






Flux Kontext Zoom Out LoRA | ComfyUI 工作流程#
这个 ComfyUI 工作流程通过扩展画布和自然延续场景,创建任何输入图像的干净放大视图,同时保留主体的位置和外观。它围绕 Flux Kontext 和专门设计的 LoRA 构建,因此您可以在不扭曲面部、纹理或透视的情况下“拉回相机”。如果您需要快速、可靠的方法来放大缩略图、产品照片、肖像或电影静帧的框架,这个 Flux Kontext Zoom Out LoRA 工作流程适合您。
在其核心,图形加载 Flux Kontext UNet,应用 Flux Kontext Zoom Out LoRA,将您的图像编码为参考潜在空间,并通过专为缩放完整性设计的提示来采样更广的构图。结果是无缝扩展,与原始光线、风格和几何匹配。
Comfyui Flux Kontext Zoom Out LoRA 工作流程中的关键模型#
- Flux 1 Kontext UNet。这里使用的扩散骨干是为 ComfyUI 准备的 Kontext 感知的 Flux 1 变体 (
flux1-dev-kontext_fp8_scaled.safetensors)。它捕捉了现实 Outpainting 所需的长距离结构和场景布局。模型包:Comfy-Org/flux1-kontext-dev_ComfyUI。 - Flux Kontext Zoom Out LoRA。一个轻量级适配器,使模型能够在保留可见主体不变的同时,令人信服地扩展边界。仓库:reverentelusarca/flux-kontext-zoom-out-lora。
- Flux 的双文本编码器。图形使用针对 Flux 调整的 CLIP-L 和 T5-XXL 编码器,以高保真度解释提示。文本编码器:comfyanonymous/flux_text_encoders。
- AE VAE。用于编码/解码步骤的快速高质量自动编码器 (
ae.safetensors)。来源:Comfy-Org/Lumina_Image_2.0_Repackaged。
如何使用 Comfyui Flux Kontext Zoom Out LoRA 工作流程#
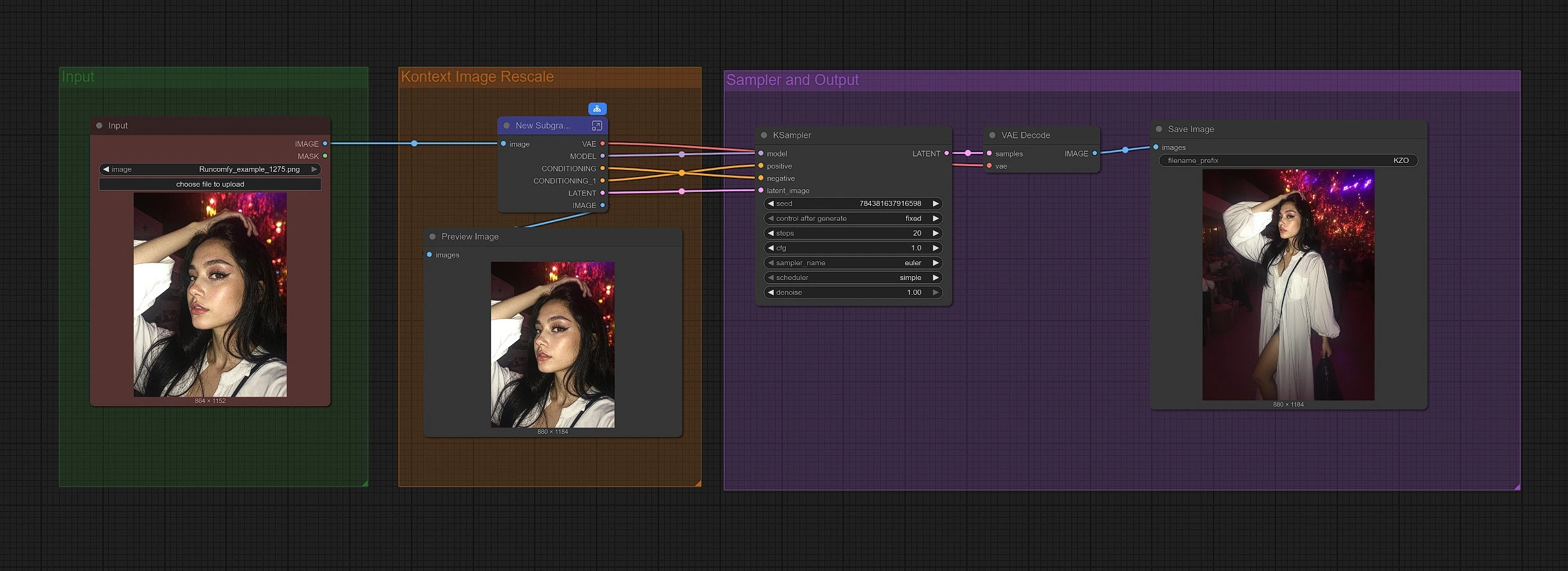
此工作流程分为三个组。首先加载您的图像,然后图形将其重新缩放以适应 Kontext 缩放,最后采样重建更宽的框架并保存结果。
组:输入#
通过 LoadImage (#190) 加载您的源图像。CLIP Text Encode (Positive Prompt) (#6) 中的默认正面提示旨在保留主体并在各个方向上均匀扩展画布。您可以保持该提示不变以获得忠实的缩放效果,或轻微调整以适应您的场景风格。DualCLIPLoader (#38) 预先连接了 CLIP-L 和 T5-XXL,因此文本条件已准备就绪。
组:Kontext 图像重新缩放#
FluxKontextImageScale (#42) 通过以 Kontext 模型可以优雅处理的方式调整大小和填充来准备图像以进行缩放。此阶段步骤有助于模型理解扩展内容的位置以及如何保持透视和光线一致。然后,缩放后的图像由 VAEEncode (#124) 编码,因此采样器从仍然“记得”原始框架的潜在空间中工作。
组:采样器和输出#
模型堆栈由 UNETLoader (#37) 和 LoraLoaderModelOnly (#191) 组装,后者将 Flux Kontext Zoom Out LoRA 应用于基础模型。ReferenceLatent (#177) 使用您的编码图像作为结构锚点,因此边界扩展时主体保持不变。FluxGuidance (#35) 形塑参考影响生成的强度;更高的值增加忠实度,而较低的值允许稍微更具创意的背景填充。KSampler (#31) 执行实际的扩散过程,VAEDecode (#8)、PreviewImage (#173) 和 SaveImage (#136) 显示并保存最终的放大图像。
Comfyui Flux Kontext Zoom Out LoRA 工作流程中的关键节点#
FluxKontextImageScale (#42)#
通过缩放和框定来准备输入,以实现上下文感知的 Outpainting。将其用作更改您想要添加多少画布的唯一位置。如果您需要更多空间,增加缩放量;如果边缘看起来太新,减少它以保留更多原始像素。
LoraLoaderModelOnly (#191)#
加载并应用 kontext/zoomout-fal-v1.safetensors 到 Flux 1 Kontext UNet。如果您的输出看起来偏差过大或不足,请在此调整 LoRA 强度。保持修改适度以保留 Zoom Out LoRA 的预期行为。
ReferenceLatent (#177)#
通过在 VAE 编码原始图像上对采样器进行条件限制来锁定构图和身份。如果您看到主体姿势或比例的细微漂移,请按照提供的方式通过此节点进行条件路由,并避免删除它。将其与中性或最小提示配对可最大限度地提高保真度。
FluxGuidance (#35)#
控制参考和提示对采样器的指导程度。当扩展区域的光线或透视不匹配时,提高指导;如果您想要稍微更具创意的背景填充,则降低它。将其视为在严格保留和有机延续之间的平衡旋钮。
可选附加功能#
- 保持正面提示最小。包含的提示针对这个 Flux Kontext Zoom Out LoRA 进行了调整,通常不需要编辑。
- 如果边界显示出微小的接缝,请在
FluxKontextImageScale中尝试更小的缩放量或稍高的FluxGuidance。 - 对于风格化场景,在提示中添加 1-2 个描述音调或媒介的词,而不是主题形状,以避免改变主体。
- 仅通过更改种子保存迭代变体;这使您可以选择最干净的延续,而不改变构图。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢 reverentelusarca 对 Flux Kontext Zoom Out LoRA 的贡献和维护。有关权威详细信息,请参阅下面链接的原始文档和仓库。
资源#
- reverentelusarca/Flux Kontext Zoom Out LoRA
- Hugging Face: Flux Kontext Zoom Out LoRA
注意:所引用模型、数据集和代码的使用受其作者和维护者提供的各自许可证和条款的约束。

