
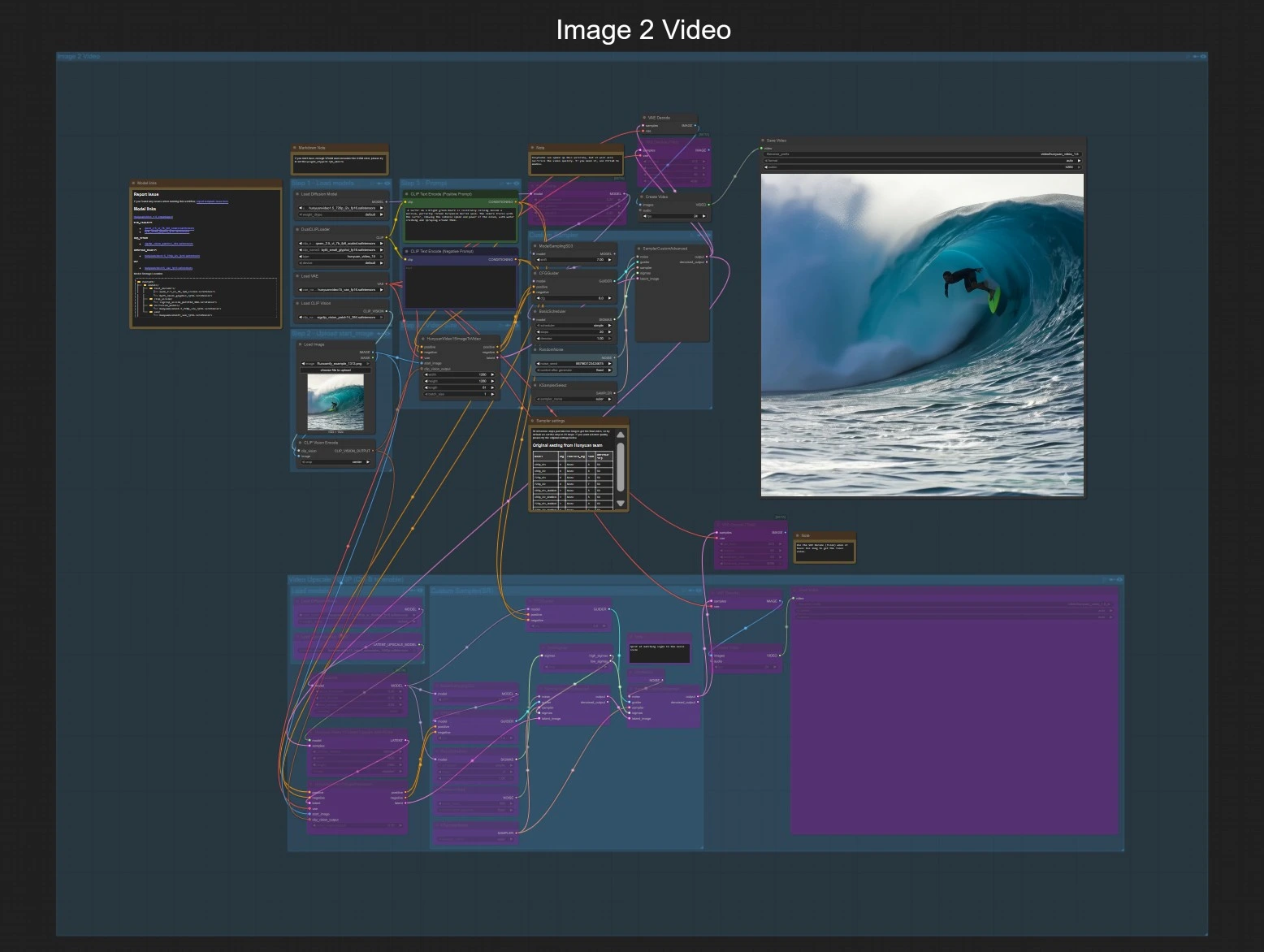
Рабочий процесс Hunyuan Video 1.5 ComfyUI: быстрый переход от текста к видео и изображению к видео с супер разрешением 1080p#
Этот рабочий процесс оборачивает Hunyuan Video 1.5 в ComfyUI для быстрой, последовательной генерации видео на потребительских GPU. Он поддерживает как преобразование текста в видео, так и изображение в видео, а затем при необходимости повышает разрешение до 1080p, используя специальный латентный апскейлер и дистиллированную модель супер-разрешения. В основе Hunyuan Video 1.5 соединяет Diffusion Transformer с 3D причинной VAE и стратегией селективного скользящего плиточного внимания для балансировки качества, точности движения и скорости.
Создатели, продуктовые команды и исследователи могут использовать этот рабочий процесс ComfyUI Hunyuan Video 1.5 для быстрого перехода от подсказок или одного неподвижного изображения, предварительного просмотра в 720p и завершения четким выходом 1080p при необходимости.
Основные модели в рабочем процессе Comfyui Hunyuan Video 1.5#
- HunyuanVideo 1.5 720p Image-to-Video UNet. Создает движение и временную последовательность из начального изображения. Веса предоставлены в перепакетировке Comfy-Org на Hugging Face Comfy-Org/HunyuanVideo_1.5_repackaged.
- HunyuanVideo 1.5 720p Text-to-Video UNet. Генерирует видео непосредственно из текстовых подсказок, используя ту же основную архитектуру, настроенную для рабочих процессов, основанных на подсказках. См. репозиторий перепакетировки выше.
- HunyuanVideo 1.5 1080p Super-Resolution UNet (дистиллированный). Улучшает латенты 720p до более высокого уровня детализации, сохраняя при этом движение и структуру сцены. Включено в ту же перепакетировку на Hugging Face.
- HunyuanVideo 1.5 3D VAE. Кодирует и декодирует латенты видео для эффективной генерации и декодирования плит.
- HunyuanVideo 1.5 Latent Upsampler 1080p. Масштабирует латентные последовательности до 1920×1080 перед доработкой SR для скорости и эффективности памяти.
- Qwen 2.5 VL 7B текстовый энкодер и ByT5 Small текстовый энкодер. Обеспечивают надежное следование инструкциям и токенизацию для различных подсказок, перепакетированных для этого рабочего процесса в наборе Hugging Face. Оригинальная карточка модели ByT5: google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). Извлекает высококачественные визуальные особенности из начального изображения для управления условием изображения на видео: Comfy-Org/sigclip_vision_384.
Как использовать рабочий процесс Comfyui Hunyuan Video 1.5#
Этот график открывает два независимых пути, которые делят одну и ту же стадию экспорта и необязательной доработки 1080p. Выберите либо изображение для видео, либо текст для видео, а затем при необходимости включите группу 1080p для завершения.
Изображение для видео#
Шаг 1 — Загрузите модели Загрузчики загружают Hunyuan Video 1.5 UNet для изображения в видео, 3D VAE, двойные текстовые энкодеры и SigCLIP vision. Это подготавливает рабочий процесс для принятия одного начального изображения и подсказки. Пользовательские действия не требуются, кроме подтверждения наличия моделей.
Шаг 2 — Загрузите начальное изображение Предоставьте чистое, хорошо экспонированное изображение в LoadImage (#80). График кодирует это изображение с помощью CLIPVisionEncode (#79), чтобы Hunyuan Video 1.5 мог закрепить движение и стиль на вашем эталоне. Предпочитайте изображения, которые примерно соответствуют вашему целевому соотношению сторон, чтобы уменьшить обрезку или заполнение.
Шаг 3 — Подсказка Напишите свое описание в CLIP Text Encode (Positive Prompt) (#44). Используйте негативную подсказку CLIP Text Encode (Negative Prompt) (#93), чтобы избежать нежелательных артефактов или стилей. Держите подсказки краткими, но конкретными относительно предмета, движения и поведения камеры.
Шаг 4 — Размер и продолжительность видео HunyuanVideo15ImageToVideo (#78) устанавливает пространственное разрешение и количество кадров для синтеза. Более длинные последовательности требуют больше VRAM и времени, поэтому начните с более коротких и увеличивайте, как только вам понравится движение.
Пользовательская выборка Стек выборки (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125)) управляет силой руководства, шагами, типом выборки и семенем. Увеличьте шаги для более детальной и стабильной работы и используйте фиксированное семя, чтобы воспроизводить результаты при итерации на подсказках.
Предварительный просмотр и сохранение Латентная последовательность декодируется с помощью VAEDecode (#8), оформляется в видео с частотой 24 кадра в секунду с помощью CreateVideo (#101) и записывается с помощью SaveVideo (#102). Это дает вам быстрый предварительный просмотр 720p, готовый к просмотру.
Завершение 1080p (опционально) Переключите группу "Video Upscale 1080P", чтобы включить цепочку завершения. Латентный апскейлер расширяется до 1920×1080, затем дистиллированный супер-разрешение UNet уточняет детали в двух фазах. VAEDecodeTiled и вторая пара CreateVideo/SaveVideo экспортируют результат 1080p.
Текст для видео#
Шаг 1 — Загрузите модели Загрузчики извлекают Hunyuan Video 1.5 720p текст-видео UNet, 3D VAE и двойные текстовые энкодеры. Этот путь не требует начального изображения.
Шаг 3 — Подсказка Введите ваше описание в положительном энкодере CLIP Text Encode (Positive Prompt) (#149) и, при необходимости, добавьте негативную подсказку в CLIP Text Encode (Negative Prompt) (#155). Опишите сцену, предмет, движение и камеру, сохраняя язык конкретным.
Шаг 4 — Размер и продолжительность видео EmptyHunyuanVideo15Latent (#183) выделяет начальный латент с выбранной шириной, высотой и количеством кадров. Используйте это, чтобы установить, как долго и насколько большим должно быть ваше видео.
Пользовательская выборка ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162) и SamplerCustomAdvanced (#166) сотрудничают, чтобы превратить шум в последовательное видео, направляемое вашим текстом. Регулируйте шаги и руководство, чтобы обменять скорость на точность, и фиксируйте семена, чтобы сделать запуски сравнимыми.
Предварительный просмотр и сохранение Декодированные кадры собираются CreateVideo (#168) и сохраняются SaveVideo (#167) для быстрого обзора 720p при 24 кадрах в секунду.
Завершение 1080p (опционально) Включите группу "Video Upscale 1080P", чтобы увеличить латенты до 1080p и уточнить с помощью дистиллированного SR UNet. Двухступенчатая выборка улучшает резкость, сохраняя при этом движение. Плиточный декодер и второй этап сохранения экспортируют финальное видео 1080p.
Ключевые узлы в рабочем процессе Comfyui Hunyuan Video 1.5#
HunyuanVideo15ImageToVideo (#78) Создает видео, кондиционируя на начальном изображении и ваших подсказках. Настройте его разрешение и общее количество кадров, чтобы соответствовать вашей творческой цели. Более высокие разрешения и более длительные клипы увеличивают VRAM и время. Этот узел является центральным для качества изображения в видео, поскольку он объединяет функции CLIP-Vision с текстовым руководством перед выборкой.
EmptyHunyuanVideo15Latent (#183) Инициализирует латентную сетку для текста в видео с шириной, высотой и количеством кадров. Используйте его, чтобы определить длину последовательности заранее, чтобы планировщик и выборщик могли планировать стабильную траекторию денойзинга. Сохраняйте соотношение сторон, соответствующее вашему предполагаемому выходу, чтобы избежать дополнительного заполнения позже.
CFGGuider (#129) Устанавливает силу руководства без классификатора, балансируя следование подсказкам и естественность. Увеличьте руководство, чтобы более строго следовать подсказке; уменьшите его, чтобы уменьшить перенасыщение и мерцание. Используйте умеренные значения во время базовой генерации и уменьшите руководство для уточнения супер-разрешения.
BasicScheduler (#126) Контролирует количество шагов денойзинга и расписание. Больше шагов обычно означает лучшую детализацию и стабильность, но более длительные рендеры. Пара шагов с выборщиком для достижения наилучших результатов; этот рабочий процесс по умолчанию использует быстрый, универсальный выборщик.
SamplerCustomAdvanced (#125) Выполняет цикл денойзинга с выбранным вами выборщиком и руководством. В цепочке завершения 1080p он работает в двух фазах, разделенных SplitSigmas, чтобы сначала установить структуру при более высоком уровне шума, а затем уточнить детали при низком уровне шума. Сохраняйте семена фиксированными при настройке шагов и руководства, чтобы вы могли надежно сравнивать выходы.
HunyuanVideo15LatentUpscaleWithModel (#109) Масштабирует латентную последовательность до 1920×1080, используя специальный апскейлер из перепакетированных весов. Повышение разрешения в латентном пространстве быстрее и более экономично по памяти, чем изменение размера в пространстве пикселей, и оно подготавливает почву для дистиллированной модели SR для добавления мелких деталей. Более крупные цели требуют больше VRAM; сохраняйте 16:9 для наилучшей пропускной способности.
HunyuanVideo15SuperResolution (#113) Уточняет увеличенный латент с помощью 1080p SR дистиллированного UNet из набора Hunyuan Video 1.5, при необходимости принимая подсказки начального изображения и CLIP-Vision для согласованности. Это добавляет четкие текстуры и линии, сохраняя движение. Веса SR доступны в Comfy-Org/HunyuanVideo_1.5_repackaged.
EasyCache (#116) Кэширует промежуточные состояния модели для ускорения предварительных итераций. Включите его, когда вам нужен более быстрый оборот, и отключите для максимального качества на вашем финальном проходе. Это особенно полезно при итерации на подсказках с одинаковым разрешением и продолжительностью.
Дополнительные опции#
- Держите подсказки конкретными. Опишите предмет, глаголы движения и движения камеры. Используйте короткую негативную подсказку, чтобы подавить артефакты, которые вы видите повторно.
- Предпочитайте чистые, высококонтрастные начальные изображения для изображения в видео. Соответствуйте соотношению сторон вашему целевому разрешению, чтобы минимизировать заполнение.
- Для скорости итерации на более коротких продолжительностях и 720p; включайте группу 1080p только для финальных запусков.
- Если VRAM ограничен, включите плиточный декодер VAE и рассмотрите возможность загрузки весов в настройке с меньшей точностью, предложенной загрузчиком модели.
- Фиксируйте семена при настройке шагов, руководства и формулировок, чтобы изменения были измеримы между запусками.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарны Comfy.org за их вклад и поддержку в руководстве по рабочему процессу Hunyuan Video 1.5. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, связанным ниже.
Ресурсы#
- Источник Hunyuan Video 1.5
- Документы / Примечания к выпуску: Hunyuan Video 1.5 Source
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.
