
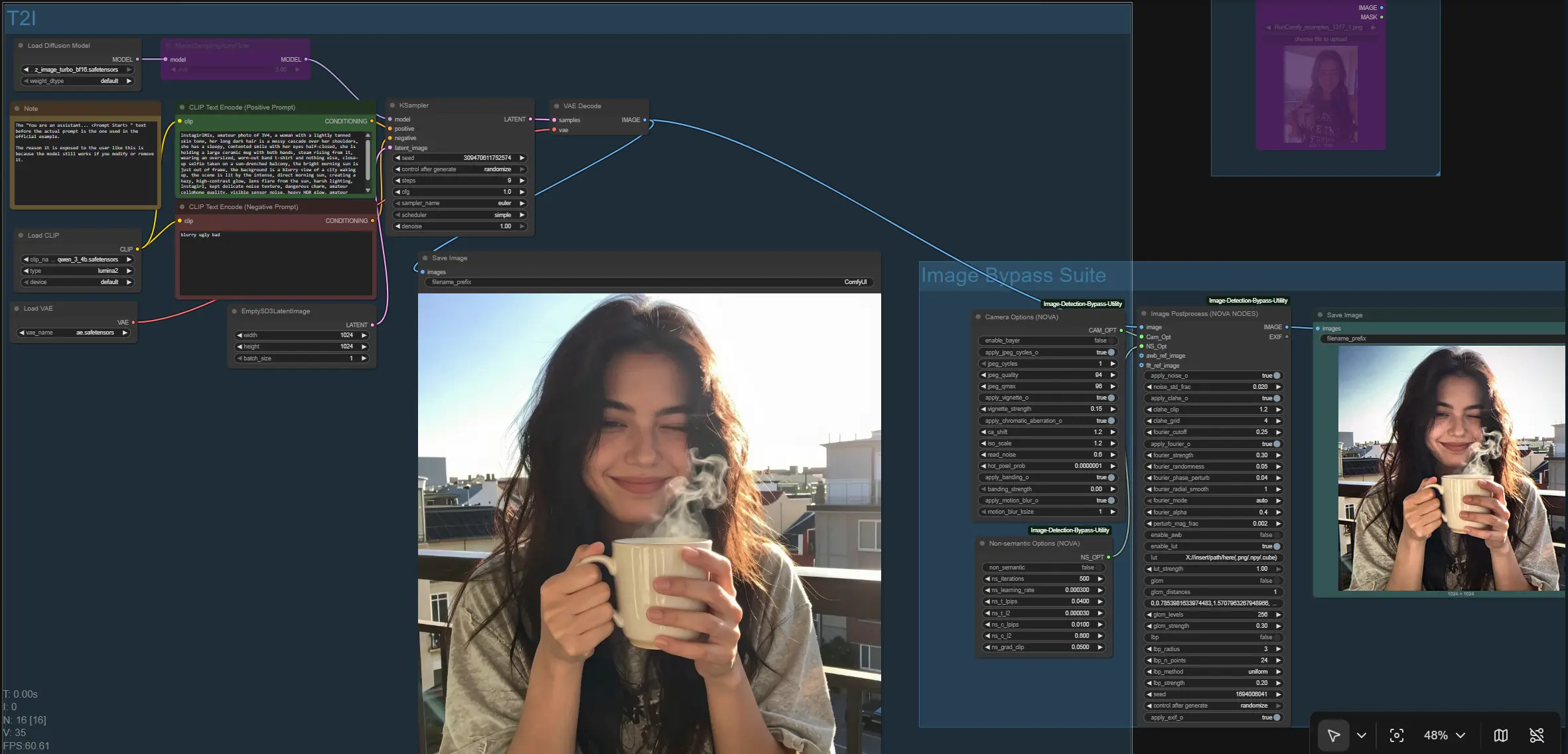







Flusso di Lavoro Image Bypass di ComfyUI#
Questo flusso di lavoro offre una pipeline modulare Image Bypass per ComfyUI che combina normalizzazione non semantica, controlli del dominio FFT e simulazione della pipeline della fotocamera. È progettato per creatori e ricercatori che necessitano di un modo affidabile per elaborare immagini attraverso una fase di Image Bypass mantenendo il pieno controllo sull'instradamento degli input, il comportamento di pre-elaborazione e la coerenza degli output.
Al suo centro, il grafo genera o acquisisce un'immagine, quindi la instrada attraverso una Suite di Image Bypass che può applicare artefatti simili a sensori, modellatura della frequenza, abbinamento delle texture e un ottimizzatore percettivo. Il risultato è un percorso pulito e configurabile che si adatta al lavoro in batch, all'automazione e alla rapida iterazione su GPU consumer. La logica Image Bypass è alimentata dall'utility open source di questo repository: PurinNyova/Image-Detection-Bypass-Utility.
Modelli chiave nel flusso di lavoro Image Bypass di ComfyUI#
- z_image_turbo_bf16 (checkpoint UNet). Un backbone di diffusione testuale-immagine veloce utilizzato nel ramo T2I per prototipi rapidi e generazione di immagini di riferimento. È sostituibile con il tuo checkpoint preferito. Riferimento: Comfy-Org/z_image_turbo su Hugging Face.
- VAE (ae.safetensors). Gestisce la decodifica latente ai pixel in modo che l'output del campionamento possa essere visualizzato e ulteriormente elaborato dalla fase Image Bypass. Qualsiasi VAE compatibile può essere sostituito se preferisci un profilo di ricostruzione diverso.
- Codificatore di prompt (caricato tramite CLIPLoader). Codifica i tuoi prompt positivi e negativi in vettori di condizionamento per il sampler. Il grafo è agnostico rispetto al file specifico del codificatore testuale che carichi, quindi puoi sostituire i modelli come necessario per il tuo generatore base.
Come utilizzare il flusso di lavoro Image Bypass di ComfyUI#
A un livello alto, il flusso di lavoro offre due modi per produrre l'immagine che entra nella Suite di Image Bypass: un ramo Testo-a-Immagine (T2I) e un ramo Immagine-a-Immagine (I2I). Entrambi convergono su un singolo nodo di elaborazione che applica la logica Image Bypass e scrive il risultato finale su disco. Il grafo salva anche il baseline pre-bypass in modo da poter confrontare gli output.
Gruppo: T2I#
Usa questo percorso quando vuoi sintetizzare una nuova immagine dai prompt. Il tuo codificatore di prompt è caricato da CLIPLoader (#164) e letto da CLIP Text Encode (Positive Prompt) (#168) e CLIP Text Encode (Negative Prompt) (#163). L'UNet è caricato con UNETLoader (#165), eventualmente modificato da ModelSamplingAuraFlow (#166) per regolare il comportamento di campionamento del modello, e quindi campionato con KSampler (#167) a partire da EmptySD3LatentImage (#162). L'immagine decodificata esce da VAEDecode (#158) ed è salvata come baseline tramite SaveImage (#159) prima di entrare nella Suite di Image Bypass. Per questo ramo, i tuoi input principali sono i prompt positivi/negativi e, se desiderato, la strategia del seme in KSampler (#167).
Gruppo: I2I#
Scegli questo percorso quando hai già un'immagine da elaborare. Caricala tramite LoadImage (#157) e instrada l'output IMAGE all'input della Suite di Image Bypass su NovaNodes (#146). Questo bypassa completamente il condizionamento testuale e il campionamento. È ideale per il post-processamento in batch, esperimenti su dataset esistenti o standardizzazione degli output da altri flussi di lavoro. Puoi passare liberamente tra T2I e I2I a seconda che tu voglia generare o trasformare strettamente.
Gruppo: Suite di Image Bypass#
Questo è il cuore del grafo. Il processore centrale NovaNodes (#146) riceve l'immagine in ingresso e due blocchi di opzioni: CameraOptionsNode (#145) e NSOptionsNode (#144). Il nodo può operare in modalità automatica semplificata o in modalità manuale che espone controlli per la modellatura della frequenza (levigatura/abbinamento FFT), perturbazioni di pixel e fase, gestione del contrasto locale e del tono, LUT 3D opzionali e regolazione delle statistiche di texture. Due input opzionali ti permettono di inserire un riferimento di bilanciamento del bianco automatico e un'immagine di riferimento FFT/texture per guidare la normalizzazione. Il risultato finale di Image Bypass è scritto da SaveImage (#147), dandoti sia il baseline che l'output elaborato per la valutazione affiancata.
Nodi chiave nel flusso di lavoro Image Bypass di ComfyUI#
NovaNodes (#146)#
Il processore principale di Image Bypass. Orquestra la modellatura nel dominio della frequenza, perturbazioni spaziali, controllo del tono locale, applicazione LUT e normalizzazione opzionale delle texture. Se fornisci un awb_ref_image o un fft_ref_image, utilizzerà questi riferimenti all'inizio della pipeline per guidare la corrispondenza del colore e spettrale. Inizia in modalità automatica per ottenere un baseline sensato, quindi passa a manuale per affinare la forza dell'effetto e fondere per il tuo contenuto e le attività a valle. Per confronti coerenti, imposta e riutilizza un seme; per l'esplorazione, randomizza per diversificare le micro-variazioni.
NSOptionsNode (#144)#
Controlla l'ottimizzatore non semantico che spinge i pixel mantenendo la somiglianza percettiva. Espone il conteggio delle iterazioni, il tasso di apprendimento, e i pesi di percezione/regolarizzazione (LPIPS e L2) insieme al clipping del gradiente. Usalo quando hai bisogno di spostamenti sottili di distribuzione con artefatti visibili minimi; mantieni i cambiamenti conservativi per mantenere texture ed edge naturali. Disattivalo completamente per misurare quanto la pipeline Image Bypass aiuta senza un ottimizzatore.
CameraOptionsNode (#145)#
Simula caratteristiche del sensore e dell'obiettivo come demosaicizzazione e cicli JPEG, vignettatura, aberrazione cromatica, sfocatura da movimento, banding e rumore di lettura. Trattalo come uno strato di realismo che può aggiungere artefatti di acquisizione plausibili alle tue immagini. Abilita solo i componenti che corrispondono alle tue condizioni di cattura target; impilare troppi può sovra-constringere l'aspetto. Per output riproducibili, mantieni le stesse opzioni di fotocamera variando altri parametri.
ModelSamplingAuraFlow (#166)#
Modifica il comportamento di campionamento del modello caricato prima che raggiunga KSampler (#167). Questo è utile quando il tuo backbone scelto beneficia di una traiettoria di passo alternativa. Regolalo quando noti una discrepanza tra l'intento del prompt e la struttura del campione, e trattalo in tandem con le tue scelte di sampler e scheduler.
KSampler (#167)#
Esegue il campionamento di diffusione dato il modello, il condizionamento positivo e negativo, e il latente iniziale. Le leve chiave sono la strategia del seme, i passi, il tipo di sampler e la forza complessiva di denoise. Passi più bassi aiutano la velocità, mentre passi più alti possono stabilizzare la struttura se il tuo modello base lo richiede. Mantieni stabile il comportamento di questo nodo mentre iteri sulle impostazioni di Image Bypass in modo da poter attribuire i cambiamenti alla post-elaborazione piuttosto che al generatore.
Extra opzionali#
- Scambia modelli liberamente. La Suite di Image Bypass è agnostica al modello; puoi sostituire
z_image_turbo_bf16e continuare a instradare i risultati attraverso lo stesso stack di elaborazione. - Usa i riferimenti con attenzione. Fornisci
awb_ref_imageefft_ref_imageche condividono caratteristiche di illuminazione e contenuto con il tuo dominio target; riferimenti non corrispondenti possono ridurre il realismo. - Confronta equamente. Mantieni
SaveImage(#159) come baseline eSaveImage(#147) come output di Image Bypass in modo da poter testare A/B le impostazioni e tracciare i miglioramenti. - Esegui batch con cura. Aumenta la dimensione del batch di
EmptySD3LatentImage(#162) solo come consente VRAM e preferisci semi fissi quando misuri piccoli cambiamenti di parametro. - Impara l'utility. Per dettagli sulle funzionalità e aggiornamenti in corso sui componenti di Image Bypass, consulta il progetto upstream: PurinNyova/Image-Detection-Bypass-Utility.
Crediti#
- ComfyUI, il motore del grafo utilizzato da questo flusso di lavoro: comfyanonymous/ComfyUI.
- Esempio di checkpoint base: Comfy-Org/z_image_turbo.
Ringraziamenti#
Questo flusso di lavoro implementa e si basa sui seguenti lavori e risorse. Ringraziamo calorosamente PurinNyova per Image-Detection-Bypass-Utility per i loro contributi e la manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- PurinNyova/Image-Detection-Bypass-Utility
- GitHub: PurinNyova/Image-Detection-Bypass-Utility
- Documenti / Note di Rilascio: Repository (tree/main)
Nota: L'uso dei modelli, dataset e codice di riferimento è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.