
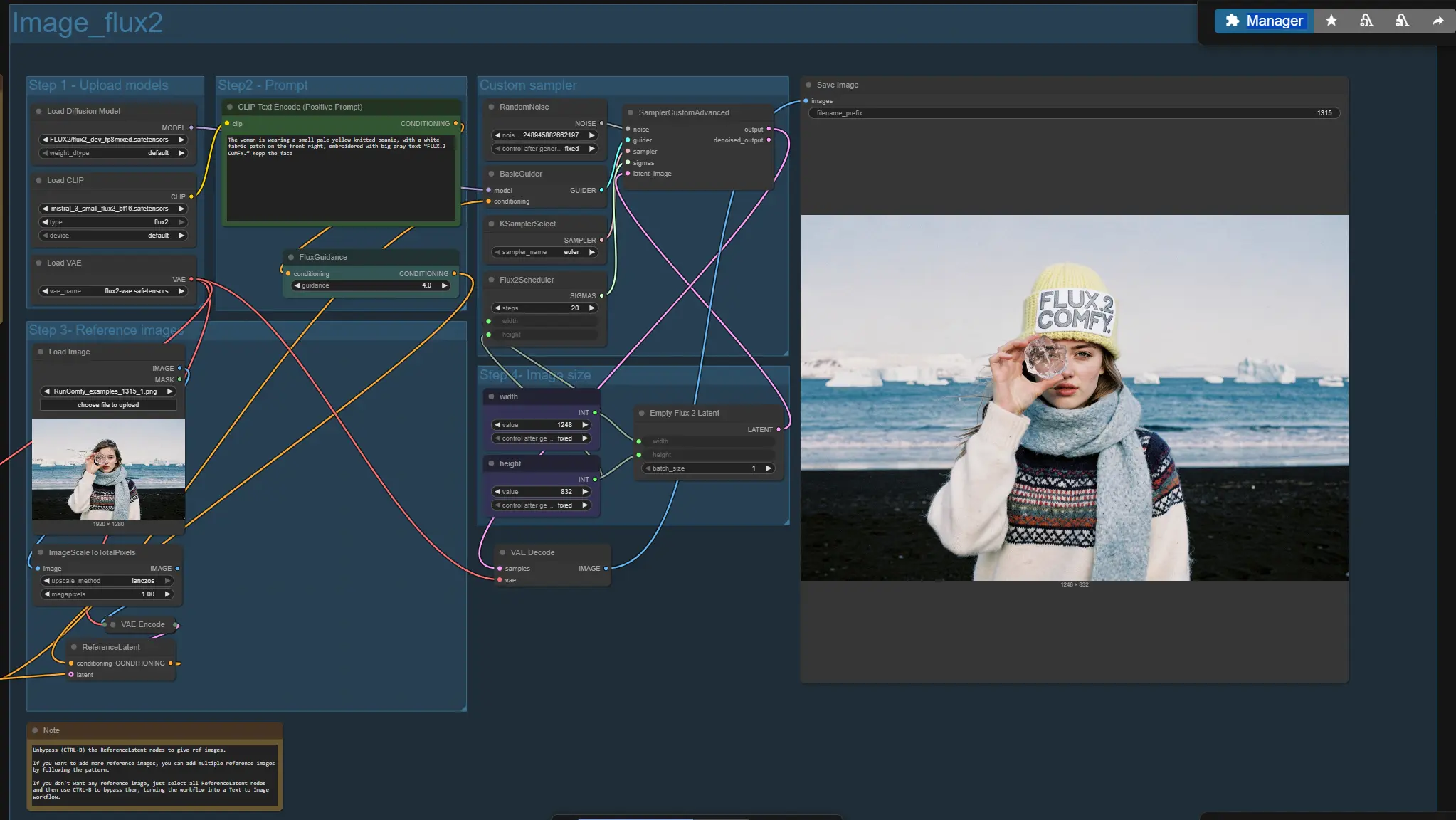







Flux 2 Dev多参考生成和编辑工作流程适用于ComfyUI#
此工作流程将FLUX.2 Dev的强大功能带入ComfyUI,用于高保真文本到图像生成和多参考图像编辑。专为需要照片级细节、一致身份和强提示遵循的创作者量身定制,适用于产品拍摄、角色渲染、广告视觉和概念艺术。您可以运行标准分支或轻量级的FP8分支,保持布局和材料一致,并扩展到多百万像素输出。
Flux 2 Dev融合了精确的提示与参考驱动的控制,因此您可以在变化中保持风格和设计的一致性。图表包含即用的参考插槽、灵活的图像大小调整和自定义采样路径,平衡了质量与速度。适用于迭代构思、场景级一致性和在消费者GPU上的生产级结果。
Comfyui Flux 2 Dev工作流程中的关键模型#
- FLUX.2 Dev扩散模型。用于文本到图像和指导编辑的开放权重视觉生成骨干。来源:black-forest-labs/FLUX.2-dev。
- Mistral 3 Small Flux2文本编码器(bf16和fp8版本)。将您的提示转换为针对Flux 2 Dev优化的令牌嵌入;FP8变体减少轻量级分支的VRAM。示例权重:Comfy-Org/flux2-dev/text_encoders。
- FLUX.2 VAE。从潜在空间压缩和重建图像,具有高感知质量。权重:Comfy-Org/flux2-dev/vae。
如何使用Comfyui Flux 2 Dev工作流程#
图表包含两个并行分支。“Image_flux2”是标准路径;“Image_flux2_fp8”是轻量级变体,交换FP8文本编码器以节省内存。从提示到保存一次使用一个分支。两个分支共享相同的整体逻辑:加载模型、撰写提示、可选添加一个或多个参考图像、选择图像大小、采样和保存。
步骤1 - 上传模型#
工作流程自动加载Flux 2 Dev扩散模型、Flux 2 Dev兼容的文本编码器和Flux 2 VAE。在标准分支中,这些由UNETLoader (#12)、CLIPLoader (#38)和VAELoader (#10)处理。在FP8分支中,它们由UNETLoader (#86)、CLIPLoader (#90)和VAELoader (#70)镜像。通常您无需触碰这些,除非您想交换权重。
步骤2 - 提示#
在CLIP Text Encode (Positive Prompt) (#6)或(#85)中编写您的描述。好的提示命名主题、构图、材料、照明和所需风格(例如,工作室主灯、柔和阴影、光滑塑料、宽光圈)。Flux 2 Dev对清晰的名词和简洁的风格标签反应良好,并且可以在明确说明时保留布局指令和排版。当您希望参考图像占主导地位时,保持提示简单;当您希望更强的创意引导时,变得更具描述性。
步骤3 - 参考图像#
内置参考支持,因此您可以引导身份、风格或设计连续性。将图像拖放到LoadImage节点中,按照大小预处理,编码为潜在变量,并通过链式ReferenceLatent节点融合到条件中。使用显示的模式在FP8分支中添加更多参考(布局可扩展到多个参考)。要完全禁用参考,绕过所有ReferenceLatent节点,您将获得纯文本到图像行为。
自定义采样器#
采样由SamplerCustomAdvanced与可选采样器(KSamplerSelect)和Flux 2调度器进行协调。RandomNoise节点提供确定性种子以实现可重复性。调度器驱动去噪轨迹,而引导器通过您的提示和参考潜在变量为模型加上条件。此路径经过调整,以在保持快速迭代的同时提供清晰的细节和一致的结构。
图像大小#
宽度和高度控制同时馈送调度器和潜在画布,因此模型在预期分辨率下去噪。Flux 2 Dev舒适地定位1-4百万像素;在开发外观时从较小的开始,当您喜欢框架时再放大。保持纵横比与您的主题和参考图像对齐,以保留构图和身份线索。
结果#
采样后,潜在变量由VAE解码,并由SaveImage写出。再次运行相同的种子以在不同拍摄中保持一致性,或更改种子以在保留相同提示和参考的同时探索新变化。
Comfyui Flux 2 Dev工作流程中的关键节点#
CLIP Text Encode (Positive Prompt) (#6, #85)#
使用Flux 2 Dev兼容的文本编码器将您的文本编码为嵌入。强大的名词和清晰的材料和照明术语产生最可靠的指导。如果大量使用参考,请保持提示简洁,以便它们补充而不是抵触参考。
FluxGuidance (#26, #75)#
应用Flux特定的条件强度,平衡提示影响与模型先验和参考。增加指导以更紧密地遵循提示;当参考图像应占主导地位时减少它。小步调整并重新运行几个种子以确认输出的稳定性。
ReferenceLatent (#39, #43, #83, #84)#
将编码的参考潜在变量注入条件流中,以保留身份、风格或布局线索。通过遵循现有模式链节点使用多个参考。绕过单个节点以A/B测试每个参考的贡献,或在文本模式和多参考模式之间切换。
Flux2Scheduler (#48, #67)#
创建针对Flux 2 Dev和您选择的分辨率的sigma计划。更多步骤通常以速度换取细节和稳定性。更改计划时谨慎配对采样器更改,以便您可以将改进归因于一个变量。
KSamplerSelect (#16, #81)#
选择自定义采样器使用的采样器算法。Euler是适用于广泛主题的可靠默认值。仅当您追求特定外观或行为时才切换采样器;在比较时保持其他设置不变。
SamplerCustomAdvanced (#13, #80)#
使用采样器、计划、引导器和潜在画布运行去噪循环。您将重新访问的关键控制杆是steps、sampler和来自噪声节点的seed。在探索场景时,一次仅更改其中一个以了解其效果。
EmptyFlux2LatentImage (#47, #79)#
定义用于在目标宽度和高度下去噪的潜在画布。较大的画布增加细节,但也增加VRAM的使用和每个图像的时间。将画布纵横比匹配您的主题,以获得更自然的构图。
可选额外功能#
- 当VRAM紧张时选择FP8分支,然后移动到标准分支以进行最终渲染。
- 对于身份密集型任务,保持提示简短,并提供干净、光线良好的参考图像。
- 锁定种子以在变化中保持一致性;更改种子以探索替代方案。
- 从较小的分辨率开始以找到框架,然后放大到多百万像素输出以获得最终质量。
- 如果多个参考冲突,请尝试重新排序或暂时绕过一些以查看哪个能提供您想要的外观。
- 保存成功的种子、提示和参考集,作为未来项目的可重用预设。
官方权重和资产的链接:
- Black Forest Labs的FLUX.2 Dev模型:black-forest-labs/FLUX.2-dev
- ComfyUI的拆分权重(文本编码器、VAE、扩散模型):Comfy-Org/flux2-dev
致谢#
此工作流程实施并构建在以下作品和资源之上。我们感谢Comfy Org为FLUX.2 Day-0 Support in ComfyUI: Frontier Visual Intelligence的贡献和维护。有关权威细节,请参阅下面链接的原始文档和存储库。
资源#
- Comfy Org/FLUX.2 Day-0 Support in ComfyUI: Frontier Visual Intelligence
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: black-forest-labs/FLUX.2-dev
- 文档/发布说明:FLUX.2 Day-0 Support in ComfyUI: Frontier Visual Intelligence
注意:引用的模型、数据集和代码的使用需遵循其作者和维护者提供的相应许可证和条款。



