
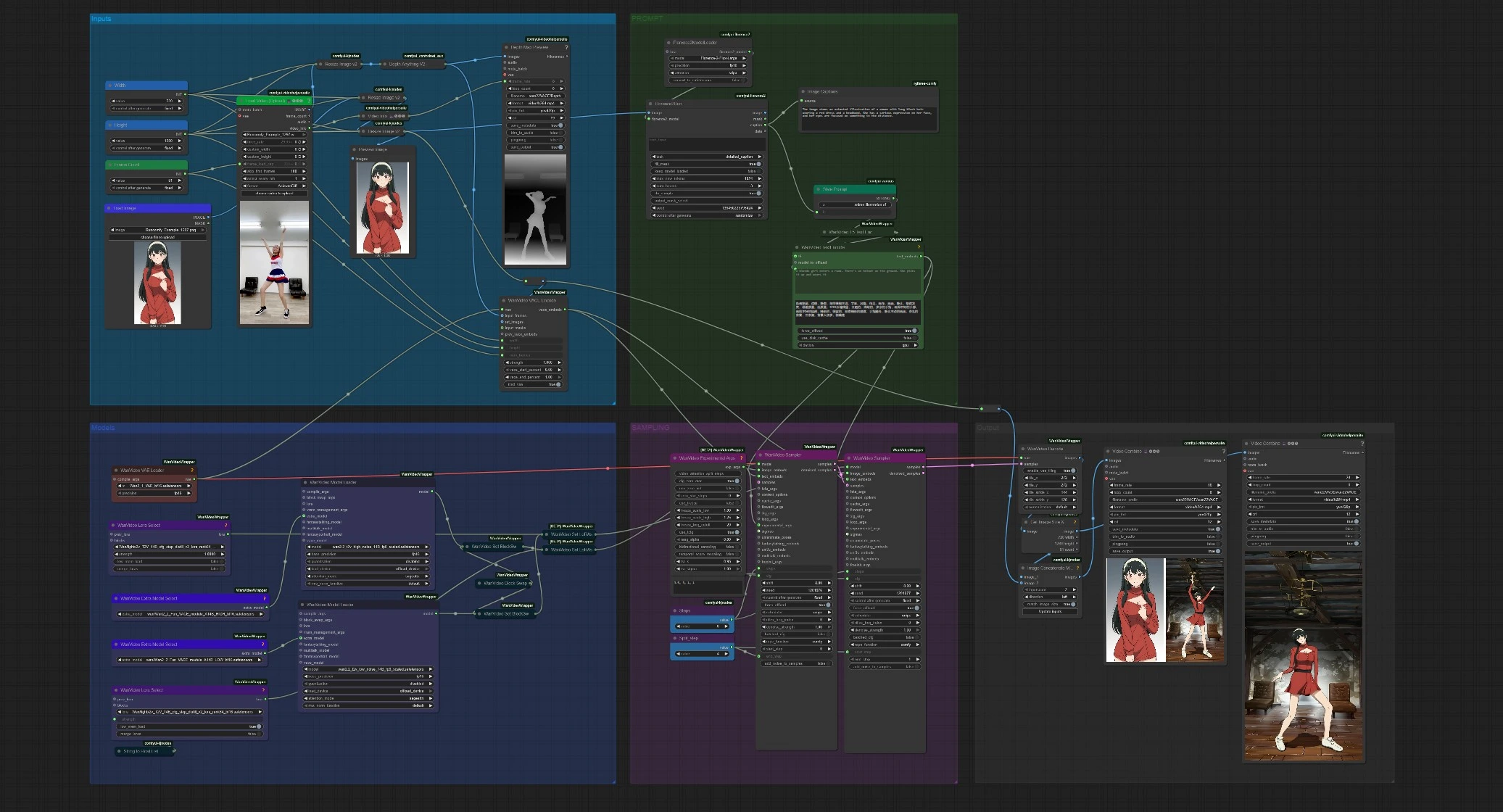
Generazione di video guidata dalla posa Wan 2.2 VACE per ComfyUI#
Questo flusso di lavoro ComfyUI Wan 2.2 VACE trasforma una singola immagine di riferimento in un video che segue la posa, il ritmo e il movimento della fotocamera di una clip sorgente. Utilizza Wan 2.2 VACE per preservare l'identità mentre traduce movimenti corporei complessi in un'animazione fluida e realistica.
Progettato per la generazione di danza, il trasferimento di movimento e l'animazione creativa di personaggi, il flusso di lavoro automatizza la creazione di stile dall'immagine di riferimento, estrae segnali di movimento dal video sorgente e esegue un campionatore Wan 2.2 a due stadi che bilancia coerenza del movimento e dettaglio fine.
Modelli chiave nel flusso di lavoro Comfyui Wan 2.2 VACE#
- Modelli Text-to-Video Wan 2.2 14B (varianti ad alto e basso rumore). I due stadi utilizzano un backbone ad alto rumore per una modellazione robusta del movimento seguito da un backbone a basso rumore per il raffinamento dei dettagli.
- Wan 2.1 VAE (bf16). Decodifica e codifica i frame video latenti per Wan 2.2 VACE.
- Google UMT5-XXL Encoder. Fornisce caratteristiche testuali ad alta capacità utilizzate da Wan 2.2 per il condizionamento. Model card
- Microsoft Florence-2 (Flux Large). Genera una ricca didascalia dall'immagine di riferimento per avviare e stilizzare il prompt. Repo
- Depth Anything v2 (ViT-L). Produce mappe di profondità per frame dal video sorgente di movimento per guidare struttura e movimento. Repo
Come utilizzare il flusso di lavoro Comfyui Wan 2.2 VACE#
Il flusso di lavoro ha cinque fasi raggruppate: Input, PROMPT, Modelli, CAMPIONAMENTO e Output. Fornisci un'immagine di riferimento e un breve video di movimento. Il grafico quindi calcola la guida al movimento, codifica le caratteristiche di identità VACE, esegue un campionatore Wan 2.2 a due passaggi, e salva sia l'animazione finale che un'anteprima opzionale fianco a fianco.
Inputs#
Carica una clip sorgente di movimento in VHS_LoadVideo (#141). Puoi tagliare con controlli semplici e limitare i frame per la memoria. I frame vengono ridimensionati per la coerenza, quindi DepthAnythingV2Preprocessor (#135) calcola una sequenza di profondità densa che cattura posa, layout e movimento della fotocamera. Carica la tua immagine di identità con LoadImage (#113); viene ridimensionata automaticamente e visualizzata in anteprima così puoi verificare l'inquadratura prima del campionamento.
PROMPT#
Florence2Run (#137) analizza l'immagine di riferimento e restituisce una didascalia dettagliata. Style Prompt (#138) concatena quella didascalia con una breve frase di stile, quindi WanVideoTextEncode (#16) codifica i prompt positivi e negativi finali usando UMT5-XXL. Puoi liberamente modificare la frase di stile o sostituire completamente il prompt positivo se desideri una direzione creativa più forte. Questo embedding del prompt condiziona entrambi gli stadi del campionatore così il video generato rimane fedele al tuo riferimento.
Models#
WanVideoVAELoader (#38) carica il Wan VAE usato per codificare/decodificare. Due nodi WanVideoModelLoader preparano i modelli Wan 2.2 14B: uno ad alto rumore e uno a basso rumore, ciascuno aumentato con un modulo VACE selezionato in WanVideoExtraModelSelect (#99, #107). Il raffinamento opzionale LoRA è attaccato tramite WanVideoLoraSelect (#56, #97), permettendoti di regolare nitidezza o stile senza cambiare i modelli di base. La configurazione è progettata in modo che tu possa scambiare pesi VACE, LoRA o la variante di rumore senza toccare il resto del grafico.
SAMPLING#
WanVideoVACEEncode (#100) fonde tre segnali in embedding VACE: la sequenza di movimento (frame di profondità), la tua immagine di riferimento e la geometria del video target. Il primo WanVideoSampler (#27) esegue il modello ad alto rumore fino a uno step di divisione per stabilire movimento, prospettiva e stile globale. Il secondo WanVideoSampler (#90) riprende da quel latente e termina con il modello a basso rumore per recuperare texture, bordi e piccoli dettagli mantenendo il movimento bloccato alla sorgente. Un breve programma CFG e split step controllano quanto ciascuno stadio influenza il risultato.
Output#
WanVideoDecode (#28) converte il latente finale in frame. Ottieni due video salvati: un rendering pulito e una concatenazione fianco a fianco che posiziona i frame generati accanto al riferimento per un rapido QA. Una "Anteprima Mappa di Profondità" separata mostra la sequenza di profondità dedotta così puoi diagnosticare la guida al movimento a colpo d'occhio. Le impostazioni di frame rate e nome file sono disponibili negli output VHS_VideoCombine (#139, #60, #144).
Nodi chiave nel flusso di lavoro Comfyui Wan 2.2 VACE#
WanVideoVACEEncode (#100)#
Crea gli embedding di identità e geometria VACE usati da entrambi i campionatori. Fornisci i tuoi frame di movimento e l'immagine di riferimento; il nodo gestisce larghezza, altezza e conteggio dei frame. Se cambi durata o aspetto, mantieni questo nodo sincronizzato così gli embedding corrispondono al layout del video target.
WanVideoSampler (#27)#
Campionatore del primo stadio usando il modello ad alto rumore Wan 2.2. Regola steps, un breve programma cfg, e lo end_step split per decidere quanto della traiettoria è allocato alla modellazione del movimento. Cambiamenti di movimento o di fotocamera maggiori beneficiano di uno split leggermente successivo.
WanVideoSampler (#90)#
Campionatore del secondo stadio usando il modello a basso rumore Wan 2.2. Imposta start_step sullo stesso valore di split così continua senza problemi dal primo stadio. Se vedi una sovrasaturazione delle texture o una deriva, riduci i valori cfg successivi o abbassa la forza di LoRA.
DepthAnythingV2Preprocessor (#135)#
Estrae una sequenza di profondità stabile dal video sorgente. Usare la profondità come guida al movimento aiuta Wan 2.2 VACE a mantenere layout della scena, posa delle mani e occlusione. Per iterazioni rapide, puoi ridimensionare i frame di input più piccoli; per rendering finali, fornisci frame ad alta risoluzione per una migliore fedeltà strutturale.
WanVideoTextEncode (#16)#
Codifica i prompt positivi e negativi con UMT5-XXL. Il prompt è auto-costruito da Florence2Run, ma puoi sovrascriverlo per la direzione artistica. Mantieni i prompt concisi; con la guida di identità VACE, meno parole chiave spesso producono un trasferimento di movimento più pulito e meno vincolato.
Extra opzionali#
- Scegli clip di movimento con chiara separazione del soggetto e illuminazione coerente per i trasferimenti più stabili di Wan 2.2 VACE.
- Usa l'output fianco a fianco per verificare l'allineamento del viso e la continuità dell'outfit prima di eseguire un passaggio finale.
- Se il movimento sembra troppo rigido, sposta lo split un po' prima così lo stadio a basso rumore ha più spazio per raffinarsi.
- Se l'identità sta scivolando, aumenta leggermente l'influenza di LoRA o semplifica il prompt.
- L'anteprima della profondità è tua amica: se la profondità è rumorosa, prova una clip sorgente diversa o regola il ridimensionamento dell'input per ridurre gli artefatti.
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Riconosciamo con gratitudine i creatori della comunità ComfyUI di Wan 2.2 VACE Source per il flusso di lavoro, per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- Documenti / Note di Rilascio: Wan 2.2 VACE @ComfyUI
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.