
ComfyUI F5 TTS: 제로샷 텍스트 음성 변환 및 음성 복제를 하나의 워크플로우에서#
이 ComfyUI F5 TTS 워크플로우는 텍스트에서 자연스러운 음성을 생성하고 ComfyUI 내에서 직접 음성을 복제할 수 있도록 합니다. ComfyUI-F5-TTS 커스텀 노드에 의해 구동되며, 참조 기반 복제를 위한 완전한 경로를 포함합니다: 짧은 WAV와 일치하는 전사를 제공하여 모델을 조건화한 후, 참조 화자의 음색과 스타일을 따르는 새로운 라인을 합성합니다. 그래프에는 여러 모델 변형, 언어 및 보코더에 대한 준비된 테스트가 포함되어 있어 출력을 빠르게 비교하고 내레이션, 음성 해설, 캐릭터 대사 또는 제품 데모에 가장 적합한 것을 결정할 수 있습니다.
모든 것이 명확한 그룹으로 배열되어 있어 ComfyUI F5 TTS를 두 가지 방식으로 사용할 수 있습니다: 빠르고, 한 번의 클릭으로 영어, 프랑스어, 독일어, 일본어에서 TTS를 실행하거나, 내장된 녹음기 또는 페어링된 파일을 통한 음성 복제. 깨끗한 녹음이 이미 있는 경우, 정확한 샘플 전사를 얻기 위해 컴팩트한 Whisper 전사 경로가 포함되어 있습니다.
ComfyUI F5 TTS 워크플로우의 주요 모델#
- Fish Audio F5-TTS. 짧은 참조에서 화자의 특성을 학습하고 여러 언어로 고품질 음성을 생성하는 제로샷 TTS. 모델 세부 사항 및 훈련 배경은 프로젝트를 참조하십시오. GitHub
- OpenAI Whisper. 참조 클립을 자동으로 전사하여 샘플 텍스트가 정확히 일치하도록 하여 복제 품질을 향상시키는 음성 인식. GitHub
- BigVGAN. 더 선명하고 또렷한 출력을 위한 디코딩 옵션으로 제공되는 고충실도 신경 보코더. GitHub
- Vocos. 속도와 낮은 지연 시간에 중점을 둔 빠르고 가벼운 신경 보코더 대안. GitHub
- ComfyUI-F5-TTS 커스텀 노드. 이 그래프 전반에 걸쳐 사용되는 F5-TTS 및 호환 가능한 백엔드를 노드로 연결하는 ComfyUI 통합. GitHub
ComfyUI F5 TTS 워크플로우 사용 방법#
고급 수준에서는 빠른 모델 비교를 위한 독립적인 그룹과 전용 복제 레인을 제공합니다. 구성된 그룹을 시험하여 선호하는 음성 및 보코더를 확인한 후, 자신의 샘플로 복제로 이동하십시오. 각 하위 섹션은 그룹이 하는 일과 중요한 몇 가지 입력을 설명합니다.
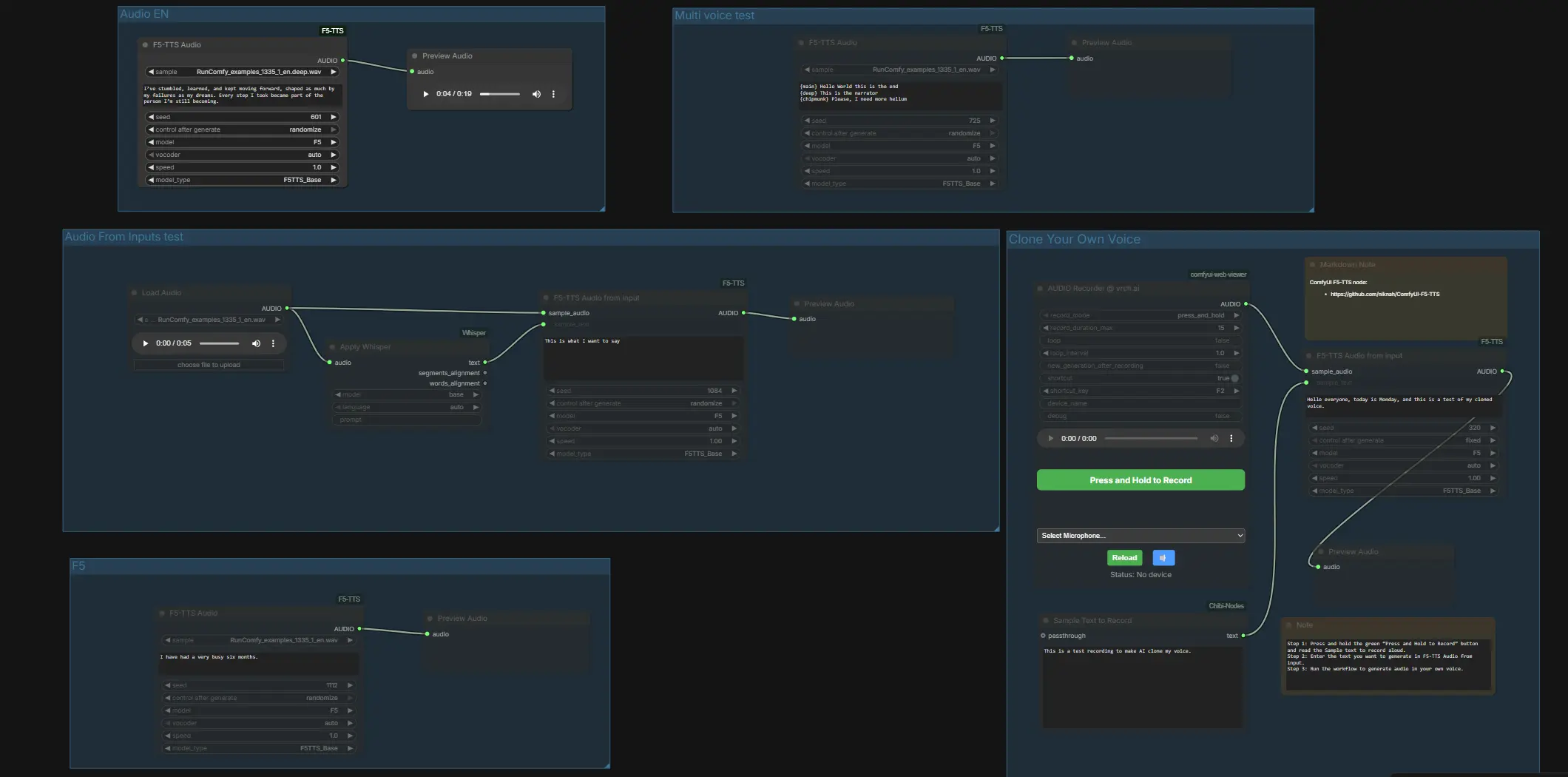
Audio From Inputs 테스트#
이 레인은 참조 전사 및 조건화를 보여줍니다. LoadAudio (#4)는 WAV를 가져오고, Apply Whisper (#13)는 이를 전사하며, F5TTSAudioInputs (#26)는 샘플 오디오와 Whisper 텍스트를 사용하여 미리보기 전에 음성을 조건화합니다. 깨끗하고 말로 된 샘플을 제공하고 Whisper가 전사 포트를 채우도록 하여 쌍이 정확히 일치하도록 하세요. 파일을 직접 제공하려면 ComfyUI/input에 동일한 파일 이름의 .wav 및 .txt를 배치한 후 ComfyUI를 다시 시작하여 그래프가 이를 볼 수 있도록 하세요.
Multi voice 테스트#
이 그룹은 단일 합성 노드를 사용하여 한 라인 내에서 스타일 전환을 보여줍니다. F5TTSAudio (#17)는 라벨이 붙은 세그먼트로 스크립트를 읽어, 한 번의 패스로 여러 캐릭터 스타일이나 강조 변경을 시험할 수 있습니다. ComfyUI F5 TTS가 대조적인 음색이나 내레이터 대 캐릭터 페이싱을 어떻게 처리하는지 듣는 빠른 방법입니다.
Audio EN#
F5TTSAudio (#15)를 사용하여 간단한 영어 TTS를 수행하세요. 스크립트를 입력하고 기본 F5 프리셋으로 발음과 페이싱의 기본선을 평가하기 위해 미리보기 하세요. 이는 복제 또는 다중 음성 혼합을 시작하기 전에 빠른 반복을 위한 이상적인 레인입니다.
F5v1#
이 경로는 F5TTSAudio (#33) 노드를 F5 v1 변형에 대해 실행하여 기본 F5 프리셋과 톤 및 프로소디를 비교할 수 있습니다. EN 레인과 동일한 텍스트를 사용하여 차이를 쉽게 판단하십시오. 긴 프로젝트에 대한 기본 모델을 선택할 때 유용합니다.
Audio FR#
이 레인은 프랑스어 프리셋으로 구성된 F5TTSAudio (#27)를 사용하여 프랑스어 합성을 목표로 합니다. 프랑스어 스크립트를 제공하고 출력물을 미리 봐서 비음 모음과 연계 처리 여부를 확인하세요. 명확성과 속도를 비교하기 위해 EN 레인과 번갈아가며 전환하십시오.
Audio DE bigvgan#
여기서는 F5TTSAudio (#30)가 독일어 프리셋과 BigVGAN 보코더를 사용하여 더 밝고 또렷한 디코드를 제공합니다. 더 많은 존재감이나 스튜디오 같은 광택을 원할 때 이 레인을 사용하세요. 부드러운 렌더링을 선호한다면 Vocos 레인과 비교하십시오.
Audio JP#
이 경로는 일본어 프리셋으로 F5TTSAudio (#25)를 사용합니다. 일본어 스크립트를 붙여넣어 피치 악센트와 모라 타이밍을 평가하세요. 애니메이션 스타일의 읽기나 일본어 청중을 위한 제품 라인에 적합한 시작점입니다.
E2 테스트#
이 그룹은 E2 호환 프리셋과 Vocos 보코더로 F5TTSAudio (#29)를 사용하여 대안 백엔드를 시험합니다. F5 실행과 지연 및 음색 특성을 비교하는 데 사용하십시오.
자신의 음성 복제#
ComfyUI에서 직접 녹음, 페어링 및 복제하세요. VrchAudioRecorderNode (#43)의 마이크 버튼을 누르고 "Sample Text to Record" 상자 Textbox (#42)에 표시된 프롬프트를 읽으세요. 녹음기는 F5TTSAudioInputs (#44)로 WAV와 함께 말한 정확한 텍스트를 라우팅하여 미리보기 전에 모델을 음색과 스타일로 조건화합니다. 최상의 결과를 얻으려면 조용한 방에서 말하고 참조 텍스트가 말한 내용과 정확히 일치하는지 확인한 다음, 복제된 음성이 말하기를 원하는 새 라인을 입력하고 그래프를 실행하십시오.
ComfyUI F5 TTS 워크플로우의 주요 노드#
F5TTSAudio (#15)#
EN, FR, DE, JP, F5v1 및 E2 그룹 전반에 걸쳐 사용되는 핵심 단일 패스 TTS 노드입니다. 스크립트를 제공하고 언어와 전달에 맞는 모델 프리셋과 보코더를 선택하세요. 재현 가능한 테이크를 원한다면 시드를 고정하고, 스타일을 탐색할 때는 실행 간에 무작위로 설정하십시오. 구현은 ComfyUI-F5-TTS 확장에 의해 제공됩니다. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
참조 WAV와 일치하는 전사를 소비하여 화자 표현을 구축한 후 그 음성으로 새로운 라인을 합성하는 복제 진입점입니다. 일관된 음량으로 깨끗한 샘플을 사용하고 전사가 최대한 유사성을 높이고 아티팩트를 줄이기 위해 정확한지 확인하세요. 더 밝거나 더 중립적인 디코드를 원할 경우 여기에서 모델 프리셋이나 보코더를 전환하십시오. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
참조 샘플에 대한 자동 전사입니다. 하드웨어 및 언어에 맞는 속도와 정확성을 균형 잡는 Whisper 크기를 선택한 다음, 그 출력을 복제 노드에 피드하여 오디오와 텍스트가 완벽하게 정렬되도록 하세요. 샘플 텍스트가 실제로 말한 것과 다를 때 발생할 수 있는 조건화 오류를 방지합니다. GitHub
VrchAudioRecorderNode (#43)#
외부 도구가 필요 없는 클론용 짧은 음성 프롬프트를 캡처하는 그래프 내 녹음기입니다. 녹음을 위해 눌렀다 놓고, 즉시 ComfyUI F5 TTS가 자신의 목소리로 어떻게 들리는지 들어보세요. 마이크를 가까이 두고 방의 소음을 줄여 가장 깨끗한 결과를 얻으세요.
선택적 추가 기능#
- 음악이나 효과 없이 5~15초의 깨끗한 음성을 참조용으로 사용하세요.
- 샘플 전사가 녹음과 정확히 일치하는지 확인하세요; 작은 불일치도 복제 충실도를 저하시킬 수 있습니다.
- 동일한 라인에서 Vocos 및 BigVGAN을 비교하여 속도와 디테일을 결정하세요.
- 일관된 재촬영이 필요할 때는 시드를 고정하고, 스타일을 탐색할 때는 무작위로 설정하세요.
- 다국어 프로젝트의 경우 EN, FR, DE, JP 레인을 먼저 시험한 후 발음과 페이싱에 만족하면 복제를 완료하세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 ComfyUI-F5-TTS 노드를 위한 niknah, F5TTS-test-all.json 예제 워크플로우를 위한 niknah, 그리고 r/StableDiffusion 커뮤니티의 “Voice Cloning with F5-TTS in ComfyUI” 가이드에 대한 기여와 유지 관리에 대해 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Example Workflow: F5TTS-test-all.json)
- r/StableDiffusion/Community Guide (Voice Cloning with F5-TTS in ComfyUI)
Note: 사용된 모델, 데이터셋 및 코드는 작성자 및 유지 관리자가 제공하는 해당 라이선스 및 조건에 따릅니다.