
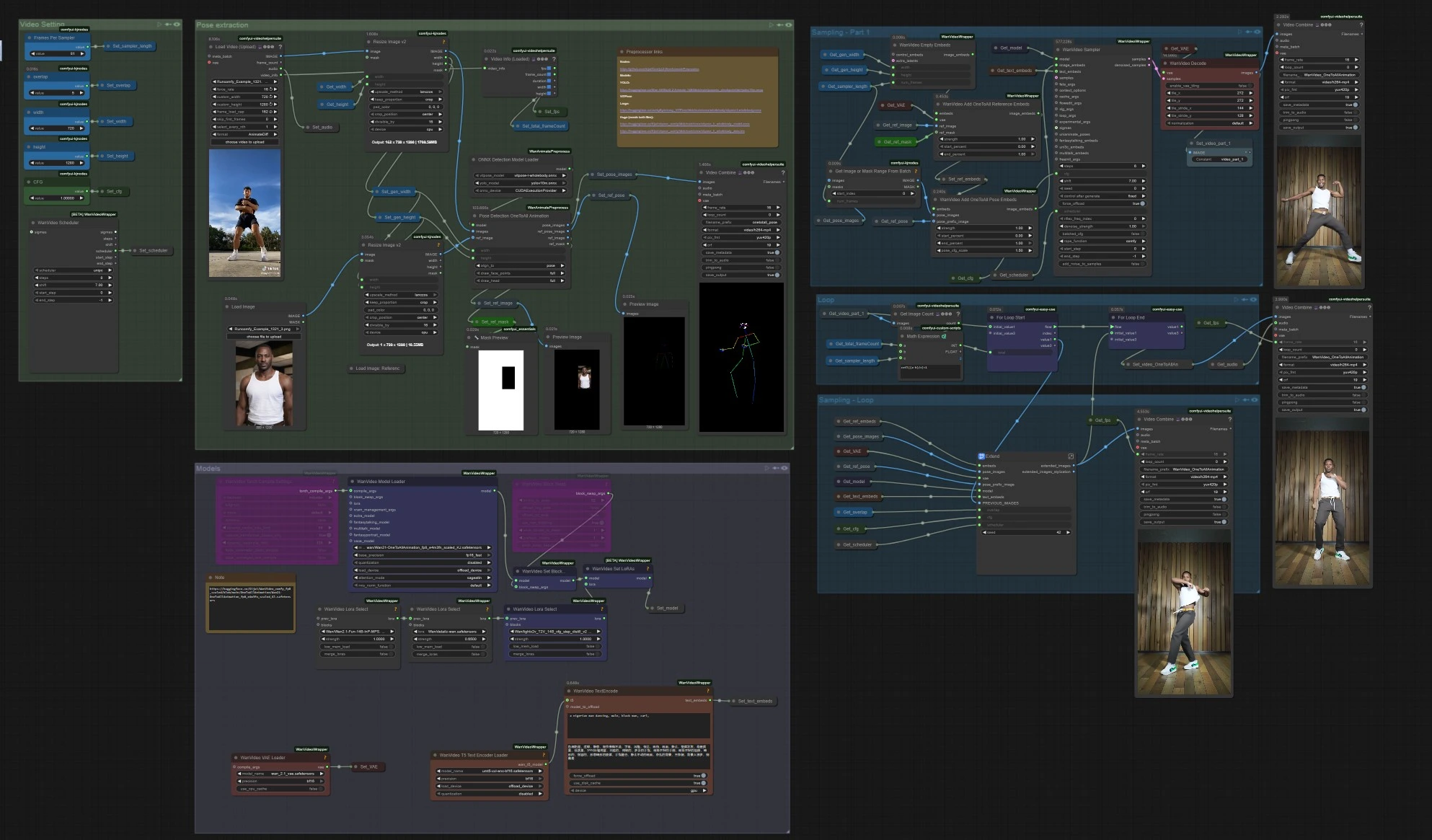
One to All Animation: ComfyUI에서의 장기간 포즈 정렬 캐릭터 비디오#
이 One to All Animation 워크플로우는 짧은 참조 클립을 확장된 고품질 비디오로 변환하면서 모션, 포즈 정렬 및 캐릭터 아이덴티티를 전체 시퀀스에 걸쳐 일관되게 유지합니다. Wan 2.1 비디오 생성과 전체 몸 포즈 가이드, 슬라이딩 윈도우 확장기를 중심으로 구축되어 있으며, 복잡한 움직임을 따르는 단일 룩을 원하는 댄스, 공연 캡처 및 내러티브 샷에 이상적입니다.
안정적이고 포즈 중심의 출력을 필요로 하는 창작자라면, One to All Animation은 명확한 경로를 제공합니다: 소스 비디오에서 포즈를 추출하고, 참조 이미지 및 마스크와 융합하여 첫 번째 청크를 생성한 후, 전체 길이가 커버될 때까지 그 청크를 반복적으로 확장합니다.
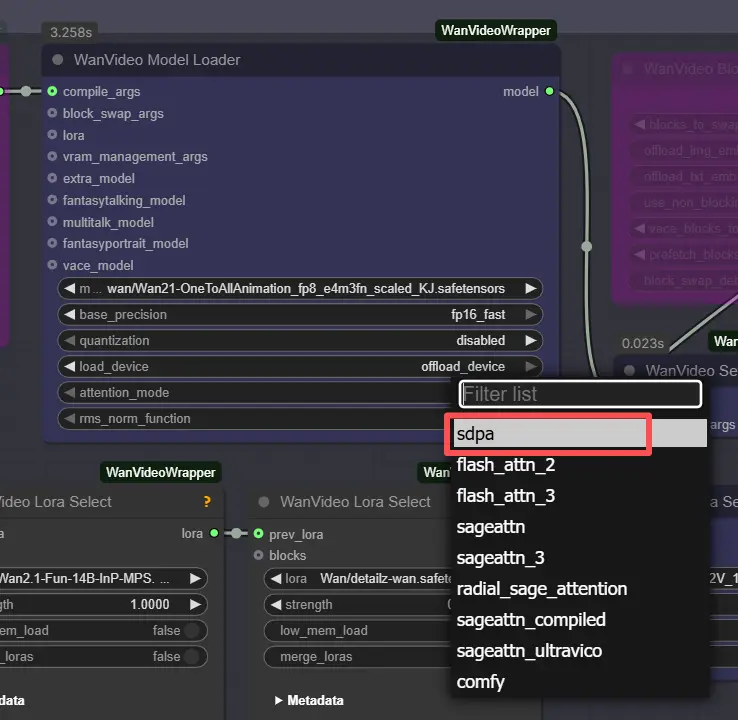
참고: 2XL 또는 3XL 기계에서는 WanVideo Model Loader 노드에서 attention_mode를 "sdpa"로 설정하십시오. 기본 segeattn 백엔드는 고급 GPU에서 호환성 문제를 일으킬 수 있습니다.
Comfyui One to All Animation 워크플로우의 주요 모델#
- Wan 2.1 OneToAllAnimation (비디오 생성). 고품질 모션과 아이덴티티 유지에 사용되는 주요 확산 모델입니다. 예제 가중치: Wan21‑OneToAllAnimation fp8 Kijai로 확장됨. 모델 카드
- UMT5‑XXL 텍스트 인코더. Wan 비디오 생성을 위한 프롬프트를 인코딩합니다. 모델 카드
- ViTPose Whole‑Body (포즈 추정). 포즈 충실도를 유지하기 위해 밀도가 높은 골격 키포인트를 생성합니다. ViTPose 논문 및 전체 몸체 ONNX 가중치를 참조하세요. 논문 • 가중치
- YOLOv10m 탐지기 (사람/영역 탐지). 추정기를 주제에 집중시켜 강력한 포즈 추출 속도를 높입니다. 논문 • 가중치
- 선택적 ViTPose‑H 대안. 어려운 모션을 위한 높은 용량의 전체 몸체 모델입니다. 가중치 및 데이터 파일
- 스타일/컨트롤을 위한 선택적 LoRA 팩. 이 그래프에서 사용된 예제 LoRA에는 Wan2.1‑Fun‑InP‑MPS, detailz‑wan, lightx2v T2V가 포함되며, 재훈련 없이 텍스처, 디테일 또는 인플레이스 컨트롤을 개선합니다.
Comfyui One to All Animation 워크플로우 사용 방법#
전체 흐름
- 워크플로우는 참조 모션 비디오를 읽고, 전체 몸체 포즈를 추출하고, 포즈와 캐릭터 참조를 융합하는 One to All Animation 임베딩을 준비하고, 초기 클립을 생성한 후, 중복을 사용하여 전체 기간을 커버할 때까지 그 클립을 반복적으로 확장합니다. 마지막으로 오디오와 병합하여 완전한 비디오를 내보냅니다.
포즈 추출
VHS_LoadVideo(#454)에서 모션 소스를 로드하세요.ImageResizeKJv2(#131)로 프레임을 생성 비율과 맞게 조정하여 안정적인 샘플링을 합니다.OnnxDetectionModelLoader(#128)는 YOLOv10m 및 ViTPose 전체 몸체를 로드합니다;PoseDetectionOneToAllAnimation(#141)에서 프레임당 포즈 맵, 참조 포즈 이미지 및 깨끗한 참조 마스크를 출력합니다.PreviewImage(#145)를 사용하여 포즈가 주제를 추적하는지 빠르게 확인하세요. 명확하고 고대비의 영상과 최소한의 모션 블러는 One to All Animation 결과에 가장 좋은 결과를 제공합니다.
모델
WanVideoModelLoader(#22)는 Wan 2.1 OneToAllAnimation 가중치를 로드합니다;WanVideoVAELoader(#38)는 연결된 VAE를 제공합니다. 원하는 경우,WanVideoLoraSelect(#452, #451, #56)를 통해 스타일/컨트롤 LoRA를 쌓고,WanVideoSetLoRAs(#80)를 통해 적용하세요.- 텍스트 프롬프트는
WanVideoTextEncode(#16)에 의해 인코딩됩니다. 간결하고 아이덴티티 중심의 긍정적 프롬프트와 강력한 정리 부정 프롬프트를 작성하여 캐릭터를 모형에 유지하세요.
비디오 설정
- 너비와 높이는 "비디오 설정" 그룹에서 설정되며, 포즈 추출 및 생성으로 전달되어 모든 것이 정렬 상태를 유지합니다.
참고: ⚠️ 해상도 제한 : 이 워크플로우는 720×1280 (720p)로 고정되어 있습니다. 워크플로우를 수동으로 재구성하지 않으면 다른 해상도를 사용하는 경우 차원 불일치 오류가 발생합니다.
WanVideoScheduler(#231) 및CFG제어는 노이즈 스케줄 및 프롬프트 강도를 선택합니다. 높은 CFG는 프롬프트에 더 잘 맞추고, 낮은 값은 포즈를 더 느슨하게 추적하지만 아티팩트를 줄일 수 있습니다.VHS_VideoInfoLoaded(#440)는 소스 클립의 fps 및 프레임 수를 읽으며, 루프는 필요한 One to All Animation 윈도우 수를 결정하는 데 사용합니다.
샘플링 – Part 1
WanVideoEmptyEmbeds(#99)는 대상 크기에 대한 컨디셔닝 컨테이너를 만듭니다.WanVideoAddOneToAllReferenceEmbeds(#105)는 참조 이미지와 그ref_mask를 주입하여 아이덴티티를 고정하고 배경이나 의상과 같은 영역을 유지하거나 무시합니다.WanVideoAddOneToAllPoseEmbeds(#98)는 추출된pose_images및pose_prefix_image를 연결하여 첫 번째 생성된 청크가 첫 번째 프레임부터 소스 모션을 따르도록 합니다.WanVideoSampler(#27)는 초기 잠재 클립을 생성하고,WanVideoDecode(#28)에 의해 디코딩되며, 선택적으로VHS_VideoCombine(#139)으로 미리보거나 저장할 수 있습니다. 이것이 확장될 시드 세그먼트입니다.
루프
VHS_GetImageCount(#327) 및MathExpression|pysssss(#332)는 총 프레임 수 및 각 패스 길이에 따라 필요한 확장 패스 수를 계산합니다.easy forLoopStart(#329)는 초기 클립을 시작 컨텍스트로 사용하여 확장 패스를 시작합니다.
샘플링 – 루프
Extend(#263)는 장기간 One to All Animation의 핵심입니다. 이전 잠재 변수를 재사용하여 장면과 캐릭터를 창을 가로질러 일관되게 유지하며,WanVideoAddOneToAllExtendEmbeds(서브그래프 내)를 사용하여 조건을 재계산하고, 다음 창을 샘플링하고 디코딩합니다.ImageBatchExtendWithOverlap(내부Extend)는 각 새 창을overlap영역을 사용하여 누적된 비디오에 블렌딩하여 경계를 부드럽게 하고 시간적 솔기를 줄입니다.easy forLoopEnd(#334)는 각 확장된 블록을 추가합니다. 결과는Set_video_OneToAllAnimation(#386)를 통해 내보내기 위해 저장됩니다.
내보내기
VHS_VideoCombine(#344)는 최종 비디오를 작성하여 소스 fps 및VHS_LoadVideo에서 선택적 오디오를 사용합니다. 무음 결과를 선호하는 경우, 여기서 오디오 입력을 생략하거나 음소거하세요.
Comfyui One to All Animation 워크플로우의 주요 노드#
PoseDetectionOneToAllAnimation (#141)
- 주제를 감지하고 포즈 가이드를 구동하는 전체 몸체 키포인트를 추정합니다. YOLOv10 및 ViTPose에 의해 지원되며 빠른 모션과 부분적인 가림에 강력합니다. 주제가 드리프트하거나 다중 인물 장면이 탐지기를 혼란스럽게 만드는 경우, 입력을 자르거나 위에 링크된 높은 용량의 ViTPose‑H 가중치로 전환하세요.
WanVideoAddOneToAllReferenceEmbeds (#105)
- 참조 이미지와
ref_mask를 컨디셔닝에 융합하여 아이덴티티, 의상 또는 보호된 영역이 프레임 전반에 걸쳐 안정적으로 유지됩니다. 타이트한 마스크는 얼굴과 머리카락을 보존하고, 넓은 마스크는 배경을 고정할 수 있습니다. 룩을 변경할 때, 동일한 모션을 유지하면서 참조를 교체하세요.
WanVideoAddOneToAllPoseEmbeds (#98)
- 포즈 맵과 접두사 포즈를 One to All Animation 임베딩에 바인딩합니다. 더 엄격한 안무를 위해 포즈 영향을 증가시키고, 더 자유로운 해석을 위해 약간 줄이세요. LoRA와 결합하여 일관된 텍스처를 유지하면서도 움직임을 일치시킵니다.
WanVideoSampler (#27)
- 임베딩과 텍스트를 초기 잠재 클립으로 변환하는 주요 비디오 샘플러입니다.
cfg는 프롬프트 순응도를 제어하고,scheduler는 품질, 속도 및 안정성을 거래합니다. 깜박임을 피하기 위해 여기와 루프에서 동일한 샘플러 패밀리를 사용하세요.
Extend (#263)
- 중첩 확장을 수행하는 컴팩트한 서브그래프입니다.
overlap설정이 주요 다이얼입니다: 더 많은 중첩은 추가 계산 비용으로 전환을 더 부드럽게 블렌딩합니다; 더 적은 중첩은 더 빠르지만 솔기를 드러낼 수 있습니다. 이 노드는 또한 이전 잠재 변수를 재사용하여 창을 가로질러 장면과 캐릭터를 일관되게 유지합니다.
VHS_VideoCombine (#344)
- 최종 멀티플렉싱 및 저장. 소스에서 감지된 fps로
frame_rate를 설정하여 모션 타이밍을 소스에 충실하게 유지합니다. 포스트에서 자르거나 루프할 수 있지만, 원래의 리듬으로 내보내면 공연의 느낌을 유지합니다.
선택적 추가 기능#
- 전처리기 설치 노트. 포즈 추출 노드는 커뮤니티 애드온에서 제공됩니다. 설정 및 ONNX 배치를 위해 저장소를 참조하세요. ComfyUI‑WanAnimatePreprocess
- 어려운 모션에 ViTPose‑H를 선호합니다. 손/발이 빠르게 움직이거나 부분적으로 가려질 때 ViTPose‑H로 전환하세요; 위에 링크된 페이지에서 모델과 데이터 파일을 다운로드하세요.
- 긴 실행을 위한 조정. VRAM 제한에 걸리면, 패스당 윈도우 길이를 줄이거나 LoRA 스택을 단순화하세요. 그런 다음 중첩을 약간 올려 전환을 깨끗하게 유지할 수 있습니다.
- 강력한 아이덴티티 유지. 고품질의 정면 참조를 사용하고, 얼굴, 머리카락 또는 의상을 보호하기 위해 정밀한
ref_mask를 그리세요. 이는 긴 One to All Animation 시퀀스에 필수적입니다. - 깨끗한 영상이 도움이 됩니다. 높은 셔터 속도, 일관된 조명 및 명확한 전경 피사체는 포즈 추적을 크게 개선하고 One to All Animation 출력에서 깜박임을 줄입니다.
- 비디오 유틸리티. 내보내기 및 도우미 노드는 Video Helper Suite에서 제공됩니다. 코덱 또는 미리보기에 대한 추가 제어를 원한다면 프로젝트의 문서를 확인하세요. Video Helper Suite
감사의 말#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. One to All Animation 워크플로우 튜토리얼에 대해 Innovate Futures @ Benji와 One‑to‑All Animation 프로젝트에 대해 ssj9596에 감사드립니다. 권위 있는 세부 사항은 아래 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Innovate Futures @ Benji/One to All Animation 소스
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- 문서 / 릴리즈 노트: Patreon post
참고: 참조된 모델, 데이터 세트 및 코드는 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건에 따라 사용해야 합니다.


