
LTX-2 ControlNet: 구조 안내, 오디오 동기화 비디오 생성 in ComfyUI#
LTX-2 ControlNet은 ComfyUI-LTXVideo 확장을 위한 제어 기반 ComfyUI 워크플로우로, 깊이, 캐니 엣지, 자세 안내를 통해 LTX-2 비디오 생성을 조종할 수 있으며, 오디오와 비주얼을 동기화 상태로 유지합니다. 통합된 오디오-비주얼 잠재 공간에서 실행되므로, 말하기, 폴리, 움직임이 함께 생성되어 첫 프레임부터 마지막 프레임까지 정렬된 상태로 유지됩니다.
텍스트-비디오, 이미지-비디오, 비디오-비디오에 맞춰 설계된 이 워크플로우는 IC LoRA 기반 ControlNet 조건화를 추가하여 정확한 레이아웃과 움직임 제어, 장면 연속성을 위한 첫 프레임 초기화, 날카로운 결과를 위한 잠재 업스케일링을 통한 이중 단계 파이프라인을 제공합니다. LTX-2 ControlNet은 완전 개방형, 빠른 반복 가능, 제작 지향적이며, 반복 가능한 고품질 출력을 필요로 하는 창작자를 위해 설계되었습니다.
Comfyui LTX-2 ControlNet 워크플로우의 주요 모델#
- LTX-2 19B (dev FP8 및 distilled). 단일 잠재 공간에서 비디오와 오디오를 샘플링하는 데 사용되는 코어 오디오-비주얼 생성 모델. Model family
- Gemma 3 12B IT 텍스트 인코더. LTX-2에서 사용하는 패키지 인코더를 통해 프롬프트와 네거티브에 대한 강력한 언어 이해를 제공합니다. Encoder file
- LTX-2 Spatial Upscaler x2. 2단계에서 공간 세부 사항을 정제하는 데 사용되는 잠재 업스케일링 모델. Upscaler
- LTX-2 Audio VAE. 생성된 소리를 프레임과 정렬 상태로 유지하는 특화된 오디오 디코더-인코더. LTX-2 체크포인트와 함께 포함. Checkpoints
- IC LoRA 제어 가족 for LTX-2. ControlNet 스타일의 조건화 추가:
- Depth control LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Canny control LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- Pose control LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- Distilled LoRA for quality/efficiency trade-offs: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1. 깊이 제어 경로에서 사용되는 깊이 추정기. Model
- SD VAE FT MSE (Stability AI). 깊이 사전 계산 및 타일 디코딩에 사용되는 이미지 VAE. VAE
- ComfyUI-LTXVideo 확장. LTX-2 샘플러, AV 잠재, 오디오 VAE, 및 전체적으로 사용되는 안내 노드를 제공합니다. Repository
Comfyui LTX-2 ControlNet 워크플로우 사용법#
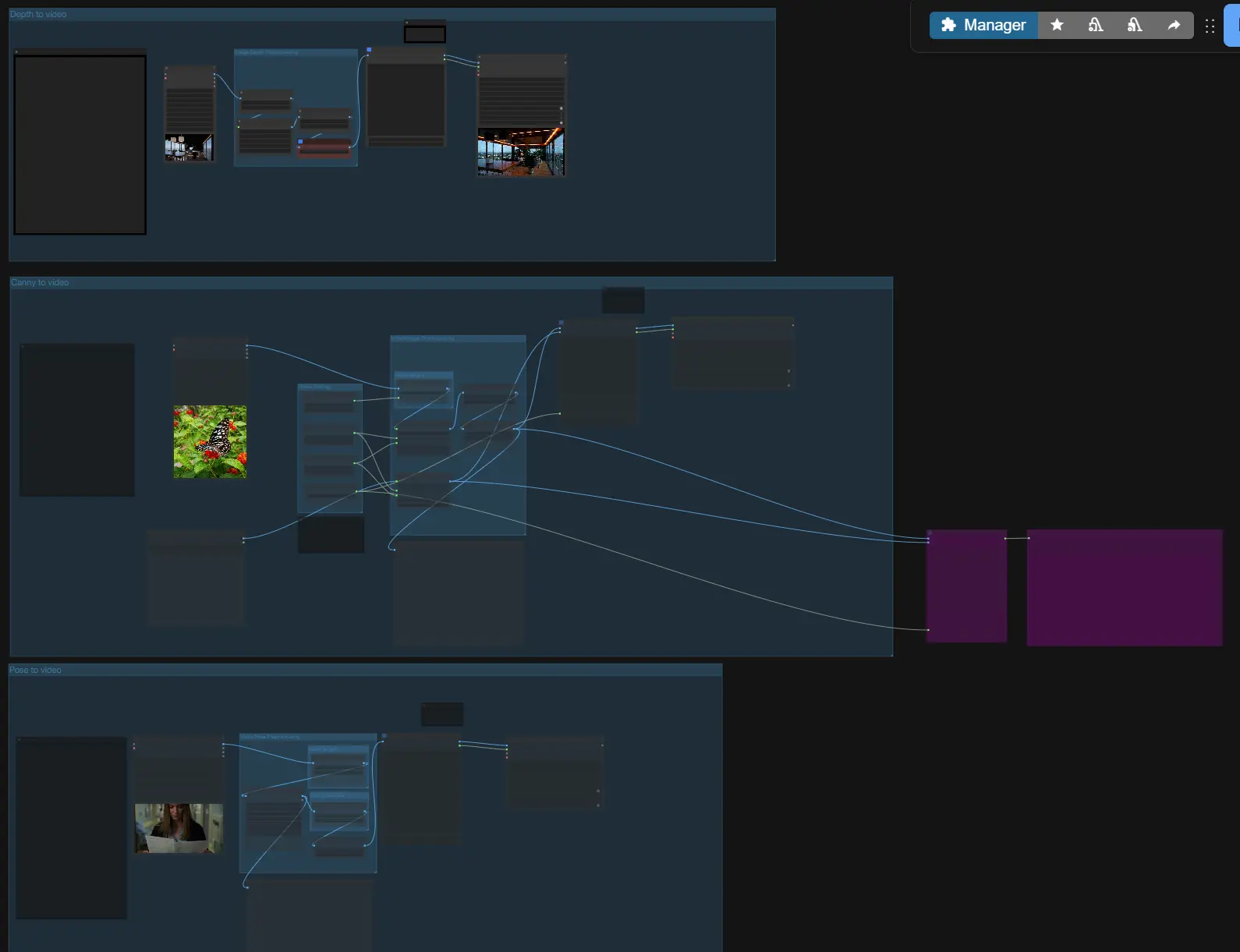
상위 수준에서 LTX-2 ControlNet은 프롬프트와 선택적 참조를 가져와 ControlNet 스타일의 안내와 함께 오디오-비주얼 잠재를 구축하고 첫 번째 패스를 샘플링한 후 선명한 비디오와 동기화된 오디오를 위해 잠재를 업스케일합니다. 세 가지 안내 경로(깊이, 캐니, 자세) 중 하나를 선택하거나 독립적으로 사용한 후, 길이와 크기를 설정하고 내보내기 전에 확인하십시오.
- 이미지/비디오 전처리
- 이미지-비디오 또는 비디오-비디오를 수행 중이라면 로더를 사용하여 참조 미디어를 가져오세요.
VHS_LoadVideo(#196, #197, #198)는 분석을 위해 프레임을 분할하고,LoadImage(#189)는 정지 이미지를 처리합니다. 그룹은 다운스트림 가이드가 일관된 프레임 크기를 볼 수 있도록 편리한 스케일링을 제공합니다. - "첫 프레임" 이미지는 장면 초기화를 위해 앞으로 전달될 수 있으며, 생성 그룹에서 나중에 활성화할 수 있습니다.
- 이미지-비디오 또는 비디오-비디오를 수행 중이라면 로더를 사용하여 참조 미디어를 가져오세요.
- 이미지 깊이 전처리
- 깊이 안내를 위해 "Image to Depth Map (Lotus)" 서브그래프는 입력을 Lotus Depth를 사용하여 정규화된 깊이 맵으로 변환합니다. 이는 LTX-2가 따를 수 있는 단일 프레임 또는 다중 프레임 깊이 표현을 준비합니다.
- 경로에는 선택적 크기 조정 및 강도 제어가 포함되어 있어 가이드가 작은 아티팩트에 과적합되지 않고 넓은 구조를 인코딩할 수 있습니다.
- 비디오 포즈 전처리
- 자세 안내를 위해
DWPreprocessor(#158)는 입력 비디오에서 전체 몸체 키포인트를 감지하고 안정적인 조건화를 위해 크기를 조정합니다. 이는 골격과 팔다리 방향을 강조하는 깨끗한 포즈 이미지 시퀀스를 생성합니다. - 미리보기 노드를 통해 생성 전에 감지 및 종횡비가 올바르게 보이는지 빠르게 확인할 수 있습니다.
- 자세 안내를 위해
- 캐니에서 비디오로
- 이 제어 경로는
Canny(#169)을 사용하여 윤곽선을 추출한 다음 제어 이미지 시퀀스와 함께 AV 잠재를 구축합니다. 참조에서 실루엣, 주요 윤곽선, 또는 타이포그래피 윤곽을 보존하고 싶을 때 사용하십시오. - 첫 프레임 이미지 입력이 일관된 초기화를 위해 제공되며, 특정 스틸과 일치하는 개시 프레임을 원할 때만 활성화하십시오.
- 이 제어 경로는
- 깊이에서 비디오로
- 이 경로는 제어 이미지로 Lotus 깊이 맵을 사용합니다. 깊이 제어는 카메라 기하학, 대규모 레이아웃, 피사체 거리 강제를 이상적으로 수행하며, 생성기가 텍스처와 조명을 선택할 수 있도록 합니다.
- 초기 구성을 잠그기 위해 첫 프레임을 제공할 수 있으며, 깊이 단서를 통해 안내되는 움직임을 따라가게 합니다.
- 자세에서 비디오로
- 자세 경로는 전처리기에서 렌더링된 키포인트를 사용하여 신체 방향 및 움직임 타이밍을 조종합니다. 캐릭터 블로킹, 손 들어올리기 타이밍, 워크 사이클에 특히 효과적입니다.
- 다른 모드와 마찬가지로, 연속성을 위해 선택적 첫 프레임 조건화와 프롬프트 타이밍을 결합할 수 있습니다.
- 비디오 설정 및 길이
- "비디오 설정" 및 "비디오 길이" 그룹에서 작업할 너비, 높이, 프레임 수를 설정하십시오. 워크플로우는 LTX-2의 잠재 그리드 및 스트라이드에 대해 호환 가능한 가장 가까운 크기로 자동 조정하여 안전하게 반복할 수 있도록 합니다.
- 노드 간의 대상 프레임 속도를 일관되게 유지하십시오; 조건화 노드와 최종 믹스는 매끄러운 오디오-비주얼 동기화를 위해 이를 존중합니다.
- 생성, 업스케일링, 내보내기
- 샘플링 중에
LTXVAddGuide는 선택한 제어 이미지와 긍정/부정 조건화를 통합하며,SamplerCustomAdvanced는 비디오 및 오디오 잠재에 대한LTXVScheduler에서 스케줄을 실행합니다. 선택적 첫 프레임은 활성화된 경우LTXVImgToVideoInplace로 주입됩니다. - 두 번째 단계는
LTXVLatentUpsampler로 x2 잠재 업스케일러를 사용하여 세부 사항을 정제합니다. 최종 디코드는 프레임을 위한 타일된VAEDecodeTiled와 오디오를 위한LTXVAudioVAEDecode로 발생하며, 선택된 브랜치에 따라VHS_VideoCombine또는CreateVideo로 비디오를 작성합니다.
- 샘플링 중에
Comfyui LTX-2 ControlNet 워크플로우의 주요 노드#
LTXVAddGuide(#132)- 텍스트 조건화 및 IC LoRA 제어를 AV 잠재에 병합하여 LTX-2 ControlNet 안내의 핵심 역할을 합니다. 경로에 맞는 제어 LoRA를 선택하고, 사용 가능한 경우 모델이 가이드를 얼마나 엄격히 따르는지를 조정하는
image_strength만 조정하십시오. 참조 구현 및 노드 동작은 LTXVideo 확장에서 제공됩니다. Docs/Code
- 텍스트 조건화 및 IC LoRA 제어를 AV 잠재에 병합하여 LTX-2 ControlNet 안내의 핵심 역할을 합니다. 경로에 맞는 제어 LoRA를 선택하고, 사용 가능한 경우 모델이 가이드를 얼마나 엄격히 따르는지를 조정하는
LTXVImgToVideoInplace(#149, #155)- 일관된 장면 초기화를 위해 AV 잠재에 첫 프레임 이미지를 주입합니다. 첫 프레임에 대한 충실함과 진화의 자유를 균형 있게 유지하려면
strength를 사용하십시오; 더 많은 움직임을 위해 낮게, 더 엄격한 앵커를 위해 높게 유지하십시오. 순전히 텍스트 또는 제어 기반의 시작을 원할 때는 바이패스하십시오. Docs/Code
- 일관된 장면 초기화를 위해 AV 잠재에 첫 프레임 이미지를 주입합니다. 첫 프레임에 대한 충실함과 진화의 자유를 균형 있게 유지하려면
LTXVScheduler(#95)- 통합 잠재에 대한 노이즈 제거 궤적을 구동하여 오디오와 비디오가 함께 수렴하게 합니다. 복잡한 장면과 세밀한 디테일을 위해 단계를 늘리고, 초안 및 빠른 반복을 위해 줄이십시오. 스케줄 설정은 안내 강도와 상호 작용하므로, 안내가 강할 때 극단적인 값을 피하십시오. Docs/Code
LTXVLatentUpsampler(#112)- LTX-2 x2 공간 업스케일러로 두 번째 단계의 잠재 업스케일링을 수행하여 VRAM 증가를 최소화하면서 선명도를 개선합니다. 반응성을 유지하기 위해 기본 해상도를 늘리기보다는 첫 번째 패스 후에 사용하십시오. Upscaler model
DWPreprocessor(#158)- 자세 제어 경로를 위한 깨끗한 인간 자세 키포인트를 생성합니다. 미리보기로 감지를 확인하십시오; 손이나 작은 팔다리가 시끄러우면 전처리 전에 입력을 적당한 최대 차원으로 스케일하십시오. ControlNet 보조 스위트에서 제공됩니다. Repo
VHS_VideoCombine/CreateVideo(#195, #106)- 선택한 프레임 속도와 픽셀 포맷으로 MP4에 디코딩된 프레임과 오디오를 묶습니다. 오디오 디코드가 미리보기에서 정렬된 상태로 보이는지 확인한 후에만 사용하십시오. Video Helper Suite에서 제공됩니다. Repo
선택적 추가 기능#
- LTX-2 ControlNet에 대한 프롬프트
- 정적인 속성뿐만 아니라 시간에 따른 행동을 설명하십시오.
- 필요한 사운드 큐나 대화를 포함하여 오디오가 비트에 맞춰 생성되도록 합니다.
- 반복적으로 보이는 아티팩트를 억제하기 위해 간결한 부정적 프롬프트를 사용하십시오.
- 크기 및 길이
- 너비/높이의 형태로 32k + 1의 이미지 크기를 사용하십시오; 그래프가 자동으로 수정하지만 정확한 값이 반복 속도를 높입니다.
- 8k + 1의 형태로 된 프레임 수는 스케줄링에 가장 안정적입니다.
- 첫 프레임 일관성
- 잠긴 개시 구성이 필요할 때만 첫 프레임을 활성화하십시오; 중간
image_strength와 짝지어 지나치게 제한하지 않도록 합니다.
- 잠긴 개시 구성이 필요할 때만 첫 프레임을 활성화하십시오; 중간
- VRAM 및 처리량
- 워크플로우에는 멀티-GPU 또는 메모리 제약이 있는 설정을 위한 LTXVideo 패처의 시퀀스 병렬 및 토치 컴파일 옵션이 포함되어 있습니다. 긴 클립의 경우 켜고, 노드 동작을 디버그할 때는 끄십시오. Extension
감사의 말#
이 워크플로우는 다음 작품 및 리소스를 구현하고 빌드합니다. ComfyUI-LTXVideo에 대한 기여와 유지보수를 해주신 Lightricks에게 진심으로 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 레포지토리를 참조하시기 바랍니다.
리소스#
- ComfyUI-LTXVideo GitHub Repository: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
참고: 참조된 모델, 데이터셋 및 코드의 사용은 저자 및 유지보수자가 제공한 해당 라이센스 및 조건에 따릅니다.

