






Nunchaku Qwen Image editing e compositing multi‑immagine per ComfyUI#
Nunchaku Qwen Image è un flusso di lavoro di editing e compositing multi‑immagine guidato da prompt per ComfyUI. Accetta fino a tre immagini di riferimento, ti permette di specificare come devono essere mescolate o trasformate, e produce un risultato coeso guidato da linguaggio naturale. I casi d'uso tipici includono la fusione di soggetti, la sostituzione di sfondi o il trasferimento di stili e dettagli da un'immagine all'altra.
Costruito attorno alla famiglia d'immagini Qwen, questo flusso di lavoro offre ad artisti, designer e creatori un controllo preciso rimanendo veloce e prevedibile. Include anche una rotta di modifica singola immagine e una rotta pura da testo a immagine, così puoi generare, rifinire e comporre all'interno di un'unica pipeline Nunchaku Qwen Image.
Nota: Seleziona tipi di macchine nell'intervallo da Medium a 2XLarge. L'uso di tipi di macchine 2XLarge Plus o 3XLarge non è supportato e risulterà in un fallimento dell'esecuzione.
Modelli chiave nel flusso di lavoro Comfyui Nunchaku Qwen Image#
- Nunchaku Qwen Image Edit 2509. Pesi di diffusione/DiT ottimizzati per l'editing di immagini guidato da prompt e il trasferimento di attributi. Forti in modifiche localizzate, scambi di oggetti e cambiamenti di sfondo. Model card
- Nunchaku Qwen Image (base). Generatore base utilizzato dal ramo testo-a-immagine per la sintesi creativa senza una foto di origine. Model card
- Qwen2.5‑VL 7B codificatore di testo. Modello linguistico multimodale che interpreta i prompt e li allinea con le caratteristiche visive per l'editing e la generazione. Model page
- Qwen Image VAE. Autoencoder variazionale utilizzato per codificare immagini di origine in latenze e decodificare risultati finali con colore e dettaglio fedeli. Assets
Come usare il flusso di lavoro Comfyui Nunchaku Qwen Image#
Questo grafico contiene tre rotte indipendenti che condividono lo stesso linguaggio visivo e logica di campionamento. Usa un ramo alla volta a seconda che tu stia modificando più immagini, raffinando un'unica immagine o generando da testo.
Nunchaku‑qwen‑image‑edit‑2509 (modifica e composito multi‑immagine)#
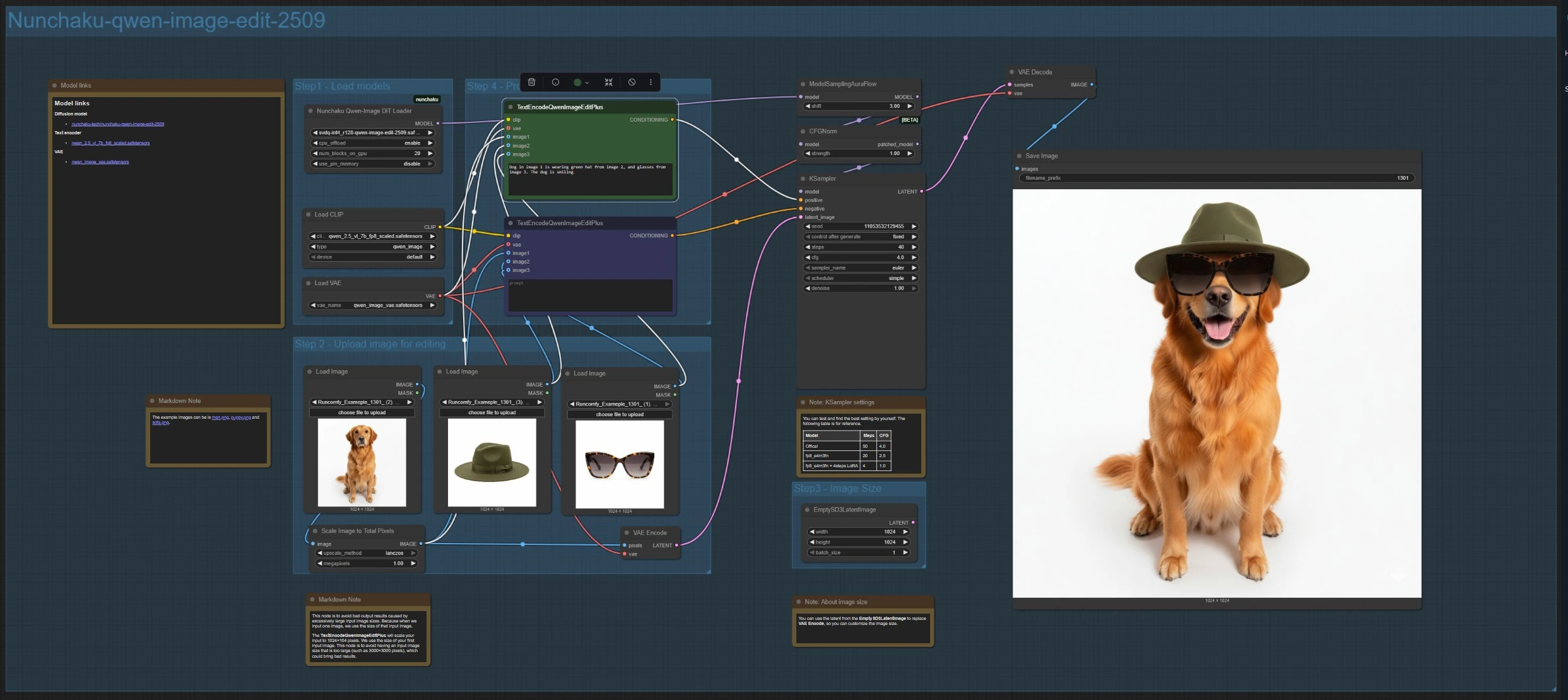
Questo ramo carica il modello di modifica con NunchakuQwenImageDiTLoader (#115), lo instrada attraverso ModelSamplingAuraFlow (#66) e CFGNorm (#75), quindi sintetizza con KSampler (#3). Carica fino a tre immagini usando LoadImage (#78, #106, #108). Il riferimento principale è codificato da VAEEncode (#88) per impostare la tela, e ImageScaleToTotalPixels (#93) mantiene gli input entro un intervallo di dimensioni stabile.
Scrivi la tua istruzione in TextEncodeQwenImageEditPlus (#111) e, se necessario, inserisci rimozioni o vincoli nel TextEncodeQwenImageEditPlus associato (#110). Fai riferimento esplicito alle fonti, ad esempio: “Il cane nell'immagine 1 indossa il cappello verde dell'immagine 2 e gli occhiali dell'immagine 3.” Per dimensioni di output personalizzate, puoi sostituire la latenza codificata con EmptySD3LatentImage (#112). I risultati sono decodificati da VAEDecode (#8) e salvati con SaveImage (#60).
Nunchaku‑qwen‑image‑edit (raffinamento immagine singola)#
Scegli questo quando desideri pulizie mirate, cambiamenti di sfondo o regolazioni di stile su un'immagine. Il modello è caricato da NunchakuQwenImageDiTLoader (#120), adattato da ModelSamplingAuraFlow (#125) e CFGNorm (#123), e campionato da KSampler (#127). Importa la tua foto con LoadImage (#129); è normalizzata da ImageScaleToTotalPixels (#130) e codificata da VAEEncode (#131).
Fornisci la tua istruzione in TextEncodeQwenImageEdit (#121) e una guida negativa opzionale in TextEncodeQwenImageEdit (#122) per mantenere o rimuovere elementi. Il ramo decodifica con VAEDecode (#124) e scrive i file tramite SaveImage (#128).
Nunchaku‑qwen‑image (da testo a immagine)#
Usa questo ramo per creare nuove immagini da zero con il modello base. NunchakuQwenImageDiTLoader (#146) alimenta ModelSamplingAuraFlow (#138). Inserisci i tuoi prompt positivi e negativi in CLIPTextEncode (#143) e CLIPTextEncode (#137). Imposta la tua tela con EmptySD3LatentImage (#136), quindi genera con KSampler (#141), decodifica usando VAEDecode (#142), e salva con SaveImage (#147).
Nodi chiave nel flusso di lavoro Comfyui Nunchaku Qwen Image#
NunchakuQwenImageDiTLoader (#115) Carica i pesi dell'immagine Qwen e la variante utilizzata dal ramo. Seleziona il modello di modifica per modifiche guidate da foto o il modello base per da testo a immagine. Quando il VRAM lo consente, varianti ad alta precisione o risoluzione possono offrire più dettagli; varianti più leggere danno priorità alla velocità.
TextEncodeQwenImageEditPlus (#111) Guida le modifiche multi‑immagine interpretando la tua istruzione e legandola fino a tre riferimenti. Mantieni le direttive esplicite su quale immagine contribuisce con quale attributo. Usa una frase concisa ed evita obiettivi conflittuali per mantenere le modifiche focalizzate.
TextEncodeQwenImageEditPlus (#110) Agisce come codificatore negativo o di vincolo associato per il ramo multi‑immagine. Usalo per escludere oggetti, stili o artefatti che non vuoi che appaiano. Questo spesso aiuta a preservare la composizione rimuovendo sovrapposizioni UI o oggetti indesiderati.
TextEncodeQwenImageEdit (#121) Istruzione positiva per il ramo di modifica immagine singola. Descrivi il risultato desiderato, le qualità superficiali e la composizione in termini chiari. Mira a una o tre frasi che specificano la scena e i cambiamenti.
TextEncodeQwenImageEdit (#122) Prompt negativo o di vincolo per il ramo di modifica immagine singola. Elenca elementi o tratti da evitare, o descrivi elementi da rimuovere dall'immagine di origine. Questo è utile per pulire testo superfluo, loghi o elementi dell'interfaccia.
ImageScaleToTotalPixels (#93) Previene che input troppo grandi destabilizzino i risultati scalando a un conteggio totale di pixel target. Usalo per armonizzare risoluzioni di origine disparate prima del composito. Se noti nitidezza incoerente tra le fonti, avvicinale in dimensione effettiva qui.
ModelSamplingAuraFlow (#66) Applica un programma di campionamento DiT/flow‑matching ottimizzato per i modelli d'immagine Qwen. Se gli output appaiono scuri, confusi o privi di struttura, aumenta lo spostamento del programma per stabilizzare il tono globale; se appaiono piatti, riduci lo spostamento per inseguire dettagli extra.
KSampler (#3) Il campionatore principale dove bilanci velocità, fedeltà e varietà stocastica. Regola i passaggi e la scala di guida per coerenza rispetto alla creatività, scegli un metodo di campionamento e blocca un seme quando vuoi riproducibilità esatta tra le esecuzioni.
CFGNorm (#75) Normalizza la guida libera da classificatori per ridurre la sovrasaturazione o gli scoppi di contrasto a scale di guida più alte. Lascialo nel percorso come fornito; aiuta a mantenere il colore e l'esposizione stabili mentre iteri sui prompt.
Extra opzionali#
- Per risultati multi‑immagine migliori, scegli fonti con prospettiva e illuminazione simili; il modello di modifica Nunchaku Qwen Image si concentra quindi sul contenuto piuttosto che sulla correzione della geometria.
- Fai riferimento alle fonti per ordine (“immagine 1”, “immagine 2”, “immagine 3”) ed esplicita quale attributo trasferire dove.
- Quando gli output tendono a essere scuri o sfocati, sposta leggermente verso l'alto lo spostamento del
ModelSamplingAuraFlow; quando vuoi una texture extra, prova uno spostamento leggermente inferiore. - Per impostare una risoluzione specifica, sostituisci la latenza codificata con
EmptySD3LatentImagenel ramo che stai usando. - Usa prompt negativi per rimuovere testo UI, filigrane o oggetti indesiderati prima di investire in uno stile dettagliato; questo mantiene le modifiche Nunchaku Qwen Image pulite dall'inizio.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo Nunchaku per il flusso di lavoro Qwen-Image (ComfyUI-nunchaku) per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
Nota: L'uso dei modelli, dataset e codice referenziati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.




