
LTX 2.3 Dual Character Lip Sync LoRA: video lip-sync a due personaggi da un'immagine e una traccia audio#
Questo workflow ComfyUI trasforma un'unica immagine statica e una conversazione registrata a due voci in un video coerente e stabile nell'identità con discorso sincronizzato per entrambi i personaggi a schermo. Basato sulla spina dorsale video LTX‑2.3 e sul LTX 2.3 Dual Character Lip Sync LoRA, mappa i fonemi e la tempistica dal tuo dialogo a ciascun volto preservando espressioni, sguardo e coerenza della scena tra i fotogrammi.
Progettato per interviste, dialoghi cinematografici, podcast con ospiti video e interazioni con personaggi virtuali, il workflow abbina suggerimenti di testo per l'impostazione della scena con movimento guidato dall'audio. Include una fase di bootstrap dell'immagine per uno sviluppo rapido dell'aspetto, campionamento LTX a due fasi per stabilità temporale e un upscaler latente per risultati nitidi. L'output finale è un MP4 con audio incorporato.
Modelli chiave nel workflow ComfyUI LTX 2.3 Dual Character Lip Sync LoRA#
- Modello di generazione video LTX‑2.3. Fornisce la spina dorsale di diffusione multimodale che sintetizza video coerenti nel tempo condizionati su testo, immagine e audio. Lightricks/LTX-2.3
- LTX‑2.3 Video VAE e Audio VAE. Codifica e decodifica latenze video e audio utilizzate dal modello per mantenere la generazione efficiente e sincronizzata. Fornito con il rilascio LTX‑2.3. Lightricks/LTX-2.3
- LTX spatial latent upscaler. Raffina i dettagli dopo il passaggio di base aumentando la risoluzione nello spazio latente per texture e bordi più puliti. Varianti disponibili insieme agli asset LTX. Lightricks/LTX-2
- LTX 2.3 Dual Character Lip Sync LoRA. Inietta un addestramento che incoraggia il movimento della bocca e la tempistica per due volti nello stesso scatto mantenendo l'identità facciale.
- Modello di testo-immagine Z‑Image Turbo. Produce rapidamente un riferimento fermo di alta qualità che ancora identità, inquadratura e illuminazione prima della sintesi video. Comfy‑Org/z_image_turbo
Pacchetti di nodi correlati utilizzati da questo workflow: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, e ComfyUI‑PromptRelay.
Come usare il workflow ComfyUI LTX 2.3 Dual Character Lip Sync LoRA#
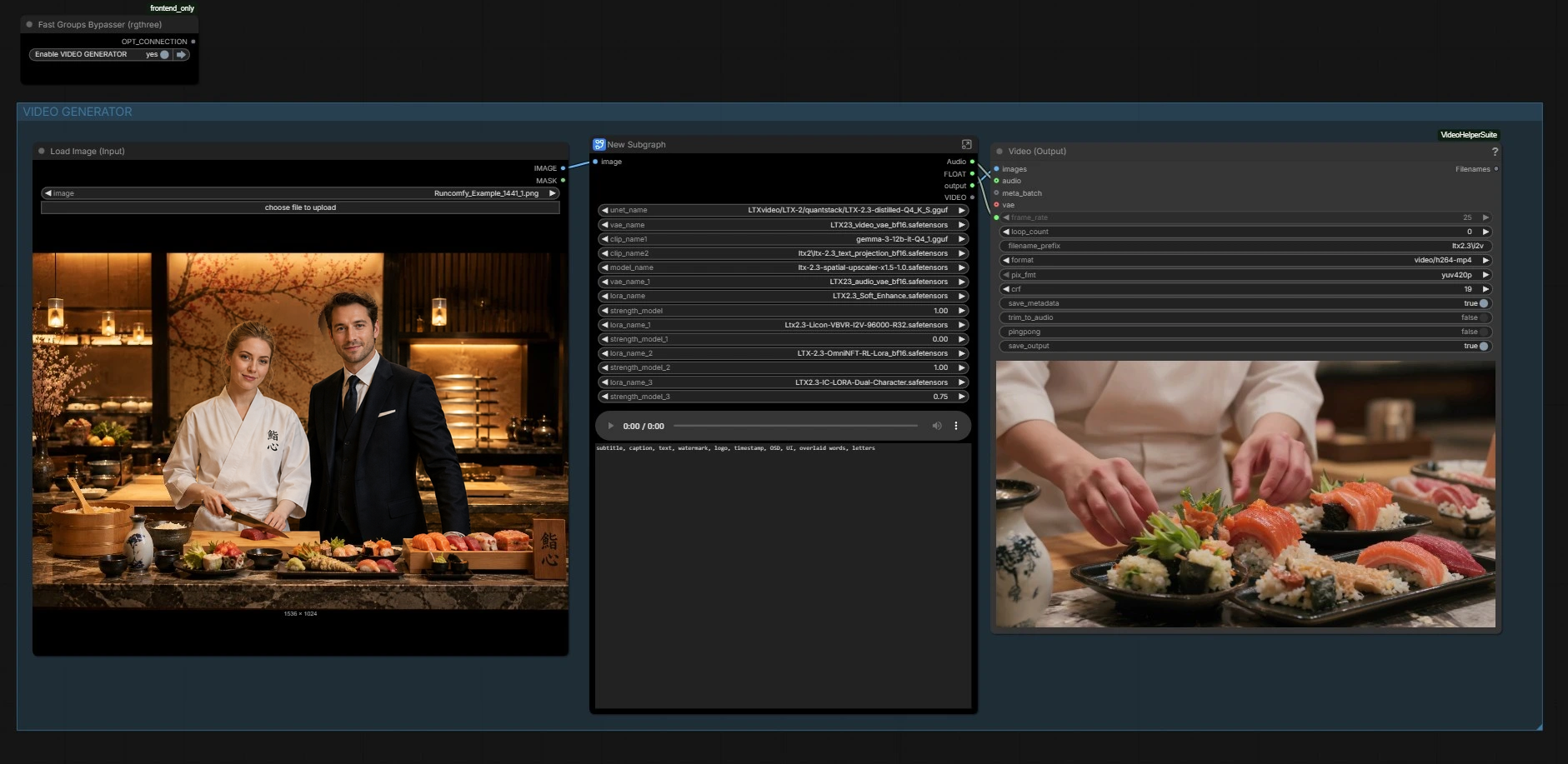
Il workflow ha due parti coordinate: un generatore di immagini che crea il fotogramma principale e un generatore di video che guida il movimento e la sincronizzazione labiale dall'audio preservando l'aspetto. Usa i gruppi sottostanti come guida.
GENERATORE DI IMMAGINI#
Questa sezione costruisce l'immagine ancora. Usa i preset di scena nella lista dei prompt per redigere rapidamente composizioni, poi affina il testo con descrizioni dei personaggi per entrambi. Una pila di diffusione delle immagini compatta (sottografo "Z IMG TURBO") codifica il tuo prompt e campiona un riferimento fermo pulito. L'immagine viene decodificata e salvata per l'ispezione, quindi passata avanti per seminare identità e layout per il video.
Input chiave che tocchi qui: il prompt descrittivo per la scena, il guardaroba e due personaggi distinti; evita gergo di lenti o rendering che contrastano il realismo a meno che quell'aspetto non sia intenzionale.
Modelli#
Qui il grafico carica la spina dorsale LTX‑2.3, i suoi VAE video e audio, gli encoder di testo e l'upscaler latente. Applica anche il LTX 2.3 Dual Character Lip Sync LoRA, oltre a eventuali LoRA di stile o miglioramento opzionali se le abiliti. Questo è il punto in cui le capacità del modello base sono combinate con il comportamento di sincronizzazione labiale a due voci del LoRA per guidare il movimento della bocca senza sacrificare l'identità. Nessuna azione è necessaria a meno che tu non voglia scambiare pesi o regolare l'influenza del LoRA.
AUDIO PERSONALIZZATO#
Fornisci qui la tua traccia di conversazione. Il file audio viene caricato e codificato in un latente audio che porta tempistica e indizi fonetici attraverso la pipeline. Se non fornisci audio, il workflow può generare movimento usando un latente audio vuoto, ma il LTX 2.3 Dual Character Lip Sync LoRA è progettato per brillare con dialoghi reali. Usa un mix a due voci pulito con turni chiari per la migliore separazione dei movimenti della bocca.
PARAMETRI VIDEO#
Imposta la durata e il frame rate di destinazione. Questi valori sono memorizzati e riutilizzati durante il campionamento, la pianificazione, le guide di ritaglio e il rendering finale in modo che le labbra, i battiti di ciglia e la tempistica delle riprese rimangano allineati. Mantieni la lunghezza del video coerente con l'audio fornito per evitare un eccesso di inizio o fine.
GENERAZIONE LATENTE#
La tua immagine selezionata viene preprocessata e le sue dimensioni vengono rilevate. Il workflow crea un latente video della lunghezza giusta, poi inserisce l'immagine al suo posto in modo che il primo fotogramma corrisponda al tuo design. Viene applicata una maschera di rumore a tutto fotogramma per controllare quanto il background può evolversi rispetto ai volti. Il latente audio preparato viene quindi abbinato al latente video in modo che entrambe le modalità siano pronte per il condizionamento.
Nodi notevoli: LTXVPreprocess scala la tua immagine per LTX, EmptyLTXVLatentVideo costruisce la timeline, e LTXVImgToVideoInplaceKJ (#5881) blocca l'identità seminando il primo fotogramma dall'immagine.
Condizionamento#
I prompt testuali sono codificati e collegati come condizioni positive e negative. Usa la casella globale dei prompt per descrivere la messa in scena e l'intento in linguaggio naturale; puoi includere una breve lista di riprese se utile. Un encoder di testo negativo dedicato sopprime sottotitoli, filigrane e UI sul fotogramma in modo che i volti rimangano puliti. Le guide di ritaglio analizzano il latente per concentrare l'attenzione su entrambi i volti, migliorando il tracciamento delle espressioni per oratore con il LTX 2.3 Dual Character Lip Sync LoRA attivo.
Componenti rappresentativi: PromptRelayEncode (#5903) fonde la tua descrizione della scena con il contesto latente, e LTXVConditioning collega una guida consapevole del frame rate per entrambe le modalità.
1° Campionamento#
Il primo passaggio di denoising genera un video base coerente nel tempo con il movimento delle labbra bloccato. Un pianificatore e un campionatore leggeri sono selezionati automaticamente, con parametri instradati dai valori di tempistica memorizzati. La variante del modello che esce da LTX2_NAG aggiunge una guida consapevole del rumore per le condizioni video e audio in modo che la tempistica del discorso rimanga ancorata mentre il contenuto si forma.
Percorso del campionatore principale: SamplerCustom (#5891) con KSamplerSelect e un pianificatore di base; regola solo se hai preferenze specifiche di campionatore.
Fase #2 Upscale e rifinitura#
La seconda fase migliora la nitidezza e le micro-espressioni. L'upscaler latente aumenta il dettaglio spaziale, i latenti audio e video sono riuniti e un campionatore di rifinitura esegue correzioni sottili preservando il movimento stabilito. Successivamente i latenti sono separati e decodificati nuovamente in una sequenza di immagini e una forma d'onda audio.
Blocchi importanti: LTXVLatentUpsampler (#5927) per chiarezza, SamplerCustomAdvanced (#5929) per il passaggio di rifinitura, seguito da VAEDecode e LTXVAudioVAEDecode per tornare allo spazio pixel e audio.
Output#
Infine, i fotogrammi e l'audio sono confezionati in un MP4 per la riproduzione e la revisione. Il frame rate usato per il condizionamento è riutilizzato qui in modo che la cadenza visiva e la tempistica fonetica corrispondano a ciò che il modello ha visto durante la generazione. Puoi anche visualizzare in anteprima l'audio a metà grafico se hai bisogno di un rapido controllo.
Percorso di output: CreateVideo (#5931) costruisce il clip; un percorso ausiliario VHS_VideoCombine (#5905) è fornito per esportazioni alternative con controlli dei metadati.
Nodi chiave nel workflow ComfyUI LTX 2.3 Dual Character Lip Sync LoRA#
LTXICLoRALoaderModelOnly(#5958) Carica il LTX 2.3 Dual Character Lip Sync LoRA nella spina dorsale LTX‑2.3. Aumentastrength_modelquando hai bisogno di un'articolazione più stretta della bocca e separazione degli oratori; abbassalo quando vuoi che il movimento e lo stile del modello base dominino, specialmente se accumuli ulteriori LoRA di stile.PromptRelayEncode(#5903) Luogo centrale per scrivere la descrizione della scena e, facoltativamente, un breve piano di riprese. Fonde il prompt globale con il contesto del modello e il latente corrente in modo che la guida rimanga coerente lungo la timeline. Mantieni il linguaggio chiaro e descrivi distintamente entrambi i personaggi per aiutare l'identità e la separazione dei ruoli.LTXVImgToVideoInplaceKJ(#5881) Semina il primo fotogramma del latente video direttamente dalla tua immagine generata o caricata. Questo blocca l'identità, il guardaroba e l'illuminazione, riducendo la deriva nel tempo. Usa un'inquadratura media o medio-ampia con entrambi i volti non ostruiti per i migliori risultati.LTXVAudioVAEEncode(#5851) Converte la traccia di dialogo fornita in un latente audio che il modello può usare per la tempistica dei fonemi. Fornisci un mix pulito senza compressione pesante; assicurati che il tempo di inizio corrisponda al primo discorso a schermo per evitare un movimento delle labbra fuori sincrono.SamplerCustom(#5891) eSamplerCustomAdvanced(#5929) Due fasi di denoising complementari. Mantieni le famiglie di campionatori coerenti tra le fasi per mantenere la continuità del movimento ed evita cambiamenti drastici nella pianificazione del rumore una volta che hai un aspetto che ti piace.LTXVLatentUpsampler(#5927) Applica l'upscaler latente LTX prima della rifinitura per aggiungere nitidezza senza destabilizzare il movimento stabilito. Scegli una variante di upscaler appropriata per la tua risoluzione di destinazione e il realismo delle texture.
Extra opzionali#
- Usa un WAV a due oratori a 24 kHz con rumore di fondo minimo; aggiungi brevi pause naturali tra le battute per aiutare il LTX 2.3 Dual Character Lip Sync LoRA a separare i turni.
- Genera o fornisci un'immagine in cui entrambi i soggetti sono visibili, rivolti generalmente verso la telecamera, con illuminazione coerente sui volti.
- Mantieni il prompt di testo negativo che esclude "sottotitoli, didascalia, logo, timestamp" per evitare elementi UI bruciati durante il campionamento.
- Inizia con un breve clip per convalidare la tempistica, poi estendi la durata o aumenta la risoluzione una volta che ti piace il comportamento.
- Se aggiungi LoRA di stile, bilanciali contro il LTX 2.3 Dual Character Lip Sync LoRA in modo che l'articolazione rimanga accurata mentre la scena mantiene l'estetica scelta.
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo con gratitudine i creatori di "LTX 2.3 Dual Character Lip Sync LoRA Workflow Source" per il workflow. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- LTX 2.3 Dual Character Lip Sync LoRA Workflow Source/LTX 2.3 Dual Character Lip Sync LoRA Workflow Source
- Documenti / Note di rilascio: Video di YouTube
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.