
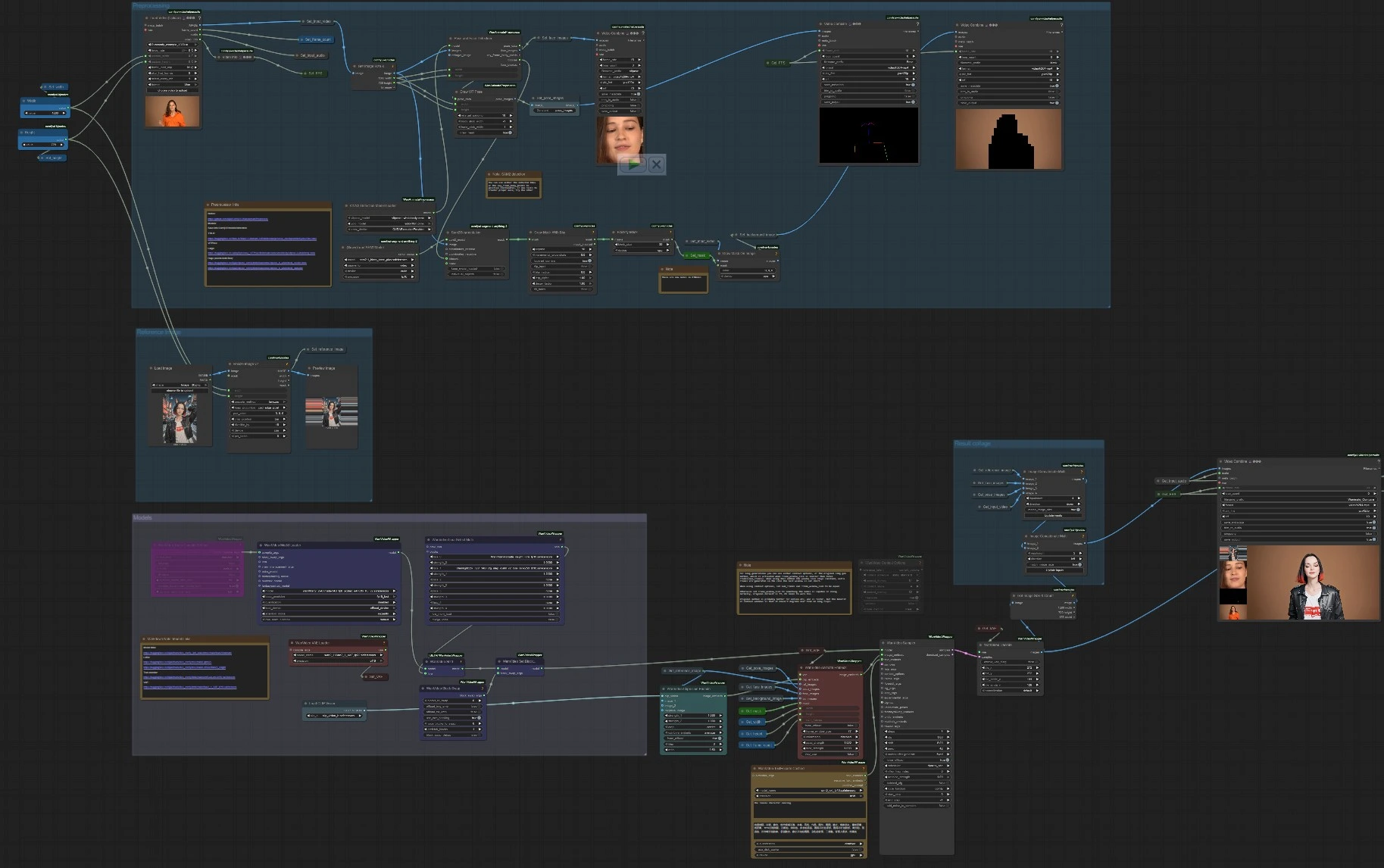
Wan 2.2 Animate V2 рабочий процесс генерации видео, управляемой позами, для ComfyUI#
Wan 2.2 Animate V2 - это рабочий процесс генерации видео, управляемой позами, который превращает одно эталонное изображение и управляющее видео с позами в реалистичную анимацию с сохранением идентичности. Он основывается на первой версии с более высокой точностью, более плавными движениями и лучшей временной согласованностью, следуя за движением всего тела и выражениями из исходного видео.
Этот рабочий процесс ComfyUI предназначен для создателей, которые хотят быстро получать надежные результаты для анимации персонажей, клипов с танцами и историй, основанных на выступлениях. Он сочетает в себе надежную предварительную обработку (поза, лицо и маскировка субъекта) с модельным семейством Wan 2.2 и опциональными LoRAs, чтобы вы могли уверенно настроить стиль, освещение и обработку фона.
Ключевые модели в рабочем процессе ComfyUI Wan 2.2 Animate V2#
- Wan 2.2 Animate 14B. Основная модель диффузии видео, синтезирующая временно согласованные кадры из мультимодальных встраиваний. Веса: Kijai/WanVideo_comfy_fp8_scaled (Wan22Animate).
- Wan 2.1 VAE. Латентный видео декодер/кодер, используемый семейством Wan для реконструкции RGB кадров с минимальными потерями. Веса: Wan2_1_VAE_bf16.safetensors.
- UMT5‑XXL текстовый кодировщик. Кодирует подсказки, которые направляют внешний вид, сцену и кинематографические элементы. Веса: umt5‑xxl‑enc‑bf16.safetensors.
- CLIP Vision (ViT‑H/14). Извлекает особенности, сохраняющие идентичность, из эталонного изображения. Статья: CLIP.
- ViTPose Whole‑Body (ONNX). Оценивает плотные ключевые точки тела, которые управляют переносом движения. Модели: ViTPose‑L WholeBody и ViTPose‑H WholeBody. Статья: ViTPose.
- YOLOv10 детектор. Обеспечивает боксы с людьми для стабилизации обнаружения поз и сегментации. Пример: yolov10m.onnx.
- Segment Anything 2. Высококачественные маски объектов для сохранения фона, композитинга или предварительных просмотров с пересветом. Репозиторий: facebookresearch/segment-anything-2.
- Опциональные LoRAs для стиля и переноса света. Полезны для пересвета и детализации текстур в выходных данных Wan 2.2 Animate V2. Примеры: Lightx2v и Wan22_relight.
Как использовать рабочий процесс ComfyUI Wan 2.2 Animate V2#
На высоком уровне, конвейер извлекает подсказки позы и лица из управляющего видео, кодирует идентичность из одного эталонного изображения, по желанию изолирует субъект с помощью маски SAM 2, а затем синтезирует видео, которое соответствует движению, сохраняя идентичность. Рабочий процесс организован в четыре группы, которые сотрудничают для получения окончательного результата, и два удобных выхода для быстрой оценки качества (предварительные просмотры позы и маски).
Эталонное изображение#
Эта группа загружает ваш портрет или изображение всего тела, изменяет его размер до целевого разрешения и делает его доступным по всему графу. Измененное изображение сохраняется и используется в Get_reference_image и предварительном просмотре, чтобы вы могли быстро оценить кадрирование. Идентификационные особенности кодируются WanVideoClipVisionEncode (CLIP Vision) (#70), и то же изображение подается в WanVideoAnimateEmbeds (#62) как ref_images для более сильного сохранения идентичности. Предоставьте четкое, хорошо освещенное эталонное изображение, которое соответствует типу субъекта в управляющем видео для получения наилучших результатов. Пространство для головы и минимальные перекрытия помогают Wan 2.2 Animate V2 фиксировать структуру лица и одежду.
Предварительная обработка#
Управляющее видео загружается с помощью VHS_LoadVideo (#191), который открывает кадры, аудио, количество кадров и исходную частоту кадров для дальнейшего использования. Подсказки позы и лица извлекаются с помощью OnnxDetectionModelLoader (#178) и PoseAndFaceDetection (#172), затем визуализируются с помощью DrawViTPose (#173), чтобы вы могли подтвердить качество отслеживания. Изоляция субъекта выполняется с помощью Sam2Segmentation (#104), за которой следует GrowMaskWithBlur (#182) и BlockifyMask (#108) для создания чистой, стабильной маски; вспомогательный DrawMaskOnImage (#99) предварительно показывает мат. Группа также стандартизирует ширину, высоту и количество кадров из управляющего видео, чтобы Wan 2.2 Animate V2 мог соответствовать пространственным и временным настройкам без догадок. Быстрые проверки экспортируются как короткие видео: наложение позы и предварительный просмотр маски для нулевой валидации.
Модели#
WanVideoVAELoader (#38) загружает Wan VAE и WanVideoModelLoader (#22) загружает основу Wan 2.2 Animate. Опциональные LoRAs выбираются в WanVideoLoraSelectMulti (#171) и применяются через WanVideoSetLoRAs (#48); WanVideoBlockSwap (#51) может быть включен через WanVideoSetBlockSwap (#50) для архитектурных изменений, влияющих на стиль и точность. Подсказки кодируются WanVideoTextEncodeCached (#65), в то время как WanVideoClipVisionEncode (#70) превращает эталонное изображение в надежные встраивания идентичности. WanVideoAnimateEmbeds (#62) объединяет функции CLIP, эталонное изображение, изображения поз, обрезки лица, опциональные фоновые кадры, маску SAM 2 и выбранное разрешение и количество кадров в одно встраивание анимации. Этот поток управляет WanVideoSampler (#27), который синтезирует латентное видео, согласованное с вашей подсказкой, идентичностью и подсказками движения, и WanVideoDecode (#28) преобразует латентные в RGB кадры.
Коллаж результатов#
Чтобы помочь сравнить выходные данные, рабочий процесс собирает простой бок о бок: сгенерированное видео рядом с вертикальной полосой, показывающей эталонное изображение, обрезки лица, наложение позы и кадр из управляющего видео. ImageConcatMulti (#77, #66) строит визуальный коллаж, затем VHS_VideoCombine (#30) рендерит "Сравнить" mp4. Окончательный чистый выходной файл рендерится VHS_VideoCombine (#189), который также переносит аудио из управляющего для быстрого просмотра. Эти экспорты упрощают оценку того, насколько хорошо Wan 2.2 Animate V2 следовал движению, сохранил идентичность и поддерживал предполагаемый фон.
Ключевые узлы в рабочем процессе ComfyUI Wan 2.2 Animate V2#
VHS_LoadVideo (#191) Загружает управляющее видео и открывает кадры, аудио и метаданные, используемые по всему графу. Держите субъект полностью видимым с минимальным размытием движения для более сильного отслеживания ключевых точек. Если вы хотите более короткие тесты, ограничьте количество загружаемых кадров; держите исходную частоту кадров согласованной вниз по потоку, чтобы избежать рассинхронизации аудио в окончательной компоновке.
PoseAndFaceDetection (#172) Запускает YOLO и ViTPose для создания ключевых точек всего тела и обрезков лица, которые непосредственно управляют переносом движения. Подайте ему изображения из загрузчика и стандартизированную ширину и высоту; опциональный вход retarget_image позволяет адаптировать позы к другому кадрированию, когда это необходимо. Если наложение позы выглядит шумным, рассмотрите более качественную модель ViTPose и убедитесь, что субъект не сильно перекрыт. Ссылка: ComfyUI‑WanAnimatePreprocess.
Sam2Segmentation (#104) Создает маску субъекта, которая может сохранить фон или локализовать пересвет в Wan 2.2 Animate V2. Вы можете использовать обнаруженные ограничивающие боксы из PoseAndFaceDetection или нарисовать быстрые положительные точки, если необходимо, чтобы уточнить мат. Сочетайте с GrowMaskWithBlur для более чистых краев на быстром движении и просмотрите результат с экспортом предварительного просмотра маски. Ссылка: Segment Anything 2.
WanVideoClipVisionEncode (#70) Кодирует эталонное изображение с помощью CLIP Vision для захвата идентификационных подсказок, таких как структура лица, волосы и одежда. Вы можете усреднить несколько эталонных изображений для стабилизации идентичности или использовать негативное изображение для подавления нежелательных черт. Центрированные обрезки с согласованным освещением помогают создать более сильные встраивания.
WanVideoAnimateEmbeds (#62) Объединяет идентификационные особенности, изображения поз, обрезки лица, опциональные фоновые кадры и маску SAM 2 в одно встраивание анимации. Согласуйте width, height и num_frames с вашим управляющим видео для уменьшения артефактов. Если вы видите дрейф фона, предоставьте чистые фоновые кадры и надежную маску; если лицо дрейфует, убедитесь, что обрезки лица присутствуют и хорошо освещены.
WanVideoSampler (#27) Создает фактические латенты видео, направляемые вашей подсказкой, LoRAs и встраиванием анимации. Для длинных клипов выберите между стратегией скользящего окна или контекстными опциями модели; сопоставьте оконное отображение с длиной клипа, чтобы сбалансировать резкость движения и долговременную согласованность. Отрегулируйте планировщик и силу направляющей, чтобы сбалансировать точность, соответствие стилю и плавность движения, и рассмотрите возможность включения блока обмена, если ваш стек LoRA от этого выигрывает.
Опциональные дополнения#
- Начните с чистого управляющего клипа: стабильная камера, простое освещение и минимальное перекрытие дают Wan 2.2 Animate V2 наилучший шанс чисто отслеживать движение.
- Используйте эталон, который соответствует целевому наряду и кадрированию; избегайте экстремальных углов или сильных фильтров, которые конфликтуют с вашей подсказкой или LoRAs.
- Сохраняйте или заменяйте фоны с помощью маски SAM 2; при композитинге держите края достаточно мягкими, чтобы избежать ореолов на быстром движении.
- Держите частоту кадров согласованной от загрузки до экспорта, чтобы поддерживать синхронизацию губ и выравнивание ритма при переносе аудио.
- Для быстрой итерации сначала протестируйте короткий сегмент, затем расширьте диапазон кадров, как только поза, идентичность и освещение будут выглядеть правильно.
Полезные ресурсы, использованные в этом рабочем процессе:
- Узлы предварительной обработки: kijai/ComfyUI‑WanAnimatePreprocess
- Модели ViTPose ONNX: ViTPose‑L, ViTPose‑H модель и данные
- YOLOv10 детектор: yolov10m.onnx
- Веса Wan 2.2 Animate 14B: Wan22Animate
- LoRAs: Lightx2v, Wan22_relight
Признания#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы с благодарностью признаем рабочий процесс Benji’s AI Playground и команду Wan за модель Wan 2.2 Animate V2 за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Команда Wan/Wan 2.2 Animate V2
- Документы / Примечания к выпуску: YouTube @Benji’s AI Playground
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
