
Wan2.2 S2V: Sound-to-Video von einem einzelnen Bild in ComfyUI#
Wan2.2 S2V ist ein Sound-to-Video-Workflow, der ein Referenzbild plus einen Audioclip in ein synchronisiertes Video verwandelt. Er basiert auf der Wan 2.2 Modellfamilie und ist für Kreative gedacht, die ausdrucksstarke Bewegungen, Lippen-Synchronisation und Szenendynamik möchten, die dem Klang oder der Sprache folgen. Verwenden Sie Wan2.2 S2V für sprechende Avatare, musikgesteuerte Loops und schnelle Story-Beats ohne Handanimation.
Dieser ComfyUI-Graph kombiniert Audio-Features mit Text-Prompts und einem Standbild, um einen kurzen Clip zu erzeugen, und muxiert dann die Frames mit dem Original-Audio. Das Ergebnis ist eine kompakte, zuverlässige Pipeline, die das Aussehen Ihres Referenzbildes bewahrt, während das Audio Timing und Ausdruck steuert.
Schlüsselmodelle im Comfyui Wan2.2 S2V-Workflow#
- Wan 2.2 S2V UNet (14B, bf16). Der Kern-Generator, der Audio-Features, Text-Konditionierung und ein Referenzbild fusioniert, um Video-Latents zu erzeugen.
- Wan VAE (wan_2.1_vae). Kodiert/decodiert zwischen latentem und Pixel-Raum, um Detail- und Farbtreue in Wan2.2 S2V-Renderings zu bewahren.
- UMT5-XXL Text-Encoder. Bietet Prompt-Konditionierung für Stil und Inhalt; siehe die Basis-Modellkarte zur Referenz: google/umt5-xxl.
- Wav2Vec2 Large Audio-Encoder. Extrahiert robuste Sprach- und Rhythmus-Features für sound-konditionierte Generierung; siehe eine archetypische Karte wie facebook/wav2vec2-large-960h.
Verwendung des Comfyui Wan2.2 S2V-Workflows#
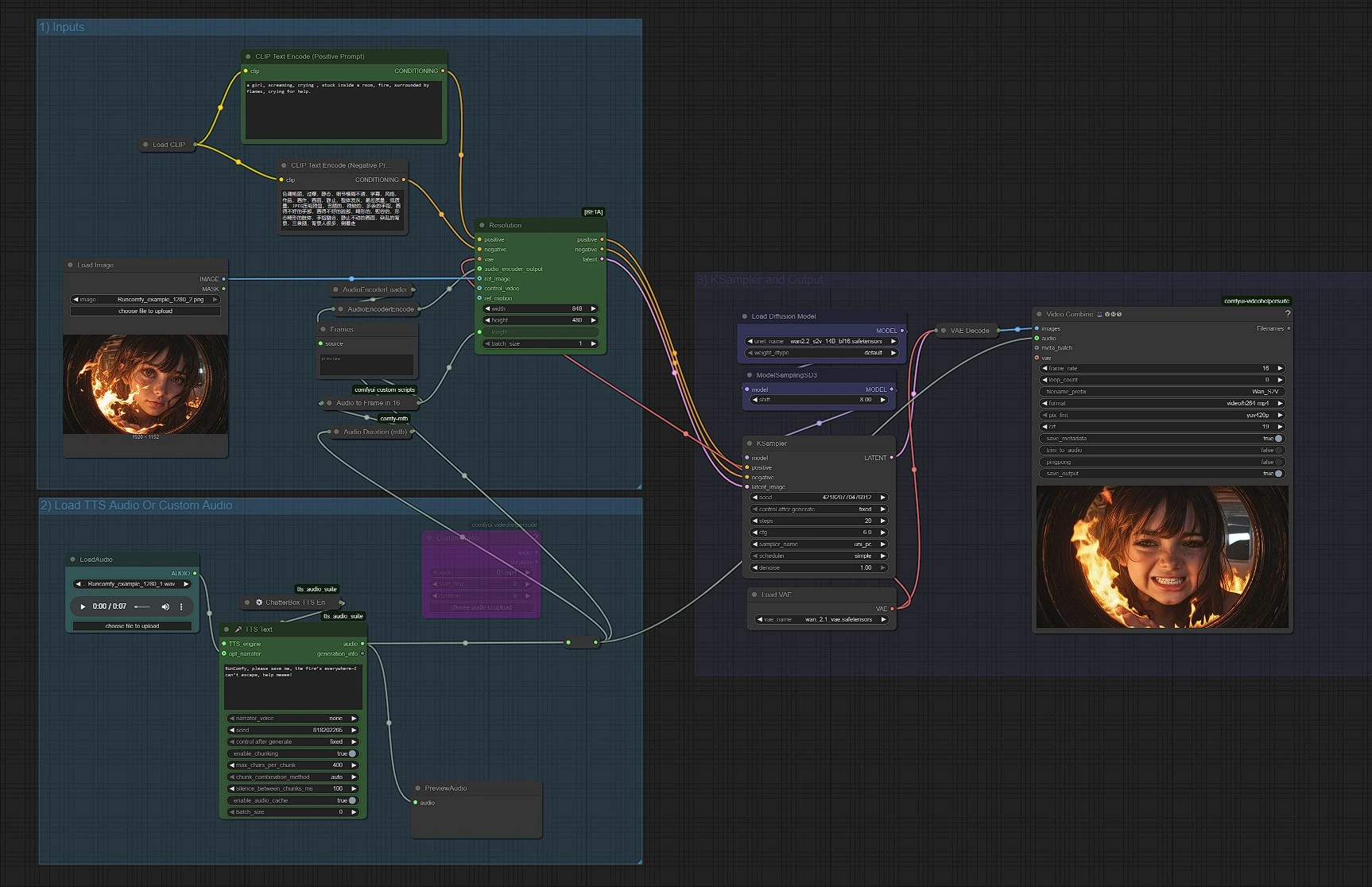
Der Workflow ist in drei Gruppen organisiert. Sie können sie durchgehend ausführen oder jede Phase nach Bedarf anpassen.
1) Eingaben#
Diese Gruppe lädt Wans Text-, Bild- und VAE-Komponenten und bereitet Ihre Prompts vor. Verwenden Sie CLIPLoader (#38) mit CLIPTextEncode (#6) für den positiven Prompt und CLIPTextEncode (#7) für den negativen Prompt, um Stil und Qualität zu steuern. Laden Sie Ihr Referenzbild mit LoadImage (#52); dies verankert Identität, Rahmung und Palette für Wan2.2 S2V. Halten Sie positive Prompts beschreibend, aber kurz, damit das Audio die Bewegung steuern kann. Der VAE (VAELoader (#39)) und der Modell-Lader (UNETLoader (#37)) sind vorverdrahtet und werden normalerweise belassen, wie sie sind.
2) TTS Audio oder benutzerdefiniertes Audio laden#
Wählen Sie aus, wie Sie Audio bereitstellen möchten. Für schnelle Tests erzeugen Sie Sprache mit UnifiedTTSTextNode (#71) und Vorschau mit PreviewAudio (#65). Um Ihre eigene Musik oder Ihren Dialog zu verwenden, entweder LoadAudio (#78) für lokale Dateien oder VHS_LoadAudioUpload (#87) für Uploads; beide speisen ein Reroute (#88), sodass nachgeschaltete Knoten eine einzige Audioquelle sehen. Die Dauer wird von Audio Duration (mtb) (#68) gemessen und dann von MathExpression|pysssss (#67) als „Audio zu Frame in 16 FPS“ in eine Frame-Anzahl umgewandelt. Die Audio-Features werden von AudioEncoderLoader (#57) und AudioEncoderEncode (#56) erzeugt, die zusammen dem Wan2.2 S2V-Knoten einen AUDIO_ENCODER_OUTPUT liefern.
3) KSampler und Ausgabe#
WanSoundImageToVideo (#55) ist das Herzstück von Wan2.2 S2V. Es verbraucht Ihre Prompts, VAE, Audio-Features, Referenzbild und eine length-Ganzzahl (Frames), um eine konditionierte latente Sequenz auszugeben. Diese latente Sequenz geht an KSampler (#3), dessen Sampler-Einstellungen die Gesamtkoherenz und Detailtreue steuern, während sie das Audio-gesteuerte Timing respektieren. Die gesampelte latente Sequenz wird von VAEDecode (#8) in Frames decodiert, dann setzt VHS_VideoCombine (#66) das Video zusammen und muxiert Ihr Original-Audio, um eine MP4 zu erzeugen. ModelSamplingSD3 (#54) wird verwendet, um die korrekte Sampler-Familie für das Wan-Backbone festzulegen.
Schlüssel-Knoten im Comfyui Wan2.2 S2V-Workflow#
WanSoundImageToVideo (#55)#
Steuert audio-synchronisierte Bewegungen von einem einzelnen Bild. Setzen Sie ref_image auf das Porträt oder die Szene, die Sie animieren möchten, verbinden Sie audio_encoder_output vom Encoder und geben Sie eine length in Frames an. Erhöhen Sie length für längere Clips oder reduzieren Sie sie für schnellere Vorschauen. Wenn Sie FPS woanders ändern, aktualisieren Sie den Frame-Wert entsprechend, damit das Timing synchron bleibt.
AudioEncoderLoader (#57) und AudioEncoderEncode (#56)#
Laden und führen Sie den Wav2Vec2-basierten Encoder aus, der Sprache oder Musik in Features umwandelt, denen Wan folgen kann. Verwenden Sie saubere Sprache für Lippen-Synchronisation oder perkussive/beatlastige Audio für rhythmische Bewegungen. Wenn Ihre Eingabesprache oder Domäne abweicht, tauschen Sie einen kompatiblen Wav2Vec2-Checkpoint aus, um die Ausrichtung zu verbessern.
CLIPTextEncode (#6) und CLIPTextEncode (#7)#
Positive und negative Prompt-Encoder für UMT5/CLIP-Konditionierung. Halten Sie positive Prompts kurz und konzentrieren Sie sich auf Thema, Stil und Shot-Begriffe; verwenden Sie negative Prompts, um unerwünschte Artefakte zu vermeiden. Zu starke Prompts können gegen das Audio arbeiten, also bevorzugen Sie leichte Führung und lassen Sie Wan2.2 S2V die Bewegung steuern.
KSampler (#3)#
Sampelt die latente Sequenz, die vom Wan2.2 S2V-Knoten erzeugt wird. Passen Sie den Sampler-Typ und die Schritte an, um Geschwindigkeit gegen Treue zu tauschen; behalten Sie einen festen Seed bei, wenn Sie reproduzierbares Timing mit dem gleichen Audio wünschen. Wenn die Bewegung zu starr oder rauschend wirkt, können kleine Änderungen hier die zeitliche Stabilität merklich verbessern.
VHS_VideoCombine (#66)#
Erstellt das endgültige Video und fügt das Audio an. Stellen Sie frame_rate ein, um Ihrem beabsichtigten FPS zu entsprechen und bestätigen Sie, dass die Clip-Länge mit Ihren length-Frames übereinstimmt. Der Container, das Pixelformat und die Qualitätskontrollen sind für schnelle Exporte offen; verwenden Sie höhere Qualität, wenn Sie in einem Editor nachbearbeiten möchten.
Optionale Extras#
- Beginnen Sie mit einem gut beleuchteten, frontalen Referenzbild im Ziel-Seitenverhältnis, um Identitätsdrift und Beschneidung zu minimieren.
- Für Lippen-Synchronisation halten Sie den Mund frei und verwenden Sie saubere Erzählungen; Musik mit starken Transienten eignet sich gut für beatgesteuerte Bewegungen.
- Die Standard-FPS-Konvertierung geht von 16 fps aus; wenn Sie FPS ändern, aktualisieren Sie die Mathematik in „Audio zu Frame in 16 FPS“, damit die Frames mit der Audio-Dauer übereinstimmen.
- Verwenden Sie die Audio-Vorschau und die VHS-Live-Vorschau, um schnell zu iterieren, und erhöhen Sie dann die Qualität, sobald Ihnen das Timing gefällt.
- Längere Clips skalieren Rechenleistung und VRAM; kürzen Sie Stille oder teilen Sie lange Skripte in kurze Szenen auf, wenn Sie Multi-Shot-Videos mit Wan2.2 S2V produzieren.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Wan-Video für Wan2.2 (einschließlich S2V Inferenzcode), Wan-AI für Wan2.2-S2V-14B und Gao et al. (2025) für Wan-S2V: Audio-Driven Cinematic Video Generation für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Audio-Driven Cinematic Video Generation
- Docs / Release Notes: Wan2.2 S2V Demo
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.