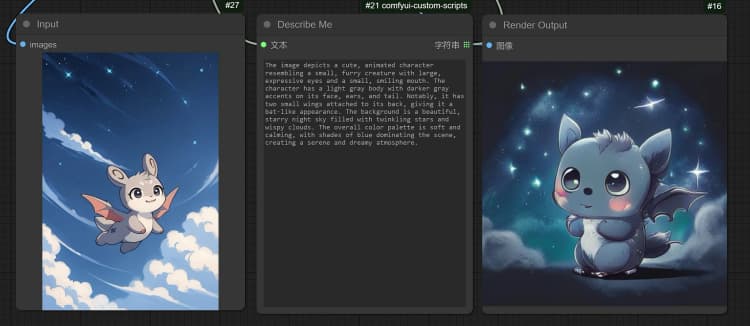
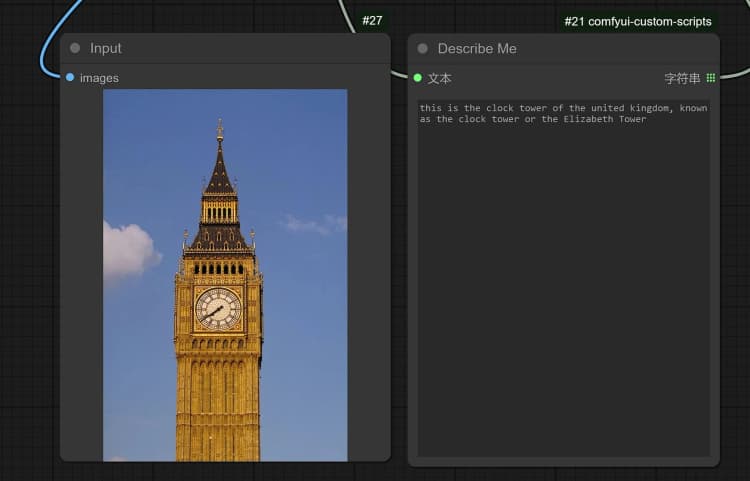
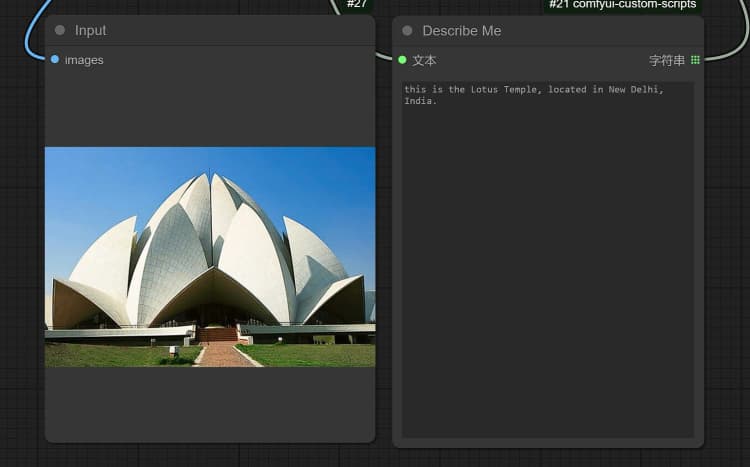
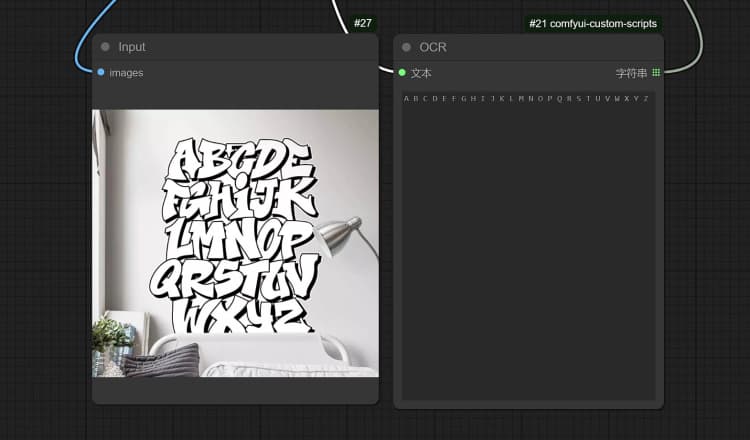
- 点击并上传图像到 Load Image Node 进行 Janus-Pro 处理。
- 您可以使用 Janus-Pro 图像理解节点执行:OCR,字幕,详细描述。只需在节点提供的 Type Box 中输入您的请求。
示例问题: “详细描述此图像,这个位置在哪里,里面写了什么……等。”
Janus-Pro 通过在一个统一框架内无缝集成理解和生成,为多模态 AI 树立了新标准。Janus-Pro 的创新双通道编码增强了灵活性,解决了传统模型阻碍的冲突。通过超越以往的统一架构并与任务特定解决方案媲美,Janus-Pro 为更高效和多才多艺的 AI 系统铺平了道路。作为一个强大且适应性强的框架,Janus-Pro 处于下一代多模态智能的前沿,证明 Janus-Pro 是多模态 AI 的未来。


