
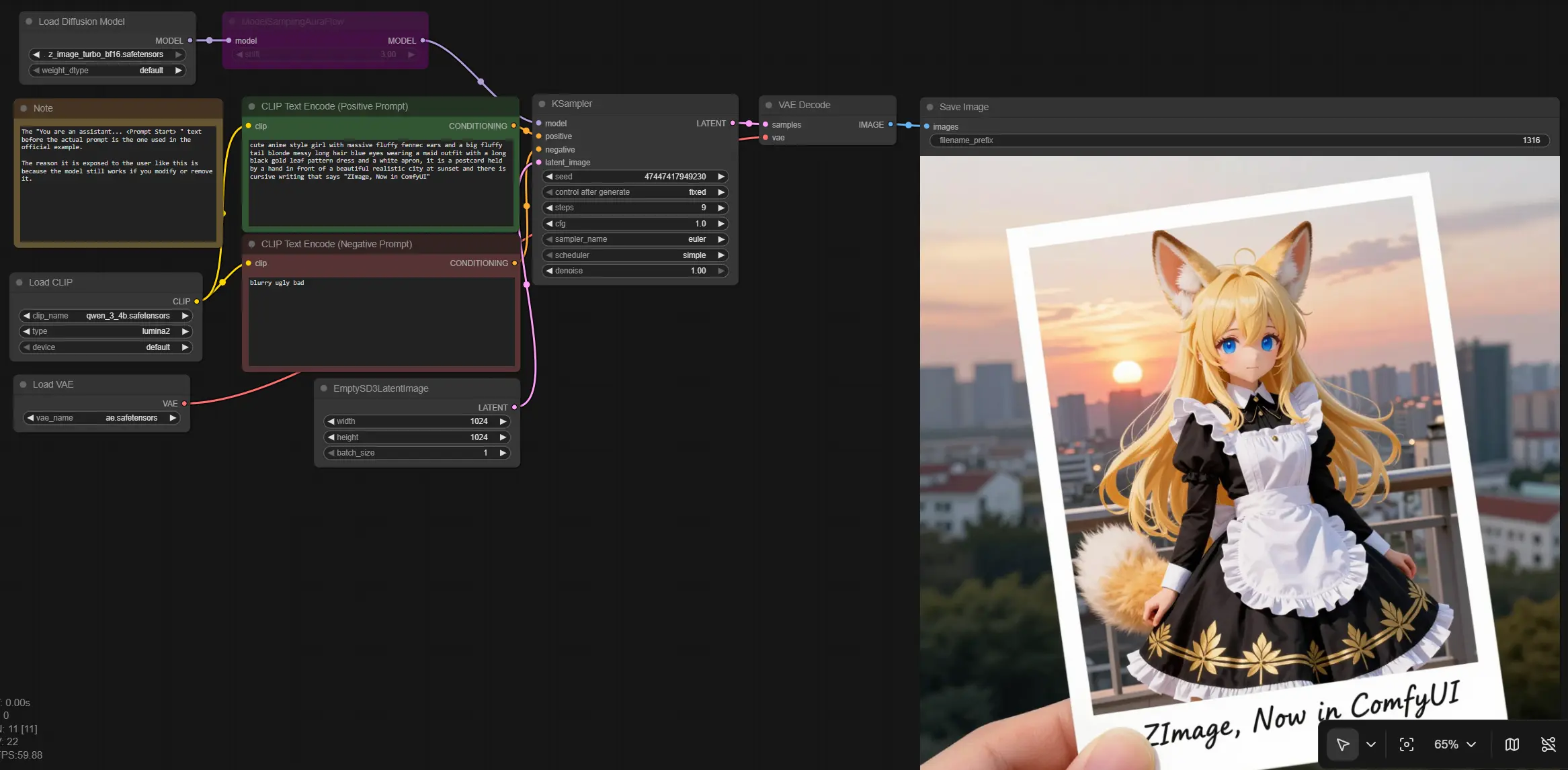







Z Image Turbo für ComfyUI: schneller Text-zu-Bild mit nahezu Echtzeit-Iteration#
Dieser Workflow bringt Z Image Turbo in ComfyUI, sodass Sie hochauflösende, fotorealistische Bilder mit sehr wenigen Schritten und enger Prompt-Beachtung erzeugen können. Er ist für Kreative gedacht, die schnelle, konsistente Renderings für Konzeptkunst, Werbekompositionen, interaktive Medien und schnelles A/B-Testing benötigen.
Der Graph folgt einem klaren Pfad von Text-Prompts zu einem Bild: Er lädt das Z Image-Modell und unterstützende Komponenten, kodiert positive und negative Prompts, erstellt eine latente Leinwand, sampelt mit einem AuraFlow-Zeitplan, und dekodiert dann zu RGB zum Speichern. Das Ergebnis ist eine optimierte Z Image-Pipeline, die Geschwindigkeit ohne Detailverlust bevorzugt.
Wichtige Modelle im Comfyui Z Image-Workflow#
- Tongyi-MAI Z Image Turbo. Der Hauptgenerator, der das Denoising auf eine destillierte, schritteffiziente Weise durchführt. Er zielt auf Fotorealismus, scharfe Texturen und getreue Komposition bei niedriger Latenz ab. Model card
- Qwen 4B Text-Encoder (qwen_3_4b.safetensors). Bietet Sprachkonditionierung für das Modell, sodass Stil, Subjekt und Komposition in Ihrem Prompt die Denoising-Trajektorie leiten.
- Autoencoder AE (ae.safetensors). Übersetzt zwischen latentem Raum und Pixeln, sodass das endgültige Z Image-Ergebnis betrachtet und exportiert werden kann.
Wie man den Comfyui Z Image-Workflow verwendet#
Auf hoher Ebene läuft der Pfad vom Prompt zur Konditionierung, durch Z Image-Sampling, dann Dekodierung zu einem Bild. Knoten sind in Stufen gruppiert, um den Betrieb einfach zu halten.
Modell-Loader: UNETLoader (#16), CLIPLoader (#18), VAELoader (#17)#
Diese Stufe lädt den Kern-Z Image Turbo-Checkpoint, den Text-Encoder und den Autoencoder. Wählen Sie den BF16-Checkpoint, wenn Sie ihn haben, da er Geschwindigkeit und Qualität für Verbraucher-GPUs ausbalanciert. Der CLIP-Stil-Encoder stellt sicher, dass Ihre Wortwahl die Szene und den Stil steuert. Der AE ist erforderlich, um Latents nach Beendigung des Samplings wieder in RGB zu konvertieren.
Prompting: CLIP Text Encode (Positive Prompt) (#6) und CLIP Text Encode (Negative Prompt) (#7)#
Schreiben Sie, was Sie im positiven Prompt möchten, unter Verwendung konkreter Nomen, Stilhinweise, Kamerahints und Beleuchtung. Verwenden Sie den negativen Prompt, um häufige Artefakte wie Unschärfe oder unerwünschte Objekte zu unterdrücken. Wenn Sie ein Prompt-Präfix wie eine Anleitungsüberschrift aus einem offiziellen Beispiel sehen, können Sie es behalten, bearbeiten oder entfernen, und der Workflow wird dennoch funktionieren. Zusammen erzeugen diese Encoder die Konditionierung, die Z Image während des Samplings lenkt.
Latent und Scheduler: EmptySD3LatentImage (#13) und ModelSamplingAuraFlow (#11)#
Wählen Sie Ihre Ausgabegröße, indem Sie die latente Leinwand festlegen. Der Scheduler-Knoten schaltet das Modell auf eine AuraFlow-Stil-Sampling-Strategie um, die gut zu schritteffizienten destillierten Modellen passt. Dies hält Trajektorien bei niedrigen Schrittzahlen stabil, während feine Details erhalten bleiben. Sobald Leinwand und Zeitplan festgelegt sind, ist die Pipeline bereit zum Denoisen.
Sampling: KSampler (#3)#
Dieser Knoten führt das eigentliche Denoising mit dem geladenen Z Image-Modell, dem ausgewählten Scheduler und Ihrer Prompt-Konditionierung durch. Passen Sie den Sampler-Typ und die Schrittzahl an, um bei Bedarf Geschwindigkeit gegen Details zu tauschen. Die Führungsskala steuert die Prompt-Stärke relativ zur vorherigen; moderate Werte bieten normalerweise die beste Balance zwischen Treue und kreativer Variation. Randomisieren Sie den Seed für die Erkundung oder fixieren Sie ihn für wiederholbare Ergebnisse.
Dekodieren und speichern: VAEDecode (#8) und SaveImage (#9)#
Nach dem Sampling dekodiert der AE Latents zu einem Bild. Der Speicherknoten schreibt Dateien in Ihr Ausgabeverzeichnis, sodass Sie Iterationen vergleichen oder Ergebnisse in nachgelagerte Aufgaben einspeisen können. Wenn Sie planen, hochzuskalieren oder nachzubearbeiten, behalten Sie die Dekodierung in Ihrer gewünschten Arbeitsauflösung und exportieren Sie verlustfreie Formate für die beste Qualitätsbewahrung.
Wichtige Knoten im Comfyui Z Image-Workflow#
UNETLoader (#16)#
Lädt den Z Image Turbo-Checkpoint (z_image_turbo_bf16.safetensors). Verwenden Sie dies, um zwischen Präzisionsvarianten oder aktualisierten Gewichten zu wechseln, sobald sie verfügbar sind. Halten Sie das Modell konsistent während einer Sitzung, wenn Sie möchten, dass Seeds und Prompts vergleichbar bleiben. Das Ändern des Basismodells wird Aussehen, Farbantwort und Detailliertheit ändern.
ModelSamplingAuraFlow (#11)#
Setzt die Sampling-Strategie auf einen AuraFlow-Stil-Zeitplan, der für schnelle Konvergenz geeignet ist. Dies ist der Schlüssel, um Z Image bei niedrigen Schrittzahlen effizient zu machen, während Detail und Kohärenz erhalten bleiben. Wenn Sie später Zeitpläne austauschen, überprüfen Sie die Schrittzahlen und die Führung, um ähnliche Ausgabecharakteristika zu erhalten.
KSampler (#3)#
Steuert den Sampler-Algorithmus, Schritte, Führung und Seed. Verwenden Sie weniger Schritte für schnelle Ideenfindung und erhöhen Sie nur, wenn Sie mehr Mikrodetails oder strengere Prompt-Beachtung benötigen. Verschiedene Sampler bevorzugen unterschiedliche Looks; probieren Sie ein paar aus und halten Sie den Rest der Pipeline fixiert, wenn Sie Ergebnisse vergleichen.
CLIP Text Encode (Positive Prompt) (#6)#
Kodiert die kreative Absicht, die Z Image antreibt. Konzentrieren Sie sich auf Subjekt, Medium, Linse, Beleuchtung, Komposition und alle Marken- oder Designbeschränkungen. Kombinieren Sie dies mit dem negativen Prompt-Knoten, um das Bild in Richtung Ihres Ziel-Looks zu steuern und bekannte Artefakte zu filtern.
Optionale Extras#
- Verwenden Sie quadratische oder nahezu quadratische Auflösungen für den ersten Durchgang und passen Sie dann das Seitenverhältnis an, sobald die Komposition festgelegt ist.
- Halten Sie eine Bibliothek wiederverwendbarer Prompt-Fragmente für Subjekte, Linsen und Beleuchtung bereit, um die Iteration über Projekte hinweg zu beschleunigen.
- Für konsistente künstlerische Ausrichtung fixieren Sie den Seed und variieren nur einen einzigen Faktor pro Iteration, wie z.B. Stil-Tag oder Kamerahint.
- Wenn die Ausgaben überkontrolliert wirken, reduzieren Sie die Führung leicht oder entfernen Sie zu restriktive Phrasen aus dem positiven Prompt.
- Beim Vorbereiten von Assets für die nachgelagerte Bearbeitung exportieren Sie verlustfreie PNGs und halten Sie eine Aufzeichnung von Prompt, Seed und Auflösung neben jedem Z Image-Render.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Tongyi-MAI für Z-Image-Turbo für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Tongyi-MAI/Z-Image-Turbo
- Hugging Face: Tongyi-MAI/Z-Image-Turbo
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartungsmitarbeitern bereitgestellt werden.