
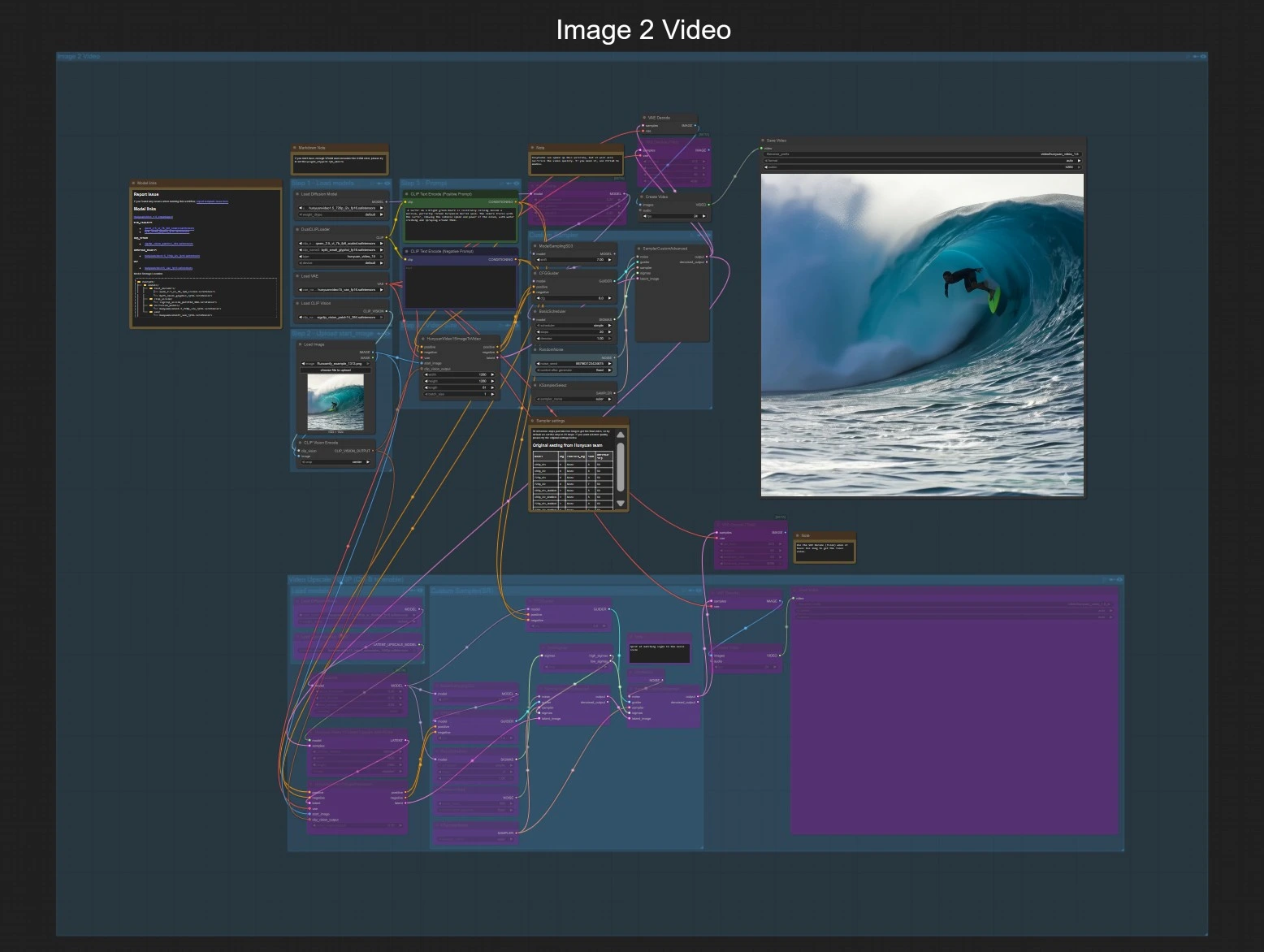
Workflow Hunyuan Video 1.5 ComfyUI: texte-à-vidéo et image-à-vidéo rapides avec super résolution 1080p#
Ce workflow enveloppe Hunyuan Video 1.5 dans ComfyUI pour offrir une génération vidéo rapide et cohérente sur les GPU grand public. Il prend en charge à la fois le texte-à-vidéo et l'image-à-vidéo, puis passe éventuellement à la 1080p en utilisant un upsampleur latent dédié et un modèle de super-résolution distillé. Sous le capot, Hunyuan Video 1.5 couple un Diffusion Transformer avec un VAE causal 3D et une stratégie d'attention par tuilage sélectif pour équilibrer qualité, fidélité de mouvement et vitesse.
Les créateurs, équipes produit et chercheurs peuvent utiliser ce workflow ComfyUI Hunyuan Video 1.5 pour itérer rapidement à partir de prompts ou d'une image fixe unique, prévisualiser en 720p, et terminer avec une sortie nette en 1080p si nécessaire.
Modèles clés dans le workflow Comfyui Hunyuan Video 1.5#
- HunyuanVideo 1.5 720p Image-à-Vidéo UNet. Produit du mouvement et de la cohérence temporelle à partir d'une image de départ. Les poids sont fournis dans le repackage Comfy-Org sur Hugging Face Comfy-Org/HunyuanVideo_1.5_repackaged.
- HunyuanVideo 1.5 720p Texte-à-Vidéo UNet. Génère des vidéos directement à partir de prompts textuels en utilisant la même architecture de base, optimisée pour les workflows axés sur les prompts. Voir le dépôt de repackage ci-dessus.
- HunyuanVideo 1.5 1080p Super-Résolution UNet (distillé). Affine les latents 720p à un détail plus élevé tout en préservant mouvement et structure de scène. Inclus dans le même repackage sur Hugging Face.
- HunyuanVideo 1.5 3D VAE. Encode et décode les latents vidéo pour une génération efficace et un décodage par tuiles.
- HunyuanVideo 1.5 Latent Upsampler 1080p. Redimensionne les séquences latentes à 1920×1080 avant le raffinement SR pour la rapidité et l'efficacité mémoire.
- Qwen 2.5 VL 7B encodeur de texte et ByT5 Small encodeur de texte. Fournissent un suivi d'instructions et une tokenisation robustes pour des prompts divers, reconditionnés pour ce workflow dans le bundle Hugging Face ci-dessus. Carte du modèle original de ByT5 : google/byt5-small.
- SigCLIP Vision (ViT-L/14, 384). Extrait des caractéristiques visuelles de haute qualité de l'image de départ pour guider le conditionnement image-à-vidéo : Comfy-Org/sigclip_vision_384.
Comment utiliser le workflow Comfyui Hunyuan Video 1.5#
Ce graphe expose deux chemins indépendants qui partagent le même stade d'exportation et de finition optionnel en 1080p. Choisissez soit Image à Vidéo soit Texte à Vidéo, puis activez éventuellement le groupe 1080p pour finaliser.
Image à Vidéo#
Étape 1 — Charger les modèles Les chargeurs importent le Hunyuan Video 1.5 UNet pour image-à-vidéo, le 3D VAE, les encodeurs de texte doubles et la vision SigCLIP. Cela prépare le workflow à accepter une image de départ unique et un prompt. Aucune action utilisateur n'est nécessaire au-delà de la confirmation que les modèles sont disponibles.
Étape 2 — Télécharger l'image de départ Fournissez une image propre et bien exposée dans LoadImage (#80). Le graphe encode cette image avec CLIPVisionEncode (#79) afin que Hunyuan Video 1.5 puisse ancrer le mouvement et le style à votre référence. Privilégiez les images qui correspondent approximativement à votre ratio d'aspect cible pour réduire le recadrage ou le remplissage.
Étape 3 — Prompt Écrivez votre description dans CLIP Text Encode (Positive Prompt) (#44). Utilisez le prompt négatif CLIP Text Encode (Negative Prompt) (#93) pour éviter les artefacts ou styles indésirables. Gardez les prompts concis mais précis sur le sujet, le mouvement et le comportement de la caméra.
Étape 4 — Taille et durée de la vidéo HunyuanVideo15ImageToVideo (#78) définit la résolution spatiale et le nombre de frames à synthétiser. Les séquences plus longues nécessitent plus de VRAM et de temps, commencez donc plus court et augmentez une fois que vous aimez le mouvement.
Échantillonnage personnalisé La pile de samplers (ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125)) contrôle la force de guidance, les étapes, le type de sampler et la graine. Augmentez les étapes pour plus de détail et de stabilité, et utilisez une graine fixe pour reproduire les résultats lors de l'itération sur les prompts.
Prévisualisation et sauvegarde La séquence latente est décodée avec VAEDecode (#8), encadrée dans une vidéo à 24 fps avec CreateVideo (#101), et écrite par SaveVideo (#102). Cela vous donne une prévisualisation rapide en 720p prête à être revue.
Finition 1080p (optionnelle) Basculez le groupe “Video Upscale 1080P” pour activer la chaîne de finition. L'upsampleur latent s'étend à 1920×1080, puis le UNet de super-résolution distillé affine les détails en deux phases. VAEDecodeTiled et une seconde paire CreateVideo/SaveVideo exportent le résultat 1080p.
Texte à Vidéo#
Étape 1 — Charger les modèles Les chargeurs récupèrent le Hunyuan Video 1.5 720p texte-à-vidéo UNet, le 3D VAE et les encodeurs de texte doubles. Ce chemin ne nécessite pas d'image de départ.
Étape 3 — Prompt Entrez votre description dans l'encodeur positif CLIP Text Encode (Positive Prompt) (#149) et ajoutez éventuellement un prompt négatif dans CLIP Text Encode (Negative Prompt) (#155). Décrivez la scène, le sujet, le mouvement et la caméra, en gardant un langage concret.
Étape 4 — Taille et durée de la vidéo EmptyHunyuanVideo15Latent (#183) alloue le latent initial avec votre largeur, hauteur et nombre de frames choisis. Utilisez cela pour définir combien de temps et quelle taille devrait avoir votre vidéo.
Échantillonnage personnalisé ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162), et SamplerCustomAdvanced (#166) collaborent pour transformer le bruit en une vidéo cohérente guidée par votre texte. Ajustez les étapes et la guidance pour échanger la vitesse pour la fidélité, et fixez la graine pour rendre les exécutions comparables.
Prévisualisation et sauvegarde Les frames décodées sont assemblées par CreateVideo (#168) et sauvegardées par SaveVideo (#167) pour une revue rapide en 720p à 24 fps.
Finition 1080p (optionnelle) Activez le groupe “Video Upscale 1080P” pour augmenter les latents à 1080p et affiner avec le UNet SR distillé. L'échantillonnage en deux étapes améliore la netteté tout en préservant le mouvement. Un décodeur par tuiles et une seconde étape de sauvegarde exportent la vidéo finale 1080p.
Nœuds clés dans le workflow Comfyui Hunyuan Video 1.5#
HunyuanVideo15ImageToVideo (#78) Génère une vidéo en se basant sur une image de départ et vos prompts. Ajustez sa résolution et le nombre total de frames pour correspondre à votre objectif créatif. Les résolutions plus élevées et les clips plus longs augmentent la VRAM et le temps. Ce nœud est central pour la qualité image-à-vidéo car il fusionne les caractéristiques CLIP-Vision avec les indications textuelles avant l'échantillonnage.
EmptyHunyuanVideo15Latent (#183) Initialise la grille latente pour texte-à-vidéo avec largeur, hauteur et nombre de frames. Utilisez-le pour définir la longueur de la séquence à l'avance afin que le scheduler et le sampler puissent planifier une trajectoire de débruitage stable. Gardez le ratio d'aspect cohérent avec votre sortie prévue pour éviter le remplissage supplémentaire plus tard.
CFGGuider (#129) Définit la force de guidance sans classifieur, équilibrant l'adhésion au prompt contre la naturalité. Augmentez la guidance pour suivre le prompt plus strictement; réduisez-la pour diminuer la sursaturation et le scintillement. Utilisez des valeurs modérées pendant la génération de base et une guidance plus faible pour le raffinement de super-résolution.
BasicScheduler (#126) Contrôle le nombre d'étapes de débruitage et le calendrier. Plus d'étapes signifient généralement un meilleur détail et stabilité mais des rendus plus longs. Associez le nombre d'étapes au choix de sampler pour de meilleurs résultats; ce workflow utilise par défaut un sampler rapide et polyvalent.
SamplerCustomAdvanced (#125) Exécute la boucle de débruitage avec votre sampler et guidance sélectionnés. Dans la chaîne de finition 1080p, il fonctionne en deux phases séparées par SplitSigmas pour d'abord établir la structure à un bruit plus élevé puis affiner les détails à faible bruit. Gardez les graines fixes tout en ajustant les étapes et la guidance pour pouvoir comparer les sorties de manière fiable.
HunyuanVideo15LatentUpscaleWithModel (#109) Redimensionne la séquence latente à 1920×1080 en utilisant l'upsampleur dédié des poids reconditionnés. L'upscaling dans l'espace latent est plus rapide et plus économe en mémoire que le redimensionnement en espace pixel, et il prépare le terrain pour que le modèle SR distillé ajoute des détails fins. Les cibles plus grandes demandent plus de VRAM; gardez 16:9 pour le meilleur débit.
HunyuanVideo15SuperResolution (#113) Affine le latent upscalé avec le UNet SR 1080p distillé du bundle Hunyuan Video 1.5, prenant éventuellement des indices d'image de départ et de CLIP-Vision pour la cohérence. Cela ajoute des textures nettes et un travail de ligne tout en maintenant le mouvement. Les poids SR sont disponibles dans Comfy-Org/HunyuanVideo_1.5_repackaged.
EasyCache (#116) Met en cache les états de modèle intermédiaires pour accélérer les itérations de prévisualisation. Activez-le lorsque vous souhaitez un retour plus rapide, et désactivez pour une qualité maximale sur votre passage final. Il est particulièrement utile lors de l'itération sur des prompts avec la même résolution et durée.
Extras optionnels#
- Gardez les prompts concrets. Décrivez le sujet, les verbes de mouvement et les mouvements de caméra. Utilisez un prompt négatif court pour supprimer les artefacts que vous voyez à plusieurs reprises.
- Privilégiez des images de départ propres et à fort contraste pour l'image-à-vidéo. Faites correspondre le ratio d'aspect à votre résolution cible pour minimiser le remplissage.
- Pour la vitesse, itérez à des durées plus courtes et en 720p; activez le groupe 1080p uniquement pour les exécutions finales.
- Si la VRAM est serrée, activez le décodage VAE par tuiles et envisagez de charger les poids dans un réglage de précision plus faible exposé par le chargeur de modèle.
- Fixez les graines pendant que vous ajustez les étapes, la guidance et le libellé pour rendre les changements mesurables à travers les exécutions.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy.org pour le tutoriel sur le workflow Hunyuan Video 1.5 pour leurs contributions et leur maintenance. Pour des détails autorisés, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Source Hunyuan Video 1.5
- Docs / Notes de version: Hunyuan Video 1.5 Source
Note: L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.
