








Z Image ControlNet-Workflow für strukturgeführte Bildgenerierung in ComfyUI#
Dieser Workflow bringt Z Image ControlNet zu ComfyUI, sodass Sie Z‑Image Turbo mit präziser Struktur aus Referenzbildern steuern können. Es bündelt drei Leitmodi in einem Graphen: Tiefe, Canny-Kanten und menschliche Pose und lässt Sie zwischen ihnen wechseln, um Ihre Aufgabe anzupassen. Das Ergebnis ist eine schnelle, qualitativ hochwertige Text- oder Bild-zu-Bild-Generierung, bei der Layout, Pose und Komposition unter Kontrolle bleiben, während Sie iterieren.
Entwickelt für Künstler, Konzeptdesigner und Layoutplaner, unterstützt der Graph zweisprachige Eingaben und optionale LoRA-Stile. Sie erhalten eine saubere Vorschau des gewählten Kontrollsignals sowie einen automatischen Vergleichsstreifen, um Tiefe, Canny oder Pose mit dem endgültigen Ergebnis zu bewerten.
Schlüsselmodelle im Comfyui Z Image ControlNet-Workflow#
- Z‑Image Turbo Diffusionsmodell 6B Parameter. Primärer Generator, der schnell fotorealistische Bilder aus Eingaben und Kontrollsignalen erzeugt. alibaba-pai/Z-Image-Turbo
- Z Image ControlNet Union-Patch. Fügt Z‑Image Turbo eine Mehrfachbedingungskontrolle hinzu und ermöglicht Tiefe-, Kanten- und Pose-Leitlinien in einem Modell-Patch. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Erzeugt dichte Tiefenkarten, die für Strukturführung im Tiefenmodus verwendet werden. LiheYoung/Depth-Anything-V2 on GitHub
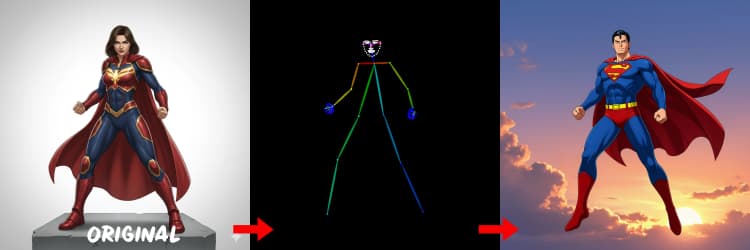
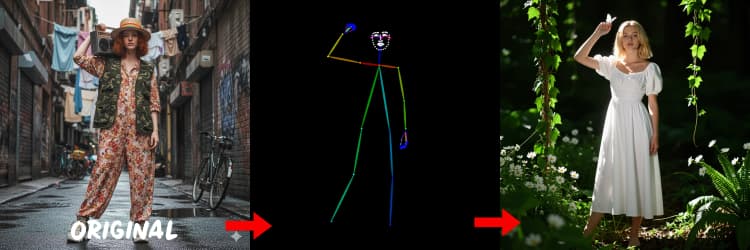
- DWPose. Schätzt menschliche Schlüsselpunkte und Körperpose für posegeführte Generierung. IDEA-Research/DWPose
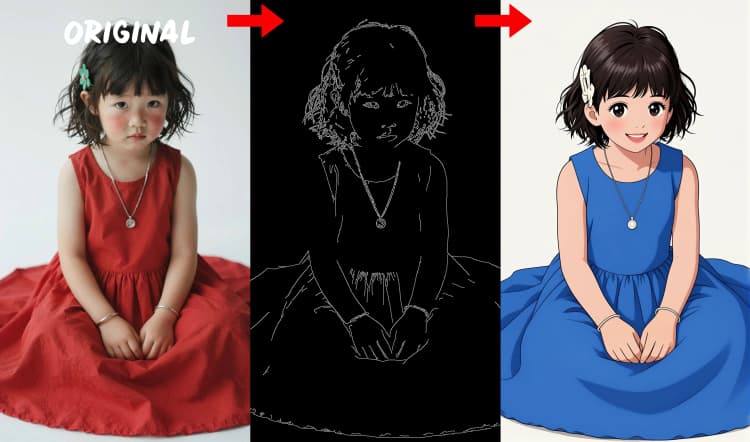
- Canny-Kantendetektor. Extrahiert saubere Linienzeichnungen und Grenzen für layoutgesteuerte Kontrolle.
- ControlNet Aux-Vorprozessoren für ComfyUI. Bietet einheitliche Wrapper für Tiefe, Kanten und Pose, die von diesem Graphen verwendet werden. comfyui_controlnet_aux
So verwenden Sie den Comfyui Z Image ControlNet-Workflow#
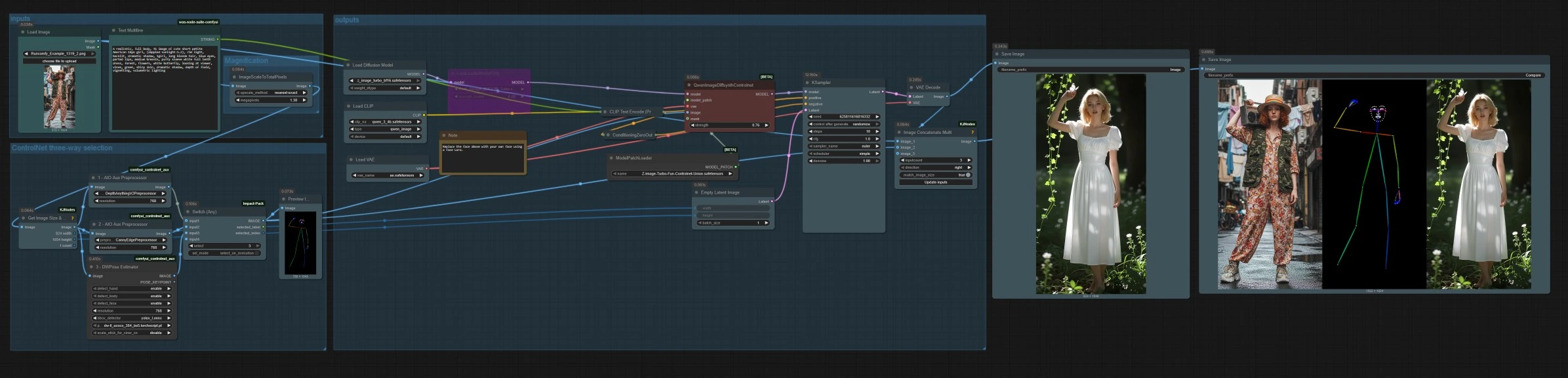
Auf hoher Ebene laden oder laden Sie ein Referenzbild hoch, wählen einen Kontrollmodus zwischen Tiefe, Canny oder Pose und generieren dann mit einem Texteingabe. Der Graph skaliert die Referenz für effizientes Sampling, erstellt ein Latent mit passendem Seitenverhältnis und speichert sowohl das endgültige Bild als auch einen Vergleichsstreifen nebeneinander.
Eingaben#
Verwenden Sie LoadImage (#14), um ein Referenzbild auszuwählen. Geben Sie Ihren Texteingabe in Text Multiline (#17) ein; der Z‑Image-Stack unterstützt zweisprachige Eingaben. Der Eingabe wird von CLIPLoader (#2) und CLIPTextEncode (#4) codiert. Wenn Sie eine rein strukturgetriebene Bild-zu-Bild-Erstellung bevorzugen, können Sie die Eingabe minimal halten und sich auf das ausgewählte Kontrollsignal verlassen.
ControlNet-Dreifachauswahl#
Drei Vorprozessoren konvertieren Ihre Referenz in Kontrollsignale. AIO_Preprocessor (#45) erzeugt Tiefe mit Depth Anything v2, AIO_Preprocessor (#46) extrahiert Canny-Kanten, und DWPreprocessor (#56) schätzt die vollständige Körperpose. Verwenden Sie ImpactSwitch (#58), um auszuwählen, welches Signal Z Image ControlNet antreibt, und überprüfen Sie PreviewImage (#43), um die gewählte Kontrollkarte zu bestätigen. Wählen Sie Tiefe, wenn Sie Szenengeometrie möchten, Canny für präzises Layout oder Produktaufnahmen und Pose für Charakterarbeit.
Tipps für OpenPose: 1. Beste für Ganzer Körper: OpenPose funktioniert am besten (~70-90% Genauigkeit), wenn Sie "ganzer Körper" in Ihre Eingabe aufnehmen. 2. Vermeiden bei Nahaufnahmen: Die Genauigkeit sinkt erheblich bei Gesichtern. Verwenden Sie Tiefe oder Canny (niedrige/mittlere Stärke) stattdessen für Nahaufnahmen. 3. Eingaben sind wichtig: Eingaben beeinflussen ControlNet stark. Vermeiden Sie leere Eingaben, um matschige Ergebnisse zu verhindern.
Vergrößerung#
ImageScaleToTotalPixels (#34) ändert die Größe der Referenz auf eine praktische Arbeitsauflösung, um Qualität und Geschwindigkeit auszugleichen. GetImageSizeAndCount (#35) liest die skalierte Größe und übergibt Breite und Höhe weiter. EmptyLatentImage (#6) erstellt ein latentes Canvas, das dem Seitenverhältnis Ihres skalierten Eingangs entspricht, sodass die Komposition konsistent bleibt.
Ausgaben#
QwenImageDiffsynthControlnet (#39) vereint das Basismodell mit dem Z Image ControlNet-Union-Patch und dem ausgewählten Kontrollbild, dann generiert KSampler (#7) das Ergebnis, das von Ihrer positiven und negativen Bedingung geleitet wird. VAEDecode (#8) konvertiert das Latent in ein Bild. Der Workflow speichert zwei Ausgaben: SaveImage (#31) schreibt das endgültige Bild und SaveImage (#42) schreibt einen Vergleichsstreifen über ImageConcatMulti (#38), der die Quelle, die Kontrollkarte und das Ergebnis für eine schnelle QA enthält.
Schlüsselnoten im Comfyui Z Image ControlNet-Workflow#
ImpactSwitch (#58)#
Wählt aus, welches Kontrollbild die Generierung antreibt: Tiefe, Canny oder Pose. Wechseln Sie die Modi, um zu vergleichen, wie jede Einschränkung die Komposition und Details formt. Verwenden Sie es beim Iterieren von Layouts, um schnell zu testen, welche Anleitung am besten zu Ihrem Ziel passt.
QwenImageDiffsynthControlnet (#39)#
Verbindet das Basismodell, das Z Image ControlNet-Union-Patch, die VAE und das ausgewählte Kontrollsignal. Der Parameter strength bestimmt, wie strikt das Modell dem Kontrollinput im Vergleich zur Eingabe folgt. Für enge Layoutanpassung erhöhen Sie die Stärke; für mehr kreative Variation reduzieren Sie sie.
AIO_Preprocessor (#45)#
Führt die Depth Anything v2-Pipeline aus, um dichte Tiefenkarten zu erstellen. Erhöhen Sie die Auflösung für detailliertere Strukturen oder reduzieren Sie sie für schnellere Vorschauen. Passt gut zu architektonischen Szenen, Produktaufnahmen und Landschaften, bei denen Geometrie wichtig ist.
DWPreprocessor (#56)#
Erzeugt Posenkarten, die für Menschen und Charaktere geeignet sind. Es funktioniert am besten, wenn Gliedmaßen sichtbar und nicht stark verdeckt sind. Wenn Hände oder Beine fehlen, versuchen Sie eine klarere Referenz oder einen anderen Rahmen mit mehr vollständiger Körperansicht.
LoraLoaderModelOnly (#54)#
Wendet ein optionales LoRA auf das Basismodell für Stil- oder Identitätshinweise an. Passen Sie strength_model an, um das LoRA sanft oder stark zu mischen. Sie können ein Gesichts-LoRA verwenden, um Subjekte zu personalisieren, oder ein Stil-LoRA, um einen bestimmten Look festzulegen.
KSampler (#7)#
Führt Diffusionssampling mit Ihrer Eingabe und Kontrolle durch. Passen Sie seed für Reproduzierbarkeit, steps für das Verfeinerungsbudget, cfg für die Eingabeanpassung und denoise an, um zu bestimmen, wie weit das Ergebnis vom anfänglichen Latent abweichen darf. Für Bild-zu-Bild-Bearbeitungen senken Sie den Denoise-Wert, um die Struktur zu erhalten; höhere Werte erlauben größere Veränderungen.
Optionale Extras#
- Um die Komposition zu straffen, verwenden Sie den Tiefenmodus mit einer sauberen, gleichmäßig beleuchteten Referenz; Canny bevorzugt starken Kontrast, und Pose bevorzugt Ganzkörperaufnahmen.
- Für subtile Bearbeitungen von einem Ausgangsbild halten Sie den Denoise bescheiden und erhöhen die ControlNet-Stärke für eine treue Struktur.
- Erhöhen Sie die Zielpixel in der Vergrößerungsgruppe, wenn Sie mehr Detail benötigen, und reduzieren Sie sie dann wieder für schnelle Entwürfe.
- Verwenden Sie die Vergleichsausgabe, um Tiefen vs. Canny vs. Pose schnell zu testen und die zuverlässigste Kontrolle für Ihr Motiv auszuwählen.
- Ersetzen Sie das Beispiel-LoRA durch Ihr eigenes Gesichts- oder Stil-LoRA, um Identität oder künstlerische Richtung ohne erneutes Training zu integrieren.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Alibaba PAI für Z Image ControlNet für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.


