
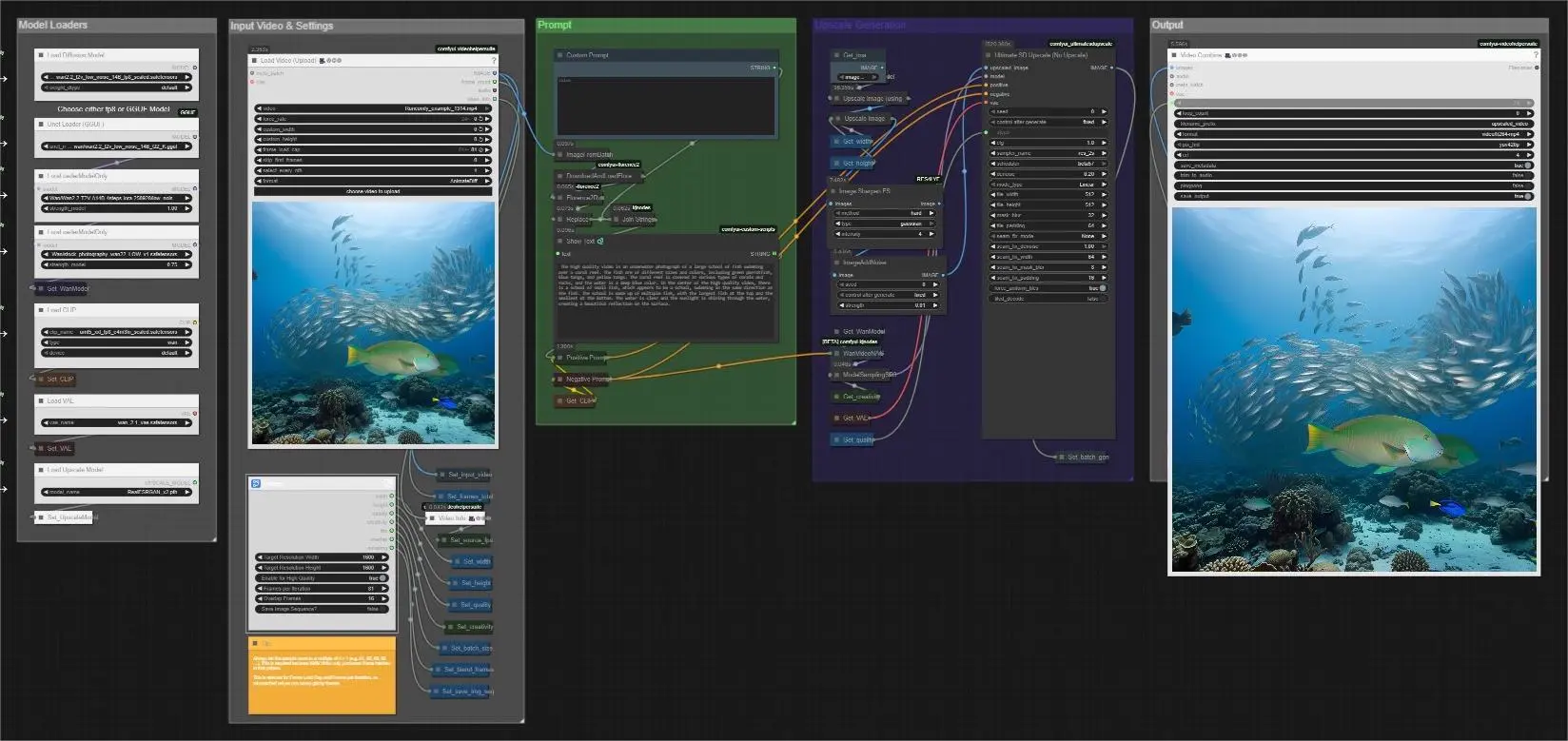
Facile Suréchantillonneur Vidéo pour Séquences#
Le Facile Suréchantillonneur Vidéo pour Séquences est un pipeline ComfyUI simplifié par Mickmumpitz qui améliore la clarté, la texture et la résolution perçue des vidéos existantes avec une configuration minimale. Il combine une super-résolution rapide, un affûtage respectueux des détails et un raffinement par diffusion Wan 2.x pour restaurer la structure fine tout en gardant le mouvement naturel. Que vous modernisiez des enregistrements d'archives, amélioriez des clips générés par AI ou prépariez des masters de livraison, le flux de travail Facile Suréchantillonneur Vidéo pour Séquences met l'accent sur la cohérence entre les images, les transitions fluides entre les lots et une sortie fiable.
Le flux de travail accepte une seule vidéo d'entrée, lit automatiquement son taux de trame, génère ou accepte une invite de guidage, et traite les images en lots fusionnables pour que les longues séquences restent homogènes. Vous pouvez choisir un modèle GGUF léger pour les systèmes à faible VRAM ou un UNet FP8 pour une fidélité maximale, puis orienter le raffinement avec un simple contrôle de créativité. Les résultats finaux sont enregistrés sous forme de vidéo suréchantillonnée, avec un chemin de séquence d'images en option pour les grands projets.
Modèles clés dans le flux de travail Facile Suréchantillonneur Vidéo pour Séquences de ComfyUI#
- Wan 2.2 T2V Low Noise 14B UNet (FP8 ou GGUF). Épine dorsale générative utilisée pour le raffinement basé sur la diffusion qui améliore les détails tout en respectant les images source. Hugging Face: Comfy-Org/Wan_2.2_ComfyUI_Repackaged et Hugging Face: bullerwins/Wan2.2-T2V-A14B-GGUF
- Wan 2.1 VAE. Décodeur qui préserve la texture et la tonalité lors du passage entre l'espace latent et l'espace pixel pendant le raffinement. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- UMT5-XXL text encoder (FP8). Épine dorsale textuelle utilisée pour le conditionnement de l'invite qui aligne les instructions avec le modèle WAN. Inclus dans les actifs reconditionnés Wan 2.1. Hugging Face: Comfy-Org/Wan_2.1_ComfyUI_repackaged
- RealESRGAN x2. Modèle de super-résolution classique qui augmente proprement la taille des images avant la récupération des détails basée sur la diffusion. GitHub: xinntao/Real-ESRGAN
- Microsoft Florence-2 Large. Modèle vision-langage utilisé ici pour auto-légender une image représentative, fournissant une invite de haute qualité lorsque vous ne souhaitez pas en écrire une. Hugging Face: microsoft/Florence-2-large
- Add-ons LoRA optionnels pour WAN 2.2. Adaptateurs légers qui peuvent orienter le raffinement vers des looks spécifiques sans écraser les séquences. Par exemple, le LoRA “Lightning” à faible bruit et 4 étapes. Hugging Face: lightx2v/Wan2.2-Lightning
Comment utiliser le flux de travail Facile Suréchantillonneur Vidéo pour Séquences de ComfyUI#
Le pipeline suit un chemin clair de l'entrée à la sortie et organise les commandes en groupes pour que vous sachiez toujours où ajuster la qualité, la vitesse et le comportement mémoire.
Chargeurs de Modèle#
Ce groupe initialise la pile de modèles principale et vous permet de choisir soit le UNet FP8 safetensors soit un UNet quantifié GGUF pour Wan 2.2. Utilisez le chemin GGUF lorsque la VRAM est limitée, ou le UNet FP8 lorsque vous souhaitez la plus haute fidélité. Le Wan 2.1 VAE et le UMT5-XXL text encoder sont chargés ici pour que les invites puissent guider l'étape de diffusion ultérieure. Si vous prévoyez d'utiliser un LoRA, chargez-le dans ce groupe avant de l'exécuter.
Vidéo d'Entrée & Paramètres#
Déposez votre clip source avec VHS_LoadVideo (#130). Le flux de travail lit le taux de trame source via VHS_VideoInfo (#298) pour que le rendu final corresponde à la cadence de mouvement. Définissez votre largeur et hauteur cibles, choisissez si vous souhaitez activer le mode haute qualité, et ajustez le contrôle de créativité pour décider à quel point le raffinement doit adhérer à votre entrée. Pour les longs clips, définissez les images par itération et une valeur de chevauchement pour fusionner les lots proprement, et activez l'option de sauvegarde de la séquence d'images lorsque vous souhaitez une stabilité maximale ou travaillez à très haute résolution.
Invite#
Vous pouvez taper une invite personnalisée ou laisser le flux de travail en créer une pour vous. Une seule image est échantillonnée et légendée par Florence2Run (#147), puis légèrement réécrite par StringReplace (#408) et fusionnée avec tout texte personnalisé via JoinStrings (#339). L'invite combinée est affichée par ShowText|pysssss (#135) et passée à Positive Prompt (#3), tandis que Negative Prompt (#4) contient des termes de réduction d'artefacts. Cela maintient les invites cohérentes et faciles à gérer, surtout pour les travaux par lots.
Génération de Suréchantillonnage#
Les images sont pré-suréchantillonnées avec ImageUpscaleWithModel (#303) utilisant RealESRGAN, puis redimensionnées précisément avec ImageScale (#454) à votre résolution cible. Image Sharpen FS (#452) restaure la netteté des bords si nécessaire et ImageAddNoise (#421) ajoute un petit bruit contrôlé qui aide le passage de diffusion à reconstruire une micro-texture réaliste. Le modèle WAN est préparé avec WanVideoNAG (#115) et ModelSamplingSD3 (#419), puis UltimateSDUpscaleNoUpscale (#126) effectue un raffinement guidé par invite et en tuiles qui respecte la structure globale et la continuité du mouvement.
Créateur de Lots + Fusion des Lots Générés#
Les longues vidéos sont automatiquement divisées en lots fusionnables. Ce sous-graphe calcule le nombre d'itérations, l'affiche dans “Number of Iterations,” et assemble chaque lot d'images tout en tenant compte de votre paramètre de chevauchement. Aux frontières entre les lots, ImageBatchJoinWithTransition (#244) mélange les images pour que la couture soit discrète. Utilisez plus de chevauchement lorsque les coupures sont évidentes, et réduisez-le pour accélérer les choses lorsque les scènes sont stables.
Séquence d'Images Enregistrée Fusionnée en Sortie#
Lorsque “Save Image Sequence” est activé, chaque itération écrit ses images sur le disque, ce qui est utile pour des résolutions très élevées ou une mémoire limitée. Le flux de travail recharge ensuite ces images avec VHS_LoadImagesPath (#396), fusionne éventuellement à nouveau les extrémités des lots et les assemble en une séquence continue. Ce chemin fournit une voie de récupération robuste si vous arrêtez et reprenez le traitement.
Sortie#
Les images finales sont compilées en une vidéo par VHS_VideoCombine (#128) en utilisant le taux de trame source capturé plus tôt, de sorte que le mouvement reste fluide et fidèle à l'original. Vous pouvez également émettre un aperçu intermédiaire ou écrire une seconde finale à partir du chemin de la séquence enregistrée en utilisant VHS_VideoCombine (#393). Les noms de fichiers et sous-dossiers sont auto-incrémentés pour garder chaque exécution bien rangée.
Nœuds clés dans le flux de travail Facile Suréchantillonneur Vidéo pour Séquences de ComfyUI#
VHS_LoadVideo (#130)#
Charge le clip d'entrée et expose les images, le nombre d'images et un blob video_info. Si vous avez l'intention de traiter seulement une partie, limitez le chargement des images dans le nœud et alignez les “Frames per Iteration” en conséquence. Garder les paramètres de chargeur et de lot synchronisés évite le bégaiement ou les lacunes lorsque les lots sont assemblés.
ImageUpscaleWithModel (#303)#
Applique RealESRGAN pour un boost de taille rapide et résistant aux artefacts avant la diffusion. Utilisez-le pour atteindre ou approcher votre résolution cible avant le raffinement afin que le passage WAN puisse se concentrer sur la texture et les détails fins au lieu d'un redimensionnement à grande échelle. Si votre source correspond déjà à la taille cible, vous pouvez toujours garder cette étape pour le débruitage et le renforcement de la structure.
UltimateSDUpscaleNoUpscale (#126)#
Exécute le raffinement par diffusion WAN en tuiles avec correction des coutures et décodage en tuiles optionnel pour préserver la structure globale. Les quelques contrôles qui comptent ici sont les étapes de l'échantillonneur, la force de débruitage et les options liées aux coutures; des étapes plus élevées et un débruitage produisent un aspect plus affirmé, tandis que des réglages plus bas s'en tiennent plus près de vos images originales. Lorsque vous activez la haute qualité dans le groupe Paramètres, ce nœud ajuste automatiquement la profondeur des étapes.
WanVideoNAG (#115) et ModelSamplingSD3 (#419)#
Cette paire connecte le modèle WAN à l'échantillonneur et expose un changement de créativité. Une créativité plus faible garde la sortie proche de l'entrée avec un léger enrichissement, tandis que des valeurs plus élevées ajoutent plus de texture générative et peuvent inventer des détails. Pour les documentaires, interviews ou travaux d'archives, préférez des valeurs conservatrices; pour les clips synthétiques ou d'origine AI, vous pouvez aller un peu plus loin.
ImageBatchJoinWithTransition (#244)#
Fusionne la fin d'un lot avec le début du suivant pour cacher les marques de couture. Augmentez le nombre d'images de transition lorsque vous remarquez des sauts de luminance ou de texture, et réduisez-le pour des exécutions plus rapides lorsque les scènes sont uniformes. C'est le principal levier qui maintient le pipeline Facile Suréchantillonneur Vidéo pour Séquences homogène sur de longues périodes.
VHS_VideoCombine (#128)#
Assemble la vidéo finale au fps source capturé en amont. Si vous avez enregistré des séquences d'images, vous pouvez passer au nœud de combinaison alternatif pour rendre à partir du disque sans retraitement. Ce nœud est également l'endroit où vous définissez le conteneur et le format de pixel si nécessaire.
Extras optionnels#
- Choisissez un chemin WAN. Utilisez UNet FP8 pour la meilleure qualité sur des GPU puissants, ou le UNet GGUF pour les stations de travail et les ordinateurs portables à faible VRAM.
- Gardez le mouvement naturel. Commencez avec une créativité faible pour les séquences d'action en direct ou les documentaires, puis augmentez progressivement si vous avez besoin de plus de récupération de texture.
- Planifiez les lots à l'avance. Sur les longs clips, activez “Save Image Sequence” pour pouvoir reprendre ou re-rendre le final sans recalculer la diffusion.
- Faites correspondre les mathématiques des images. Définissez les images par itération pour qu'elles s'alignent avec le cap de votre chargeur et le chevauchement; les outils de lot Facile Suréchantillonneur Vidéo pour Séquences calculeront les itérations et les bords de fusion pour vous.
- Utilisez LoRA avec parcimonie. Ajoutez un LoRA WAN 2.2 lorsque vous avez besoin d'un look spécifique, et réduisez son poids s'il commence à écraser le caractère original de la scène.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions sincèrement Mickmumpitz pour le flux de travail Facile Suréchantillonneur Vidéo pour Séquences pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- YouTube/Facile Suréchantillonneur Vidéo pour Séquences
- Docs / Notes de version: YouTube @ Mickmumpitz
Remarque : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et termes respectifs fournis par leurs auteurs et mainteneurs.
