
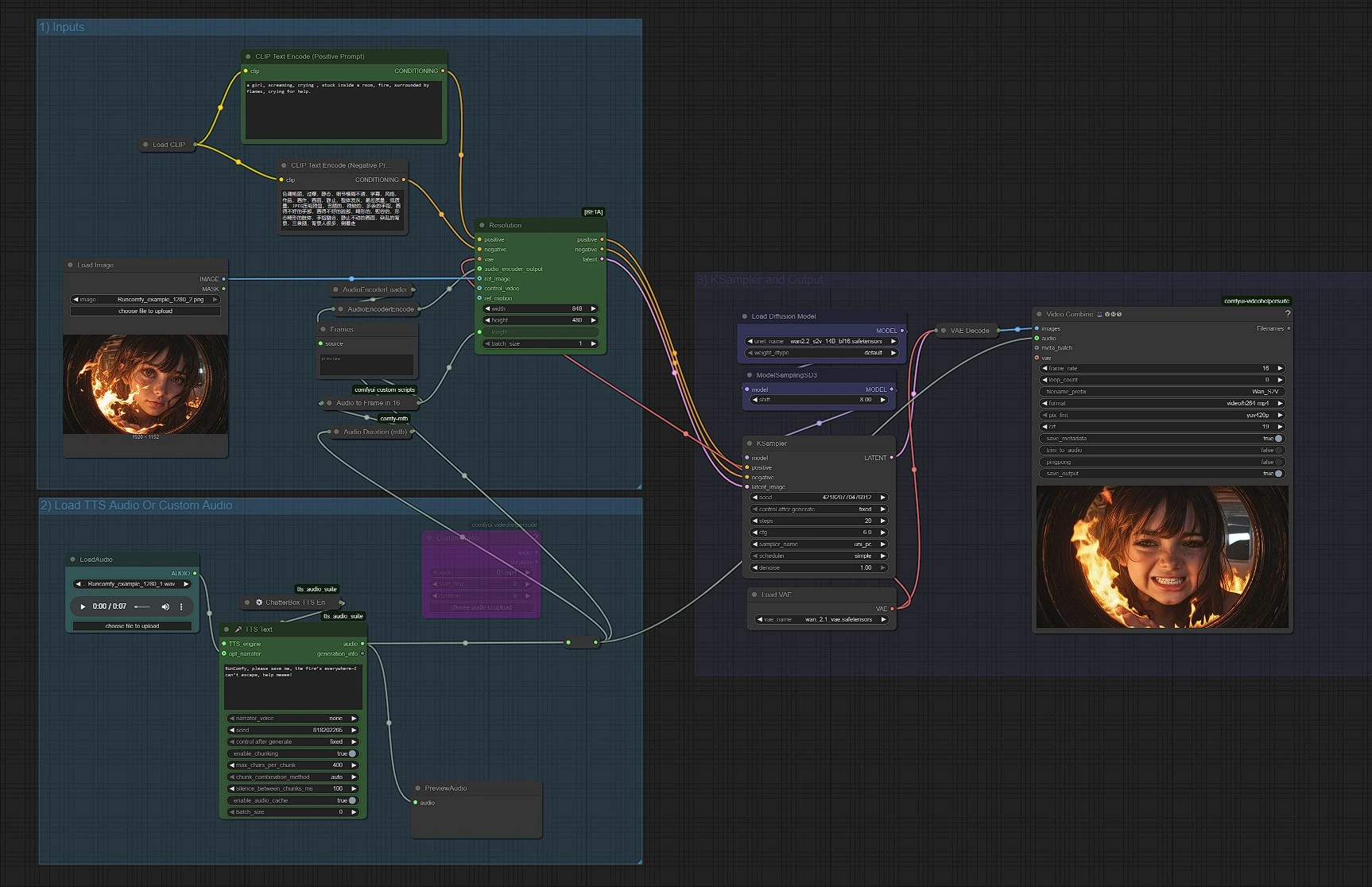
Wan2.2 S2V : Son-à-Vidéo à partir d'une Seule Image dans ComfyUI#
Wan2.2 S2V est un workflow de son-à-vidéo qui transforme une image de référence plus un extrait audio en une vidéo synchronisée. Il est construit autour de la famille de modèles Wan 2.2 et conçu pour les créateurs qui souhaitent un mouvement expressif, une synchronisation labiale et une dynamique de scène qui suivent le son ou la parole. Utilisez Wan2.2 S2V pour des avatars parlants, des boucles musicales et des séquences rapides sans animation manuelle.
Ce graphe ComfyUI couple les caractéristiques audio avec des invites textuelles et une image fixe pour générer un court clip, puis combine les images avec l'audio original. Le résultat est un pipeline compact et fiable qui conserve l'apparence de votre image de référence tout en permettant à l'audio de régir le timing et l'expression.
Modèles clés dans le workflow Comfyui Wan2.2 S2V#
- Wan 2.2 S2V UNet (14B, bf16). Le générateur principal qui fusionne les caractéristiques audio, le conditionnement textuel et une image de référence pour produire des latents vidéo.
- Wan VAE (wan_2.1_vae). Encode/décode entre l'espace latent et l'espace pixel pour préserver les détails et la fidélité des couleurs dans les rendus Wan2.2 S2V.
- Encodeur de texte UMT5-XXL. Fournit un conditionnement par invite pour le style et le contenu ; voir la carte modèle de base pour référence : google/umt5-xxl.
- Encodeur audio Wav2Vec2 Large. Extrait des caractéristiques robustes de parole et de rythme pour la génération conditionnée par le son ; voir une carte archétypale telle que facebook/wav2vec2-large-960h.
Comment utiliser le workflow Comfyui Wan2.2 S2V#
Le workflow est organisé en trois groupes. Vous pouvez les exécuter de bout en bout ou ajuster chaque étape selon vos besoins.
1) Entrées#
Ce groupe charge les composants textuels, d'image et VAE de Wan, et prépare vos invites. Utilisez CLIPLoader (#38) avec CLIPTextEncode (#6) pour l'invite positive et CLIPTextEncode (#7) pour l'invite négative afin de guider le style et la qualité. Chargez votre image de référence avec LoadImage (#52) ; cela ancre l'identité, le cadrage et la palette pour Wan2.2 S2V. Gardez les invites positives descriptives mais concises pour que l'audio conserve le contrôle du mouvement. Le VAE (VAELoader (#39)) et le chargeur de modèle (UNETLoader (#37)) sont pré-câblés et généralement laissés tels quels.
2) Charger l'Audio TTS ou Audio Personnalisé#
Choisissez comment vous fournissez l'audio. Pour des tests rapides, générez la parole avec UnifiedTTSTextNode (#71) et prévisualisez avec PreviewAudio (#65). Pour utiliser votre propre musique ou dialogue, soit LoadAudio (#78) pour les fichiers locaux soit VHS_LoadAudioUpload (#87) pour les téléchargements ; les deux alimentent un Reroute (#88) pour que les nœuds en aval voient une seule source audio. La durée est mesurée par Audio Duration (mtb) (#68), puis convertie en nombre d'images par MathExpression|pysssss (#67) étiquetée "Audio to Frame in 16 FPS". Les caractéristiques audio sont produites par AudioEncoderLoader (#57) et AudioEncoderEncode (#56), qui ensemble fournissent au nœud Wan2.2 S2V une AUDIO_ENCODER_OUTPUT.
3) KSampler et Sortie#
WanSoundImageToVideo (#55) est le cœur de Wan2.2 S2V. Il consomme vos invites, VAE, caractéristiques audio, image de référence, et un entier length (images) pour émettre une séquence latente conditionnée. Cette latente va à KSampler (#3), dont les paramètres de l'échantillonneur régissent la cohérence et le détail globaux tout en respectant le timing dicté par l'audio. La latente échantillonnée est décodée par VAEDecode (#8) en images, puis VHS_VideoCombine (#66) assemble la vidéo et combine votre audio original pour produire un MP4. ModelSamplingSD3 (#54) est utilisé pour définir la bonne famille d'échantillonneurs pour l'ossature Wan.
Nœuds clés dans le workflow Comfyui Wan2.2 S2V#
WanSoundImageToVideo (#55)#
Conduit le mouvement synchronisé à l'audio à partir d'une seule image. Définissez ref_image sur le portrait ou la scène que vous souhaitez animer, connectez audio_encoder_output de l'encodeur, et fournissez une length en images. Augmentez length pour des clips plus longs ou réduisez pour des aperçus plus rapides. Si vous changez FPS ailleurs, mettez à jour la valeur des images en conséquence pour que le timing reste synchronisé.
AudioEncoderLoader (#57) et AudioEncoderEncode (#56)#
Chargez et exécutez l'encodeur basé sur Wav2Vec2 qui transforme la parole ou la musique en caractéristiques que Wan peut suivre. Utilisez une parole claire pour la synchronisation labiale, ou un audio percussif/rythmé pour un mouvement rythmique. Si votre langue ou domaine d'entrée diffère, remplacez-le par un point de contrôle Wav2Vec2 compatible pour améliorer l'alignement.
CLIPTextEncode (#6) et CLIPTextEncode (#7)#
Encodeurs d'invites positives et négatives pour le conditionnement UMT5/CLIP. Gardez les invites positives concises, en se concentrant sur le sujet, le style et les termes de prise de vue ; utilisez des invites négatives pour éviter les artefacts indésirables. Des invites trop forcées peuvent lutter contre l'audio, alors préférez une légère orientation et laissez Wan2.2 S2V gérer le mouvement.
KSampler (#3)#
Échantillonne la séquence latente produite par le nœud Wan2.2 S2V. Ajustez le type et les étapes de l'échantillonneur pour échanger la vitesse contre la fidélité ; gardez une graine fixe lorsque vous voulez un timing reproductible avec le même audio. Si le mouvement semble trop rigide ou bruyant, de petits changements ici peuvent améliorer sensiblement la stabilité temporelle.
VHS_VideoCombine (#66)#
Crée la vidéo finale et attache l'audio. Définissez frame_rate pour correspondre à votre FPS prévu et confirmez que la longueur du clip correspond à vos length images. Le conteneur, le format pixel, et les contrôles de qualité sont exposés pour des exportations rapides ; utilisez une qualité supérieure lorsque vous prévoyez de post-traiter dans un éditeur.
Extras optionnels#
- Commencez avec une image de référence bien éclairée, de face, à votre rapport d'aspect cible pour minimiser la dérive d'identité et le recadrage.
- Pour la synchronisation labiale, gardez la bouche dégagée et utilisez une narration claire ; la musique avec des transitoires forts fonctionne bien pour un mouvement entraîné par le rythme.
- La conversion FPS par défaut suppose 16 fps ; si vous changez FPS, mettez à jour le calcul dans "Audio to Frame in 16 FPS" pour que les images s'alignent avec la durée audio.
- Utilisez l'aperçu audio et l'aperçu en direct VHS pour itérer rapidement, puis augmentez la qualité une fois que vous aimez le timing.
- Les clips plus longs augmentent le calcul et la VRAM ; réduisez le silence ou divisez les scripts longs en scènes courtes lorsque vous produisez des vidéos multi-plans avec Wan2.2 S2V.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Wan-Video pour Wan2.2 (y compris le code d'inférence S2V), Wan-AI pour Wan2.2-S2V-14B, et Gao et al. (2025) pour Wan-S2V: Audio-Driven Cinematic Video Generation pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Audio-Driven Cinematic Video Generation
- Docs / Release Notes: Wan2.2 S2V Demo
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.