
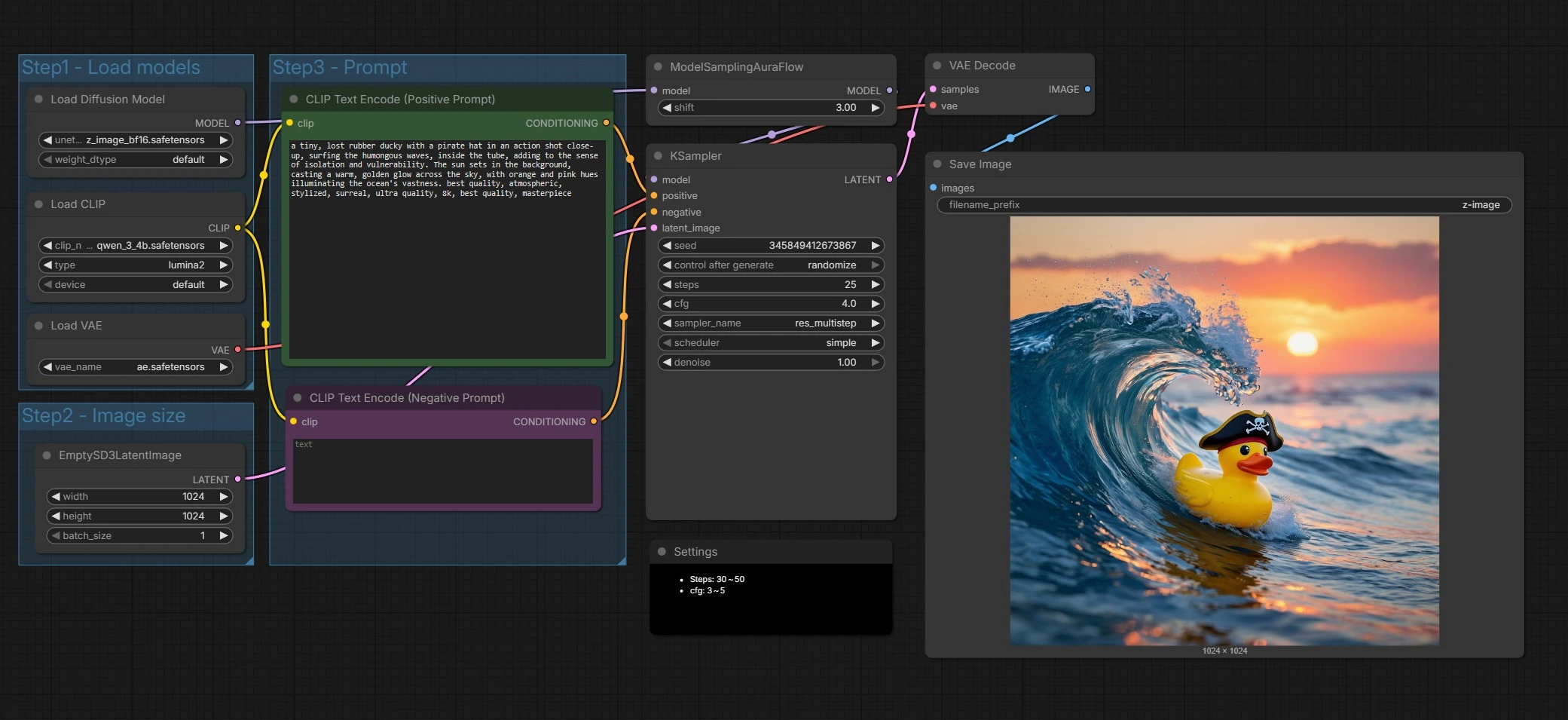
















Fluxo de trabalho de texto para imagem Z-Image para ComfyUI#
Este fluxo de trabalho ComfyUI apresenta o Z-Image, um transformador de difusão de próxima geração projetado para geração de imagens rápidas e de alta fidelidade. Construído em uma arquitetura de fluxo único escalável com cerca de 6 bilhões de parâmetros, o Z-Image equilibra fotorrealismo, forte adesão ao prompt e renderização de texto bilíngue.
Pronto para uso, o gráfico está configurado para o Z-Image Base para maximizar a qualidade enquanto permanece eficiente em GPUs comuns. Também funciona bem com a variante Z-Image Turbo quando a velocidade é importante, e sua estrutura facilita a extensão para o Z-Image Edit para tarefas de imagem para imagem. Se você deseja um gráfico confiável e mínimo que transforma prompts claros em resultados limpos, este fluxo de trabalho Z-Image é um ponto de partida sólido.
Modelos principais no fluxo de trabalho Comfyui Z-Image#
- Difusor Z-Image Base (bf16). Gerador central que remove o ruído dos latentes em imagens com a topologia de fluxo único do Z-Image e controle de prompt. Model page • bf16 weights
- Codificador de texto Qwen 3 4B. Codifica prompts para o Z-Image com forte cobertura bilíngue e tokenização clara para renderização de texto. encoder weights
- Autoencoder VAE Z-Image. Comprime e reconstrói imagens entre o espaço de pixels e o espaço latente do Z-Image. VAE weights
Como usar o fluxo de trabalho Comfyui Z-Image#
Em um nível alto, o gráfico carrega os componentes do Z-Image, prepara uma tela latente, codifica seus prompts positivos e negativos, executa um amostrador ajustado para o Z-Image, depois decodifica e salva o resultado. Você principalmente fornece o prompt e escolhe o tamanho de saída; o resto é configurado para padrões sensatos.
Passo 1 - Carregar modelos#
Este grupo inicializa o Z-Image UNet, o codificador de texto Qwen 3 4B, e o VAE para que todos os componentes estejam alinhados. O UNETLoader (#66) aponta para o Z-Image Base por padrão, que favorece a fidelidade e a margem para edição. O CLIPLoader (#62) traz o codificador baseado em Qwen que lida bem com prompts multilíngues e tokens de texto. O VAELoader (#63) define o autoencoder usado posteriormente para a decodificação. Troque os pesos aqui se quiser experimentar o Z-Image Turbo para rascunhos mais rápidos.
Passo 2 - Tamanho da imagem#
Este grupo configura a tela latente via EmptySD3LatentImage (#68). Escolha a largura e altura que deseja gerar, e mantenha a proporção em mente para a composição. O Z-Image tem um bom desempenho em tamanhos criativos comuns, então escolha dimensões que correspondam aos seus storyboards ou formato de entrega. Tamanhos maiores aumentam o detalhe e o custo computacional.
Passo 3 - Prompt#
Aqui você escreve sua história. O nó CLIP Text Encode (Positive Prompt) (#67) leva sua descrição de cena e diretrizes de estilo para o Z-Image. O CLIP Text Encode (Negative Prompt) (#71) ajuda a evitar artefatos ou elementos indesejados. O Z-Image é ajustado para a renderização de texto bilíngue, então você pode incluir conteúdo de texto em vários idiomas diretamente no prompt quando necessário. Mantenha os prompts específicos e visuais para os resultados mais consistentes.
Amostra e dessaturação#
ModelSamplingAuraFlow (#70) aplica uma política de amostragem alinhada com o design de fluxo único do Z-Image, então KSampler (#69) conduz o processo de dessaturação para transformar o ruído em uma imagem que corresponda aos seus prompts. O amostrador combina seu condicionamento positivo e negativo com a tela latente para refinar iterativamente a estrutura e detalhes. Você pode trocar velocidade por qualidade aqui ajustando as configurações do amostrador conforme descrito abaixo. Esta etapa é onde a adesão ao prompt do Z-Image e a clareza do texto realmente se destacam.
Decodificar e salvar#
VAEDecode (#65) converte o latente final em uma imagem RGB. SaveImage (#9) grava arquivos usando o prefixo definido no nó para que suas saídas do Z-Image sejam fáceis de encontrar e organizar. Isso completa uma passagem completa do prompt para os pixels.
Nós principais no fluxo de trabalho Comfyui Z-Image#
UNETLoader (#66)#
Carrega a espinha dorsal do Z-Image que realiza a dessaturação real. Troque para outra variante do Z-Image aqui ao explorar casos de uso de velocidade ou edição. Se você mudar de variantes, mantenha o codificador e o VAE compatíveis para evitar mudanças de cor ou contraste.
CLIP Text Encode (Positive Prompt) (#67)#
Codifica a descrição principal para o Z-Image. Escreva frases concisas e visuais que especifiquem o assunto, iluminação, câmera, humor e qualquer texto na imagem. Para a renderização de texto, coloque as palavras desejadas entre aspas e mantenha-as curtas para melhor legibilidade.
CLIP Text Encode (Negative Prompt) (#71)#
Define o que evitar para que o Z-Image possa focar nos detalhes corretos. Use-o para suprimir desfoque, membros extras, tipografia bagunçada ou elementos fora de estilo. Mantenha-o breve e tópico para que não sobreconstranja a composição.
EmptySD3LatentImage (#68)#
Cria a tela latente onde o Z-Image irá pintar. Escolha dimensões que se adequem ao uso final e mantenha-as múltiplas de 64 px para uso eficiente de memória. Telas mais largas ou mais altas influenciam a composição e a perspectiva, então ajuste os prompts de acordo.
ModelSamplingAuraFlow (#70)#
Seleciona um predefinido de amostrador que combina com o treinamento do Z-Image e o espaço latente. Raramente você precisa mudar isso a menos que esteja testando amostradores alternativos. Deixe como fornecido para resultados estáveis e sem artefatos.
KSampler (#69)#
Controla a troca entre qualidade e velocidade para o Z-Image. Aumente steps para mais detalhes e estabilidade, diminua para rascunhos mais rápidos. Mantenha cfg moderado para equilibrar a adesão ao prompt com texturas naturais; valores típicos neste gráfico são steps: 30 a 50 e cfg: 3 a 5. Defina uma seed fixa para reprodutibilidade ou randomize-a para explorar variações.
VAEDecode (#65)#
Transforma o latente final do Z-Image em uma imagem RGB. Se você mudar o VAE, mantenha-o compatível com a família do modelo para preservar a precisão da cor e a nitidez.
SaveImage (#9)#
Grava o resultado com um prefixo de nome de arquivo claro para que as saídas do Z-Image sejam fáceis de catalogar. Ajuste o prefixo para separar experimentos, variantes de modelo ou proporções.
Extras opcionais#
- Use o Z-Image Turbo para ideação rápida, depois volte para o Z-Image Base e aumente os
stepspara renderizações finais. - Para prompts bilíngues e texto na imagem, mantenha a redação curta e de alto contraste no prompt para ajudar o Z-Image a renderizar tipografia nítida.
- Bloqueie a
seedao comparar pequenas edições de prompt para que as diferenças reflitam suas alterações em vez de novo ruído. - Se você ver supersaturação ou halos, diminua
cfgligeiramente ou fortaleça o prompt negativo para recuperar o equilíbrio.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos ao Comfy-Org pelo modelo de fluxo de trabalho Z-Image Day-0 ComfyUI para suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Comfy-Org/Suporte Z-Image Day-0 no ComfyUI
- GitHub: Comfy-Org/workflow_templates
- Docs / Notas de Lançamento: Source
Nota: O uso dos modelos, conjuntos de dados e código mencionados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
