
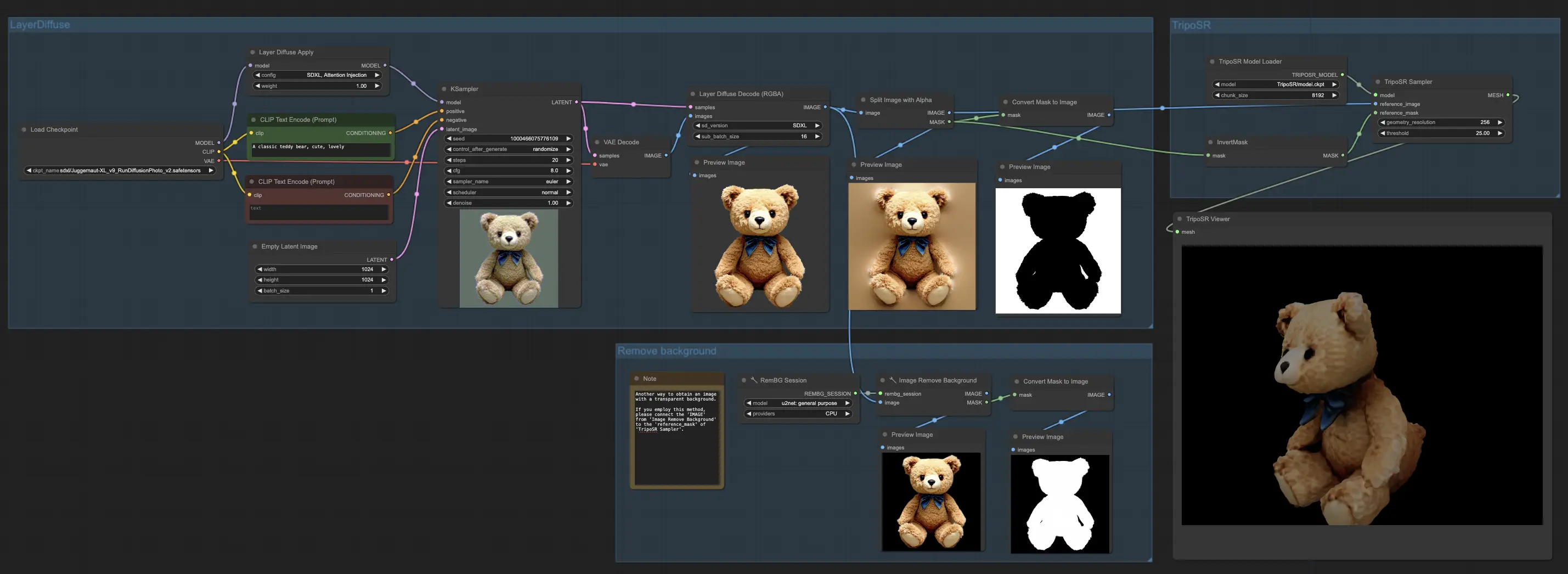
1. Flusso di lavoro ComfyUI: LayerDiffuse + TripoSR | Da immagine a 3D#
Nel flusso di lavoro ComfyUI, sfruttiamo le capacità di LayerDiffuse per produrre immagini con sfondi trasparenti. Successivamente, sia l'immagine che la sua maschera vengono passate a TripoSR per la creazione di oggetti 3D. Il risultato è un modello 3D approssimativo ma prodotto rapidamente, che mostra un promettente potenziale per ulteriori perfezionamenti.
Per coloro che sono interessati a ottenere il file mesh (.obj), è possibile trovarlo nella sezione di output del file system. Questo processo semplificato offre un percorso diretto dall'immagine al modello 3D, combinando i punti di forza di LayerDiffuse e TripoSR per migliorare l'esperienza di creazione 3D.
2. Panoramica di LayerDiffuse#
Per favore, consulta i dettagli su Come utilizzare LayerDiffuse in ComfyUI
3. Panoramica di TripoSR#
3.1. Introduzione a TripoSR#
TripoSR è un modello di ricostruzione 3D all'avanguardia che trasforma rapidamente singole immagini in oggetti 3D con una velocità e una precisione sorprendenti. Questa innovazione è uno sforzo congiunto di Tripo AI e Stability AI. Utilizzando un'architettura transformer, TripoSR si distingue per la sua capacità di elaborare rapidamente le immagini in forme 3D. Si basa sull'architettura di rete Large Reconstruction Model (LRM), ma introduce significativi miglioramenti nella gestione dei dati, nella progettazione del modello e nel perfezionamento del processo di addestramento. Questi progressi rendono TripoSR più accurato ed efficiente rispetto ad altri modelli disponibili oggi.
3.2. Architettura tecnica di TripoSR#
Il nucleo di TripoSR include tre parti principali: un codificatore di immagini, un decodificatore da immagine a triplano e un campo di radianza neurale (NeRF) basato su triplano. Il codificatore di immagini utilizza un modello di trasformatore di visione pre-addestrato per catturare sia i dettagli ampi che quelli specifici di un'immagine di input. Questi dettagli vengono poi trasformati in un modello 3D dettagliato utilizzando l'innovativa configurazione triplano-NeRF. In modo unico, TripoSR può indovinare le impostazioni della fotocamera, rendendolo versatile ed efficiente in diverse condizioni di immagine senza la necessità di informazioni esatte sulla fotocamera.
3.3. Benchmarking delle prestazioni di TripoSR#
Le prestazioni di TripoSR si distinguono quando vengono confrontate con altri modelli leader. Supera costantemente nella cattura delle texture fini e delle forme complesse degli oggetti in modo rapido. Questa prestazione eccezionale, ottenuta rapidamente su hardware informatico standard, mostra il potenziale di TripoSR di cambiare il panorama della ricostruzione 3D.
