
Wan2.1 Stand In : génération de vidéos cohérentes de personnages à partir d'une seule image pour ComfyUI#
Ce flux de travail transforme une image de référence en une courte vidéo où le même visage et style persistent à travers les images. Propulsé par la famille Wan 2.1 et un Stand In LoRA conçu à cet effet, il est conçu pour les conteurs, animateurs et créateurs d'avatars qui ont besoin d'une identité stable avec un minimum de configuration. Le pipeline Wan2.1 Stand In gère le nettoyage du fond, le recadrage, le masquage et l'intégration pour que vous puissiez vous concentrer sur votre prompt et le mouvement.
Utilisez le flux de travail Wan2.1 Stand In lorsque vous souhaitez une continuité d'identité fiable à partir d'une seule photo, une itération rapide et des MP4 prêts à l'exportation, plus une sortie de comparaison côte à côte en option.
Modèles clés dans le flux de travail Comfyui Wan2.1 Stand In#
- Wan 2.1 Text-to-Video 14B. Le générateur principal responsable de la cohérence temporelle et du mouvement. Il prend en charge la génération 480p et 720p et s'intègre aux LoRAs pour des comportements et styles ciblés. Model card
- Wan-VAE pour Wan 2.1. Un VAE spatio-temporel haute efficacité qui encode et décode les latents vidéo tout en préservant les indices de mouvement. Il soutient les étapes d'encodage/décodage d'image dans ce flux de travail. Voir les ressources du modèle Wan 2.1 et les notes d'intégration Diffusers pour l'utilisation du VAE. Model hub • Diffusers docs
- Stand In LoRA pour Wan 2.1. Un adaptateur de cohérence de personnage formé pour verrouiller l'identité à partir d'une seule image; dans ce graphique, il est appliqué au chargement du modèle pour garantir que le signal d'identité est fusionné à la fondation. Files
- LightX2V Step-Distill LoRA (facultatif). Un adaptateur léger qui peut améliorer le comportement de guidage et l'efficacité avec Wan 2.1 14B. Model card
- Module VACE pour Wan 2.1 (facultatif). Permet le contrôle du mouvement et de l'édition via un conditionnement conscient de la vidéo. Le flux de travail comprend un chemin d'intégration que vous pouvez activer pour le contrôle VACE. Model hub
- UMT5-XXL text encoder. Fournit un encodage de prompt multilingue robuste pour Wan 2.1 text-to-video. Model card
Comment utiliser le flux de travail Comfyui Wan2.1 Stand In#
En bref : chargez une image de référence propre et de face, le flux de travail prépare un masque et un composite axés sur le visage, l'encode dans un latent, fusionne cette identité dans les intégrations d'image Wan 2.1, puis échantillonne des images vidéo et exporte en MP4. Deux sorties sont enregistrées : le rendu principal et une comparaison côte à côte.
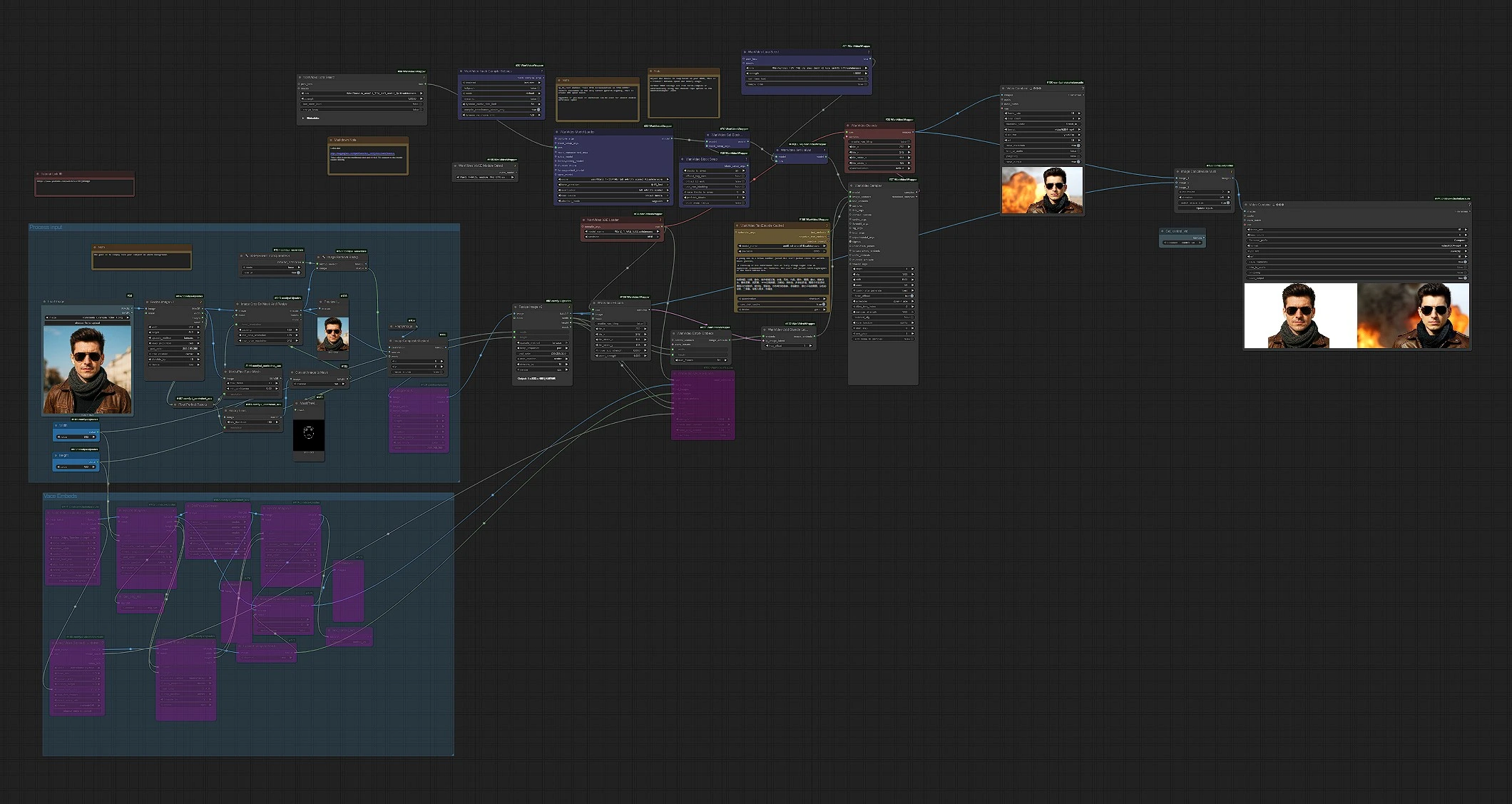
Traiter l'entrée (groupe)#
Commencez par une image bien éclairée et orientée vers l'avant sur un fond uni. Le pipeline charge votre image dans LoadImage (#58), standardise la taille avec ImageResizeKJv2 (#142), et crée un masque centré sur le visage à l'aide de MediaPipe-FaceMeshPreprocessor (#144) et BinaryPreprocessor (#151). Le fond est retiré dans TransparentBGSession+ (#127) et ImageRemoveBackground+ (#128), puis le sujet est composé sur une toile propre avec ImageCompositeMasked (#108) pour minimiser le saignement des couleurs. Enfin, ImagePadKJ (#129) et ImageResizeKJv2 (#68) alignent l'aspect pour la génération; le cadre préparé est encodé dans un latent via WanVideoEncode (#104).
Intégrations VACE (groupe facultatif)#
Si vous souhaitez un contrôle du mouvement à partir d'un clip existant, chargez-le avec VHS_LoadVideo (#161) et éventuellement un guide secondaire ou une vidéo alpha avec VHS_LoadVideo (#168). Les images passent par DWPreprocessor (#163) pour les indices de pose et ImageResizeKJv2 (#169) pour l'appariement des formes; ImageToMask (#171) et ImageCompositeMasked (#174) vous permettent de mélanger précisément les images de contrôle. WanVideoVACEEncode (#160) transforme ceux-ci en intégrations VACE. Ce chemin est facultatif; laissez-le intact lorsque vous souhaitez un mouvement dirigé par texte seul à partir de Wan 2.1.
Modèle, LoRAs et texte#
WanVideoModelLoader (#22) charge la base Wan 2.1 14B plus le Stand In LoRA pour que l'identité soit intégrée dès le départ. Les fonctionnalités de vitesse compatibles VRAM sont disponibles via WanVideoBlockSwap (#39) et appliquées avec WanVideoSetBlockSwap (#70). Vous pouvez attacher un adaptateur supplémentaire tel que LightX2V via WanVideoSetLoRAs (#79). Les prompts sont encodés avec WanVideoTextEncodeCached (#159), utilisant UMT5-XXL sous le capot pour un contrôle multilingue. Gardez les prompts concis et descriptifs; mettez l'accent sur les vêtements, l'angle et l'éclairage du sujet pour compléter l'identité Stand In.
Intégration d'identité et échantillonnage#
WanVideoEmptyEmbeds (#177) établit la forme cible pour les intégrations d'image, et WanVideoAddStandInLatent (#102) injecte votre latent de référence encodé pour porter l'identité dans le temps. Les intégrations combinées d'image et de texte alimentent WanVideoSampler (#27), qui génère une séquence vidéo latente à l'aide du planificateur et des étapes configurés. Après l'échantillonnage, les images sont décodées avec WanVideoDecode (#28) et écrites dans un MP4 dans VHS_VideoCombine (#180).
Vue de comparaison et exportation#
Pour un contrôle qualité instantané, ImageConcatMulti (#122) empile les images générées à côté de la référence redimensionnée pour que vous puissiez juger de la ressemblance image par image. VHS_VideoCombine (#74) enregistre cela comme un "Compare" MP4 séparé. Le flux de travail Wan2.1 Stand In produit donc une vidéo finale propre plus un contrôle côte à côte sans effort supplémentaire.
Nœuds clés dans le flux de travail Comfyui Wan2.1 Stand In#
WanVideoModelLoader(#22). Charge Wan 2.1 14B et applique le Stand In LoRA à l'initialisation du modèle. Gardez l'adaptateur Stand In connecté ici plutôt que plus tard dans le graphique pour que l'identité soit appliquée tout au long du chemin de débruitage. Associez-le avecWanVideoVAELoader(#38) pour le Wan-VAE correspondant.WanVideoAddStandInLatent(#102). Fusionne votre image de référence encodée en latent dans les intégrations d'image. Si l'identité dérive, augmentez son influence; si le mouvement semble trop contraint, réduisez-le légèrement.WanVideoSampler(#27). Le générateur principal. Les étapes de réglage, le choix du planificateur et la stratégie de guidage ont ici le plus grand impact sur le détail, la richesse du mouvement et la stabilité temporelle. Lorsque vous augmentez la résolution ou la longueur, envisagez d'ajuster les paramètres de l'échantillonneur avant de modifier quoi que ce soit en amont.WanVideoSetBlockSwap(#70) avecWanVideoBlockSwap(#39). Échange la mémoire GPU pour la vitesse en échangeant des blocs d'attention entre les appareils. Si vous voyez des erreurs de mémoire insuffisante, augmentez le déchargement; si vous avez de la marge, réduisez le déchargement pour une itération plus rapide.ImageRemoveBackground+(#128) etImageCompositeMasked(#108). Ceux-ci garantissent que le sujet est proprement isolé et placé sur une toile neutre, ce qui réduit la contamination des couleurs et améliore le verrouillage de l'identité Stand In à travers les images.VHS_VideoCombine(#180). Contrôle l'encodage, le taux d'images et le nommage des fichiers pour la sortie MP4 principale. Utilisez-le pour définir votre FPS et votre cible de qualité préférés pour la livraison.
Extras facultatifs#
- Utilisez une référence de face, uniformément éclairée sur un fond uni pour de meilleurs résultats. De petites rotations ou des occultations importantes peuvent affaiblir le transfert d'identité.
- Gardez les prompts concis; décrivez les vêtements, l'humeur et l'éclairage qui correspondent à votre référence. Évitez les descripteurs de visage conflictuels qui luttent contre le signal Wan2.1 Stand In.
- Si la VRAM est limitée, augmentez le swap de bloc ou réduisez d'abord la résolution. Si vous avez de la marge, essayez d'activer les optimisations de compilation dans la pile de chargement avant d'augmenter les étapes.
- Le Stand In LoRA n'est pas standard et doit être connecté au chargement du modèle; suivez le modèle dans ce graphique pour garder l'identité stable. Fichiers LoRA : Stand-In
- Pour un contrôle avancé, activez le chemin VACE pour diriger le mouvement avec un clip guide. Commencez sans si vous voulez un mouvement purement dirigé par texte à partir de Wan 2.1.
Resources
- Wan 2.1 14B T2V : Hugging Face
- Wan 2.1 VACE : Hugging Face
- Stand In LoRA : Hugging Face
- LightX2V Step-Distill LoRA : Hugging Face
- UMT5-XXL encoder : Hugging Face
- WanVideo wrapper nodes : GitHub
- KJNodes utilities used for resizing, padding, and masking : GitHub
- ControlNet Aux preprocessors (MediaPipe Face Mesh, DWPose) : GitHub
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources d'ArtOfficial Labs. Nous remercions chaleureusement ArtOfficial Labs et les auteurs de Wan 2.1 pour Wan2.1 Demo pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Resources#
- Wan 2.1/Wan2.1 Demo
- Docs / Release Notes: Wan2.1 Demo
Note: L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.


