
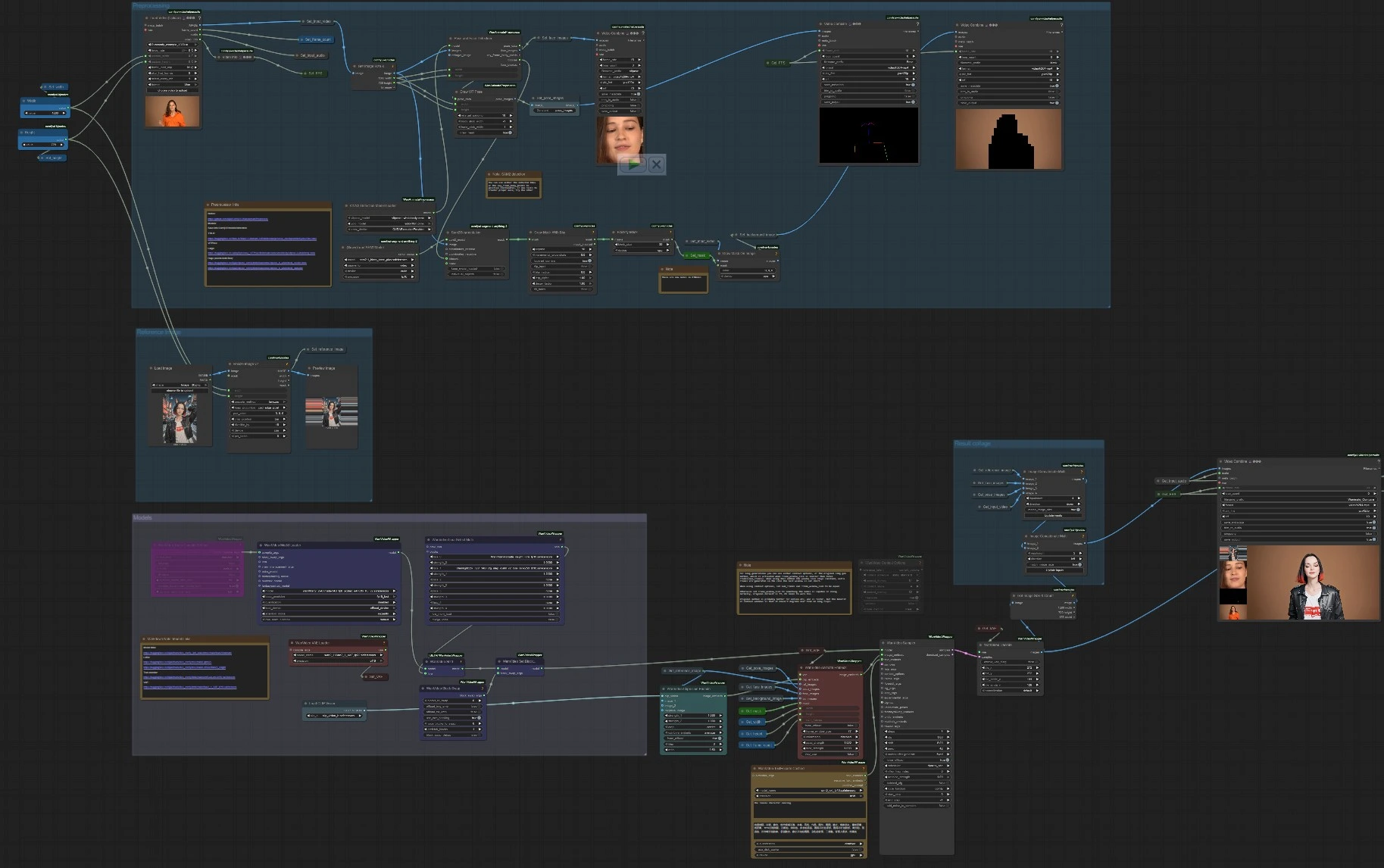
Workflow di generazione video basato su pose Wan 2.2 Animate V2 per ComfyUI#
Wan 2.2 Animate V2 è un workflow di generazione video basato su pose che trasforma un'unica immagine di riferimento più un video di pose guida in un'animazione realistica che preserva l'identità. Si basa sulla prima versione con maggiore fedeltà, movimento più fluido e migliore coerenza temporale, seguendo da vicino il movimento a corpo intero e le espressioni dal video sorgente.
Questo workflow ComfyUI è progettato per i creatori che desiderano risultati rapidi e affidabili per l'animazione di personaggi, clip di danza e narrazione basata sulle performance. Combina un robusto pre-elaborazione (pose, volto e mascheramento del soggetto) con la famiglia di modelli Wan 2.2 e LoRAs opzionali, così puoi regolare stile, illuminazione e gestione dello sfondo con fiducia.
Modelli chiave nel workflow ComfyUI Wan 2.2 Animate V2#
- Wan 2.2 Animate 14B. Modello di diffusione video principale che sintetizza fotogrammi temporalmente coerenti da embedding multimodali. Pesi: Kijai/WanVideo_comfy_fp8_scaled (Wan22Animate).
- Wan 2.1 VAE. Decoder/encoder video latente utilizzato dalla famiglia Wan per ricostruire fotogrammi RGB con perdita minima. Pesi: Wan2_1_VAE_bf16.safetensors.
- UMT5‑XXL text encoder. Codifica i prompt che guidano l'aspetto, la scena e la cinematica. Pesi: umt5‑xxl‑enc‑bf16.safetensors.
- CLIP Vision (ViT‑H/14). Estrae caratteristiche che preservano l'identità dall'immagine di riferimento. Documento: CLIP.
- ViTPose Whole‑Body (ONNX). Stima i punti chiave del corpo densi che guidano il trasferimento del movimento. Modelli: ViTPose‑L WholeBody e ViTPose‑H WholeBody. Documento: ViTPose.
- Rilevatore YOLOv10. Fornisce scatole di persone per stabilizzare il rilevamento delle pose e la segmentazione. Esempio: yolov10m.onnx.
- Segment Anything 2. Maschere di soggetti di alta qualità per la conservazione dello sfondo, compositing o anteprime di rilighting. Repo: facebookresearch/segment-anything-2.
- LoRAs opzionali per il trasporto di stile e luce. Utile per il rilighting e il dettaglio della texture negli output di Wan 2.2 Animate V2. Esempi: Lightx2v e Wan22_relight.
Come usare il workflow ComfyUI Wan 2.2 Animate V2#
A livello generale, la pipeline estrae segnali di posa e volto dal video guida, codifica l'identità da un'unica immagine di riferimento, isola opzionalmente il soggetto con una maschera SAM 2, e quindi sintetizza un video che corrisponde al movimento preservando l'identità. Il workflow è organizzato in quattro gruppi che collaborano per produrre il risultato finale e due output di convenienza per QA rapido (anteprime di posa e maschera).
Immagine di Riferimento#
Questo gruppo carica il tuo ritratto o immagine a corpo intero, la ridimensiona alla risoluzione target e la rende disponibile attraverso il grafo. L'immagine ridimensionata è memorizzata e riutilizzata da Get_reference_image e previsualizzata per permetterti di valutare rapidamente l'inquadratura. Le caratteristiche di identità sono codificate da WanVideoClipVisionEncode (CLIP Vision) (#70), e la stessa immagine alimenta WanVideoAnimateEmbeds (#62) come ref_images per una conservazione dell'identità più forte. Fornisci un riferimento chiaro e ben illuminato che corrisponda al tipo di soggetto nel video guida per ottenere i migliori risultati. Spazio per la testa e occlusioni minime aiutano Wan 2.2 Animate V2 ad agganciarsi alla struttura del volto e agli abiti.
Pre-elaborazione#
Il video guida è caricato con VHS_LoadVideo (#191), che espone fotogrammi, audio, conteggio dei fotogrammi e fps sorgente per uso successivo. I segnali di posa e volto sono estratti da OnnxDetectionModelLoader (#178) e PoseAndFaceDetection (#172), quindi visualizzati con DrawViTPose (#173) per confermare la qualità del tracciamento. L'isolamento del soggetto è gestito da Sam2Segmentation (#104), seguito da GrowMaskWithBlur (#182) e BlockifyMask (#108) per produrre una maschera pulita e stabile; un helper DrawMaskOnImage (#99) previsualizza il matte. Il gruppo standardizza anche larghezza, altezza e conteggio dei fotogrammi dal video guida, così Wan 2.2 Animate V2 può abbinare le impostazioni spaziali e temporali senza supposizioni. Controlli rapidi esportano come video brevi: un overlay di posa e un'anteprima di maschera per la convalida zero-shot.
Modelli#
WanVideoVAELoader (#38) carica il Wan VAE e WanVideoModelLoader (#22) carica il backbone Wan 2.2 Animate. LoRAs opzionali sono scelte in WanVideoLoraSelectMulti (#171) e applicate tramite WanVideoSetLoRAs (#48); WanVideoBlockSwap (#51) può essere abilitato tramite WanVideoSetBlockSwap (#50) per modifiche architettoniche che influenzano stile e fedeltà. I prompt sono codificati da WanVideoTextEncodeCached (#65), mentre WanVideoClipVisionEncode (#70) trasforma l'immagine di riferimento in embedding di identità robusti. WanVideoAnimateEmbeds (#62) fonde le caratteristiche CLIP, l'immagine di riferimento, le immagini di posa, i ritagli del volto, i fotogrammi di sfondo opzionali, la maschera SAM 2 e la risoluzione e il conteggio dei fotogrammi scelti in un unico embedding di animazione. Quel feed guida WanVideoSampler (#27), che sintetizza video latenti coerenti con il tuo prompt, identità e segnali di movimento, e WanVideoDecode (#28) converte i latenti in fotogrammi RGB.
Collage di Risultati#
Per aiutare a confrontare gli output, il workflow assembla un semplice fianco a fianco: il video generato accanto a una striscia verticale che mostra l'immagine di riferimento, i ritagli del volto, l'overlay di posa e un fotogramma del video guida. ImageConcatMulti (#77, #66) costruisce il collage visivo, quindi VHS_VideoCombine (#30) rende un mp4 “Confronta”. L'output finale pulito è reso da VHS_VideoCombine (#189), che trasporta anche l'audio dal driver per tagli di revisione rapida. Queste esportazioni rendono facile giudicare quanto bene Wan 2.2 Animate V2 abbia seguito il movimento, preservato l'identità e mantenuto lo sfondo previsto.
Nodi chiave nel workflow ComfyUI Wan 2.2 Animate V2#
VHS_LoadVideo (#191) Carica il video guida ed espone fotogrammi, audio e metadati usati nel grafo. Mantieni il soggetto completamente visibile con sfocatura del movimento minima per un tracciamento dei punti chiave più forte. Se desideri test più brevi, limita il numero di fotogrammi caricati; mantieni il fps sorgente coerente a valle per evitare desincronizzazioni audio nel combinato finale.
PoseAndFaceDetection (#172) Esegue YOLO e ViTPose per produrre punti chiave a corpo intero e ritagli del volto che guidano direttamente il trasferimento del movimento. Forniscigli le immagini dal loader e la larghezza e altezza standardizzate; l'input opzionale retarget_image consente di adattare le pose a un'inquadratura diversa quando necessario. Se l'overlay di posa sembra rumoroso, considera un modello ViTPose di qualità superiore e assicurati che il soggetto non sia fortemente occluso. Riferimento: ComfyUI‑WanAnimatePreprocess.
Sam2Segmentation (#104) Genera una maschera del soggetto che può preservare lo sfondo o localizzare il rilighting in Wan 2.2 Animate V2. Puoi utilizzare le scatole di rilevamento da PoseAndFaceDetection o disegnare punti positivi rapidi se necessario per affinare il matte. Abbinalo a GrowMaskWithBlur per bordi più puliti su movimenti rapidi e rivedi il risultato con l'esportazione dell'anteprima della maschera. Riferimento: Segment Anything 2.
WanVideoClipVisionEncode (#70) Codifica l'immagine di riferimento con CLIP Vision per catturare segnali di identità come la struttura del volto, i capelli e gli abiti. Puoi mediare più immagini di riferimento per stabilizzare l'identità o usare un'immagine negativa per sopprimere tratti indesiderati. Ritagli centrati con illuminazione coerente aiutano a produrre embedding più forti.
WanVideoAnimateEmbeds (#62) Fonde caratteristiche di identità, immagini di posa, ritagli del volto, fotogrammi di sfondo opzionali e la maschera SAM 2 in un unico embedding di animazione. Allinea width, height e num_frames con il tuo video guida per meno artefatti. Se vedi deriva dello sfondo, fornisci fotogrammi di sfondo puliti e una maschera solida; se il volto deraglia, assicurati che i ritagli del volto siano presenti e ben illuminati.
WanVideoSampler (#27) Produce i latenti video effettivi guidati dal tuo prompt, LoRAs e l'embedding di animazione. Per clip lunghe, scegli tra una strategia a finestra scorrevole o le opzioni di contesto del modello; abbina la finestratura alla lunghezza della clip per bilanciare nitidezza del movimento e coerenza a lungo raggio. Regola il scheduler e la forza della guida per scambiare fedeltà, aderenza allo stile e fluidità del movimento, e considera l'abilitazione dello scambio di blocchi se il tuo stack LoRA ne beneficia.
Extra opzionali#
- Inizia con una clip driver pulita: una fotocamera stabile, illuminazione semplice e occlusione minima danno a Wan 2.2 Animate V2 la migliore possibilità di tracciare il movimento in modo pulito.
- Usa un riferimento che corrisponda all'outfit e all'inquadratura target; evita angoli estremi o filtri pesanti che confliggono con il tuo prompt o LoRAs.
- Preserva o sostituisci gli sfondi con la maschera SAM 2; quando componi, mantieni i bordi abbastanza morbidi da evitare l'alone su movimenti rapidi.
- Mantieni il fps coerente dal caricamento all'esportazione per mantenere la sincronizzazione labiale e l'allineamento del ritmo quando si trasporta l'audio.
- Per un'iterazione rapida, testa prima un breve segmento, quindi estendi l'intervallo dei fotogrammi una volta che posa, identità e illuminazione sembrano a posto.
Risorse utili utilizzate in questo workflow:
- Nodi di pre-elaborazione: kijai/ComfyUI‑WanAnimatePreprocess
- Modelli ViTPose ONNX: ViTPose‑L, modello ViTPose‑H e dati
- Rilevatore YOLOv10: yolov10m.onnx
- Pesi Wan 2.2 Animate 14B: Wan22Animate
- LoRAs: Lightx2v, Wan22_relight
Ringraziamenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine il workflow di Benji’s AI Playground e il team Wan per il modello Wan 2.2 Animate V2 per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Wan team/Wan 2.2 Animate V2
- Documenti / Note di rilascio: YouTube @Benji’s AI Playground
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.