
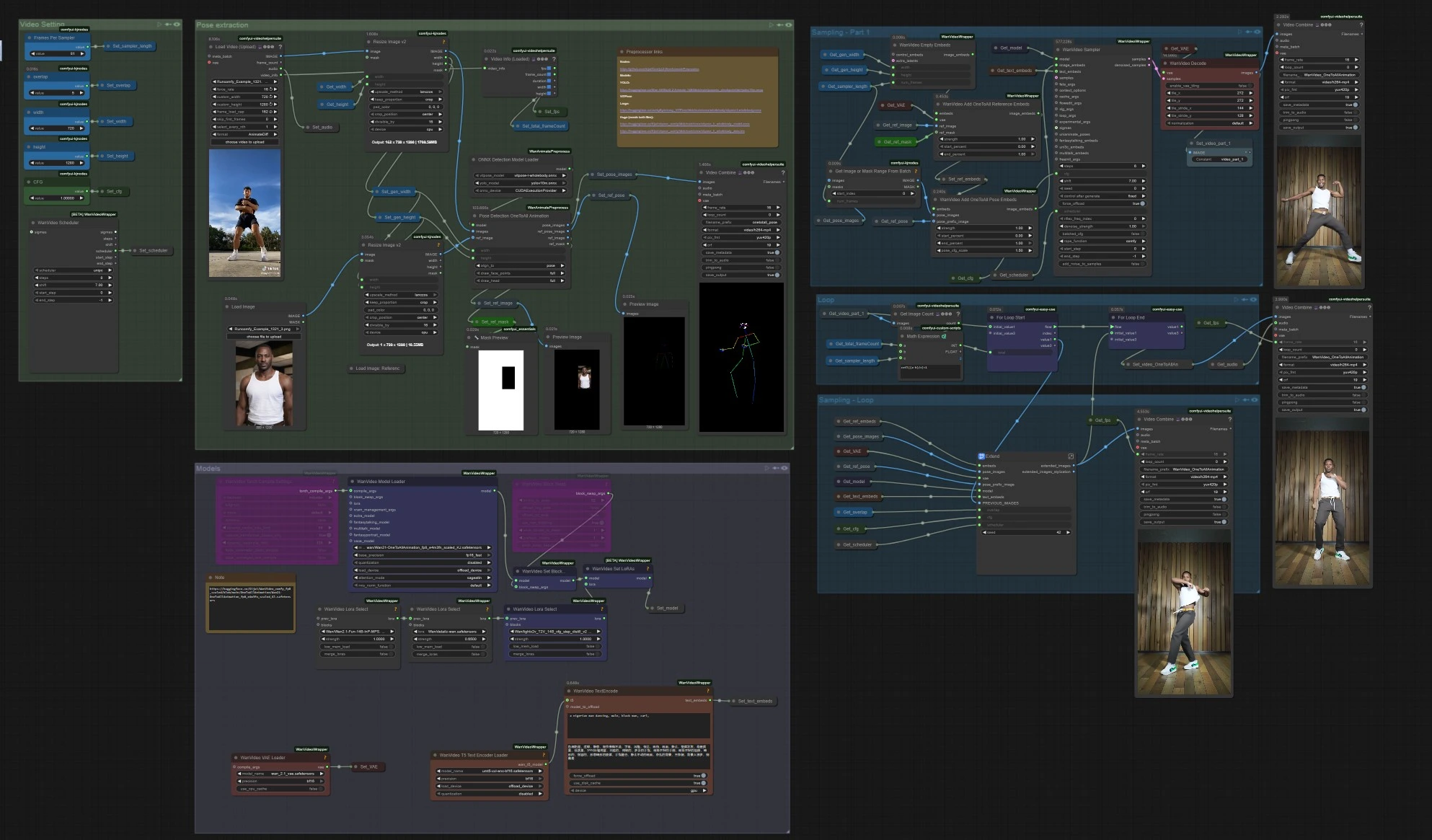
One to All Animation: video di personaggi allineati alla posa a lungo termine in ComfyUI#
Questo flusso di lavoro One to All Animation trasforma un breve clip di riferimento in un video esteso e ad alta fedeltà mantenendo il movimento, l'allineamento delle pose e l'identità dei personaggi coerenti durante l'intera sequenza. Costruito attorno alla generazione video Wan 2.1 con guida alla posa del corpo intero e un'estensione a finestra scorrevole, è ideale per la danza, la cattura delle performance e le riprese narrative in cui desideri che un unico look segua movimenti complessi.
Se sei un creatore che ha bisogno di risultati stabili e guidati dalle pose senza tremolio o deriva dell'identità, One to All Animation ti offre un percorso chiaro: estrai le pose dal tuo video sorgente, fondile con un'immagine di riferimento e una maschera, genera il primo segmento, quindi estendi quel segmento ripetutamente fino a coprire l'intera lunghezza.
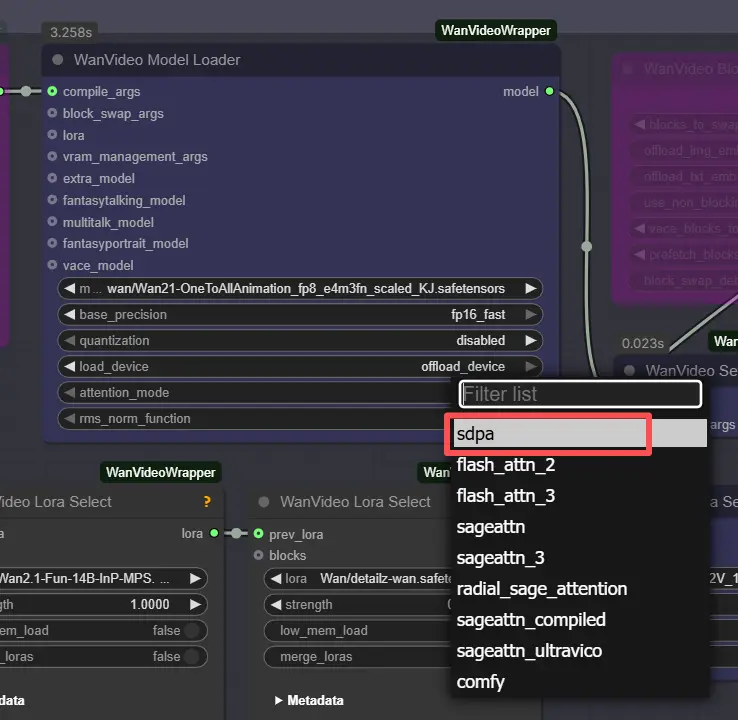
Nota: Su macchine 2XL o 3XL, imposta l'attention_mode su "sdpa" nel nodo WanVideo Model Loader. Il backend predefinito segeattn può causare problemi di compatibilità su GPU di fascia alta.
Modelli chiave nel flusso di lavoro Comfyui One to All Animation#
- Wan 2.1 OneToAllAnimation (generazione video). Il principale modello di diffusione utilizzato per il movimento di alta qualità e il mantenimento dell'identità. Pesi di esempio: Wan21‑OneToAllAnimation fp8 scalato da Kijai. Model card
- UMT5‑XXL text encoder. Codifica i prompt per la generazione video Wan. Model card
- ViTPose Whole‑Body (stima delle pose). Produce punti chiave scheletrici densi che guidano la fedeltà delle pose. Vedi il paper ViTPose e i pesi ONNX del corpo intero. Paper • Weights
- Rilevatore YOLOv10m (rilevamento persona/regione). Velocizza l'estrazione delle pose robuste concentrando l'estimatore sul soggetto. Paper • Weights
- Alternativa opzionale ViTPose‑H. Modello del corpo intero ad alta capacità per movimenti impegnativi. Weights e data file
- Pacchetti LoRA opzionali per stile/controllo. Esempi di LoRA utilizzati in questo grafo includono Wan2.1‑Fun‑InP‑MPS, detailz‑wan e lightx2v T2V; affinano texture, dettagli o controllo in loco senza riaddestramento.
Come utilizzare il flusso di lavoro Comfyui One to All Animation#
Flusso generale
- Il flusso di lavoro legge il tuo video di movimento di riferimento, estrae le pose del corpo intero, prepara gli embedding One to All Animation che fondono posa e riferimento del personaggio, genera un clip iniziale, quindi estende ripetutamente quel clip con sovrapposizione fino a coprire l'intera durata. Infine, unisce l'audio ed esporta un video completo.
Estrazione delle pose
- Carica la tua sorgente di movimento in
VHS_LoadVideo(#454). I fotogrammi vengono ridimensionati conImageResizeKJv2(#131) per adattarsi al rapporto d'aspetto della generazione per un campionamento stabile. OnnxDetectionModelLoader(#128) carica YOLOv10m e ViTPose del corpo intero;PoseDetectionOneToAllAnimation(#141) quindi emette una mappa delle pose per fotogramma, un'immagine di posa di riferimento e una maschera di riferimento pulita.- Usa
PreviewImage(#145) per ispezionare rapidamente che le pose seguano il soggetto. Filmati chiari e ad alto contrasto con sfocatura minima del movimento danno i migliori risultati One to All Animation.
Modelli
WanVideoModelLoader(#22) carica i pesi Wan 2.1 OneToAllAnimation;WanVideoVAELoader(#38) fornisce il VAE abbinato. Se desiderato, impila LoRA di stile/controllo tramiteWanVideoLoraSelect(#452, #451, #56) e applicali conWanVideoSetLoRAs(#80).- I prompt di testo sono codificati da
WanVideoTextEncode(#16). Scrivi un prompt positivo conciso e focalizzato sull'identità e un forte negativo di pulizia per mantenere il personaggio sul modello.
Impostazione video
- Larghezza e altezza sono impostate nel gruppo "Video Setting" e propagate all'estrazione delle pose e alla generazione in modo che tutto rimanga allineato.
Nota: ⚠️ Limite di Risoluzione : Questo flusso di lavoro è fissato a 720×1280 (720p). Usare qualsiasi altra risoluzione causerà errori di disallineamento delle dimensioni a meno che il flusso di lavoro non venga riconfigurato manualmente.
WanVideoScheduler(#231) e il controlloCFGselezionano il programma di rumore e la forza del prompt. CFG più elevato aderisce maggiormente al prompt; valori più bassi seguono un po' più liberamente la posa ma possono ridurre gli artefatti.VHS_VideoInfoLoaded(#440) legge l'fpt e il conteggio dei fotogrammi del clip sorgente, che il loop usa per determinare quanti finestre One to All Animation sono necessarie.
Campionamento – Parte 1
WanVideoEmptyEmbeds(#99) crea un contenitore per il condizionamento alla dimensione target.WanVideoAddOneToAllReferenceEmbeds(#105) inietta la tua immagine di riferimento e il suoref_maskper bloccare l'identità e preservare o ignorare aree come sfondo o abbigliamento.WanVideoAddOneToAllPoseEmbeds(#98) allega lepose_imagesestratte e l'immagine dipose_prefixin modo che il primo pezzo generato segua il movimento sorgente dal primo fotogramma.WanVideoSampler(#27) produce il clip latente iniziale, che viene decodificato daWanVideoDecode(#28) e opzionalmente visualizzato in anteprima o salvato conVHS_VideoCombine(#139). Questo è il segmento seme da estendere.
Loop
VHS_GetImageCount(#327) eMathExpression|pysssss(#332) calcolano quanti passaggi di estensione sono richiesti in base ai fotogrammi totali e alla lunghezza per passaggio.easy forLoopStart(#329) inizia i passaggi di estensione usando il clip iniziale come contesto di partenza.
Campionamento – Loop
Extend(#263) è il cuore dell'animazione One to All di lunga durata. Ricomputa il condizionamento conWanVideoAddOneToAllExtendEmbeds(all'interno del sottografo) per mantenere la continuità dai latenti precedenti, quindi campiona e decodifica la finestra successiva.ImageBatchExtendWithOverlap(all'interno diExtend) fonde ogni nuova finestra sul video accumulato utilizzando una regione dioverlap, levigando i confini e riducendo le cuciture temporali.easy forLoopEnd(#334) aggiunge ogni blocco esteso. Il risultato è memorizzato tramiteSet_video_OneToAllAnimation(#386) per l'esportazione.
Esportazione
VHS_VideoCombine(#344) scrive il video finale, utilizzando l'fpt sorgente e l'audio opzionale daVHS_LoadVideo. Se preferisci un risultato silenzioso, ometti o silenzia l'input audio qui.
Nodi chiave nel flusso di lavoro Comfyui One to All Animation#
PoseDetectionOneToAllAnimation (#141)
- Rileva il soggetto e stima i punti chiave del corpo intero che guidano la guida alla posa. Supportato da YOLOv10 e ViTPose, è robusto a movimenti rapidi e occlusioni parziali. Se il tuo soggetto si sposta o le scene con più persone confondono il rilevatore, ritaglia il tuo input o passa ai pesi ViTPose‑H ad alta capacità collegati sopra.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Fonde un'immagine di riferimento e
ref_masknel condizionamento in modo che l'identità, l'abbigliamento o le regioni protette rimangano stabili tra i fotogrammi. Maschere strette preservano volti e capelli; maschere più ampie possono bloccare gli sfondi. Quando si cambia look, sostituisci il riferimento e mantieni lo stesso movimento.
WanVideoAddOneToAllPoseEmbeds (#98)
- Vincola le mappe delle pose e una posa di prefisso agli embedding One to All Animation. Per una coreografia più rigorosa, aumenta l'influenza della posa; per un'interpretazione più libera, riducila leggermente. Combina con LoRAs quando desideri una texture coerente pur mantenendo il movimento.
WanVideoSampler (#27)
- Il principale campionatore video che trasforma gli embedding e il testo nel clip latente iniziale.
cfgcontrolla l'aderenza al prompt eschedulerscambia qualità, velocità e stabilità. Usa la stessa famiglia di campionatori qui e nel loop per evitare sfarfallii.
Extend (#263)
- Un sottografo compatto che esegue l'estensione a finestra scorrevole con sovrapposizione. L'impostazione
overlapè la manopola chiave: più sovrapposizione fonde le transizioni in modo più fluido a costo di calcoli extra; meno sovrapposizione è più veloce ma può rivelare cuciture. Questo nodo riutilizza anche i latenti precedenti per mantenere la scena e il personaggio coerenti tra le finestre.
VHS_VideoCombine (#344)
- Muxing finale e salvataggio. Imposta il
frame_ratedall'fpt rilevato per mantenere la temporizzazione del movimento fedele alla tua sorgente. Puoi tagliare o ripetere in post-produzione, ma esportare alla cadenza originale preserva la sensazione della performance.
Extra opzionali#
- Note di installazione per i preprocessori. I nodi di estrazione delle pose provengono dall'add-on della community. Vedi il repository per il setup e il posizionamento ONNX. ComfyUI‑WanAnimatePreprocess
- Preferisci ViTPose‑H per movimenti difficili. Passa a ViTPose‑H quando mani/piedi sono veloci o parzialmente occlusi; scarica sia il modello che il suo file dati dalle pagine collegate sopra.
- Ottimizzazione per lunghe esecuzioni. Se raggiungi i limiti di VRAM, riduci la lunghezza della finestra per passaggio o semplifica gli stack LoRA. La sovrapposizione può quindi essere aumentata leggermente per mantenere transizioni pulite.
- Forte mantenimento dell'identità. Usa un riferimento di alta qualità, frontale e dipingi un
ref_maskpreciso per proteggere il viso, i capelli o l'abbigliamento. Questo è fondamentale per sequenze One to All Animation lunghe. - Filmati puliti aiutano. Alta velocità dell'otturatore, illuminazione costante e un soggetto in primo piano chiaro miglioreranno notevolmente il tracciamento delle pose e ridurranno il tremolio nei risultati One to All Animation.
- Utility video. L'esportatore e i nodi di aiuto provengono da Video Helper Suite. Se desideri un controllo aggiuntivo sui codec o le anteprime, consulta la documentazione del progetto. Video Helper Suite
Riconoscimenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo Innovate Futures @ Benji per il tutorial sul flusso di lavoro One to All Animation e ssj9596 per il progetto One‑to‑All Animation per i loro contributi e la manutenzione. Per i dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Docs / Release Notes: Patreon post
Nota: L'uso dei modelli, dei dataset e del codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.

